- AWS Builder Center›
- builders.flash
はじめに
千株式会社 ものづくり部コンシューマー開発グループの目賀田です。 保育園・幼稚園・学校の写真撮影・販売をトータルでサポートするインターネット写真サービスを提供する「はいチーズ!フォト」の、保護者様向け写真販売サイトの開発・運用を担当しています。
はいチーズ! フォトの写真販売サイトには、お子様の通う園・学校の年間行事実施に合わせて大きなトラフィックが発生します。 それに合わせてサービスにかかる負荷が高くなり、ユーザー体験を大きく損ねるような障害が起きていました。
そこで、ユーザーの体験を守るため、また、もしユーザーの体験を損ねた場合もすぐにリカバーできるようにするため、カスタマーサポートチームと連携して SLI/SLO を設定し、約1年ほど運用しています。
この記事では「はいチーズ!フォト」の写真販売サイトにおける、SLI/SLO の導入と運用について紹介します。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
サービス概要
ユーザーがアクセスする画面の構成図になります。 今回、後述するクリティカルユーザージャーニーに含まれていない機能については構成図中から省略していますが、ユーザーが利用する大多数の機能は下記の構成図のリソースで提供されています。
SLI/SLO 導入の経緯
元々のサービス体験の監視方法は
- CPU 使用率、メモリ使用率などのメトリクスを見て異常があればアラートを通知する
- Amazon Cloudwatch Logs や Amazon OpenSearch Service でアプリケーションログをフィルターし、特定のログが出力されたらアラートを通知する
- 特定のパスに対して定期的にリクエストを送信し、正常なレスポンスがなければアラートを通知する
というもので、このアラートを検知し、開発者が実際に本番環境にアクセスして異常箇所を特定する、という運用がされていました。
しかし、この運用は事前に開発者が想定しているエラーや体験の劣化しか検知することができません。 事実、アラートが通知されなかった時間においても、ユーザーからはページが重い、写真が購入できなかった、などの問い合わせが発生していました。
そこでユーザーの体験ベースで意味のあるアラート運用を実施するために、
- Amazon Managed Service for Grafana を用いた SLI/SLO ダッシュボード・アラートの構築
- OpenTelemetry をアプリケーションに導入し、Loki、Tempo を利用したオブザーバビリティの向上
を行いました。 これらは、以下のようにユーザーアクセスのあるサービスとは分離して構築されています。
アーキテクチャ図
SLO を仮設定し、運用を開始
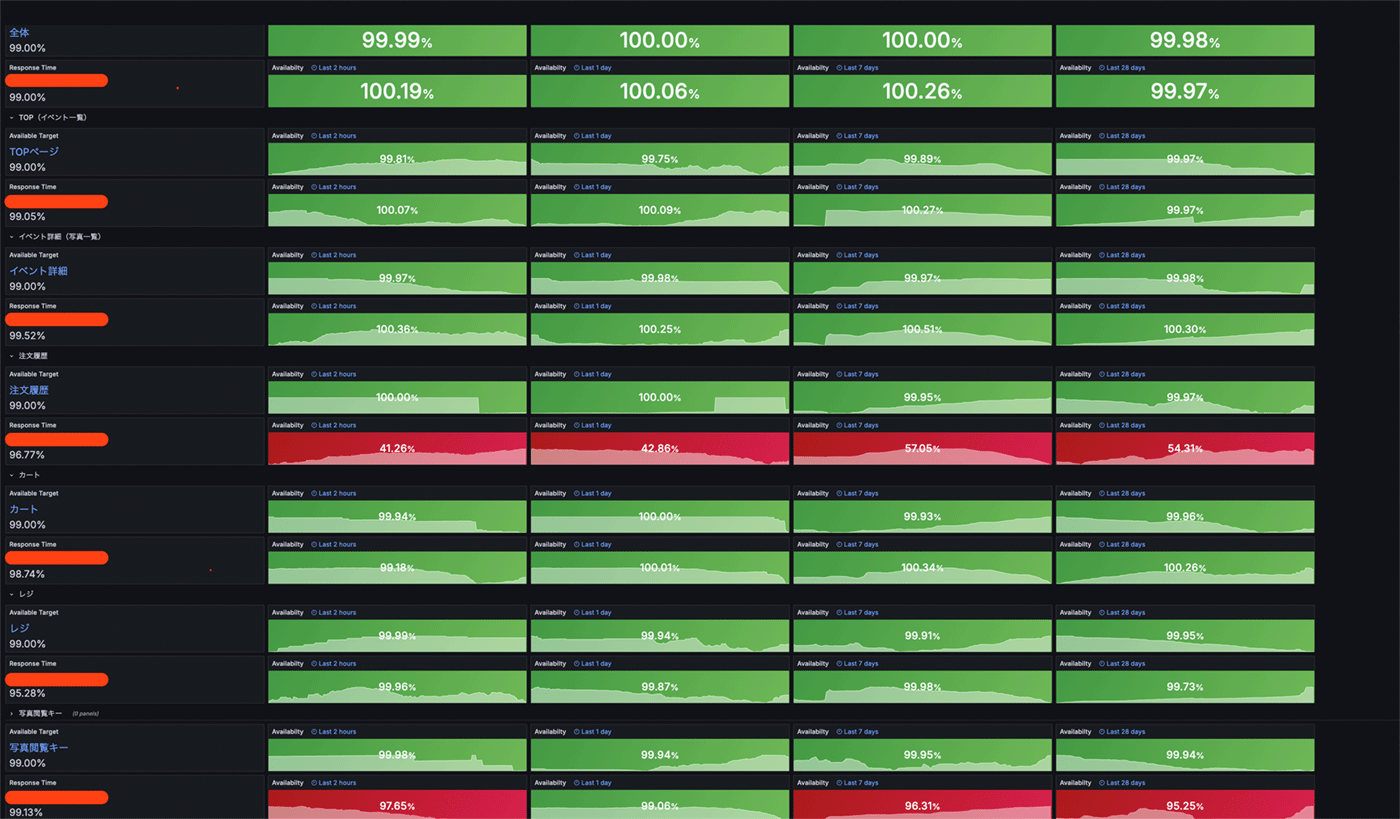
そして、これらのSLIの現状をしばらく計測したのち、実現可能なSLOを後々の修正前提で仮で設定し、運用を開始しました。 また、SLOのダッシュボードにアラート機能を設定することで、クリティカルユーザージャーニー上の機能に問題が発生したときに、開発者がすぐに問題箇所に気づけるようにしています。 このアラートは厳密なバーンレートアラートではありませんが、似たような設定で、2時間、1日、7日、28日の期間でそれぞれ計測するようにし、急激なSLOの悪化と長期的な悪化、それぞれに対応できるようにしています。 設定したSLI/SLOダッシュボードが、こちらになります。
このダッシュボードを定期的に確認しながら、SLOの指標の見直しや、悪化している機能のパフォーマンス・品質改善などに取り組んでいます。

SLO 運用の現状とこれから
SLO の運用を始めてから半年が経ち、導入によってできるようになったことと、現状の SLO 運用の課題が見えてきています。
できるようになったこと、変わったこととしては、
- 仮バーンレートアラートでパフォーマンス劣化を可視化したことで、開発者が該当機能のパフォーマンスチューニングに興味を持つようになった
- 今どの機能がどんな状況か容易にわかるようになった
- リリース後のユーザー影響が可視化されている
などがあります。 一方で、課題としては、
- バーンレートアラートの運用が完璧に運用できていない
- 開発者だけで SLO の見直しは負担が大きい
などが見つかっています。
特に、仮バーンレートアラートとして可視化したことによって開発者が現状のユーザー体験について興味を持つようになったのは重要な出来事でした。 ただ、最初は SLO の悪化はするものの原因特定はなかなかできない状態でした。 そこで OpenTelemetry を導入してトレースの計装とログとトレースの紐付けを行い、原因特定を容易にしました。 実際に計装したトレースを見てみると N+1 が発生して膨大な数のクエリが投げられている処理が発生している状況が可視化されました。
パフォーマンス改善の効率も向上
オブザーバビリティ向上の甲斐もありパフォーマンス改善の効率も上がって、カート機能のレイテンシの SLO が 91%→99% にまで改善しています。 仮にでも SLO を設定してダッシュボードで可視化することによって、SLO 導入時と比べると大幅なユーザー体験の改善を実現することができました。
まとめ
以上が弊社が行っている SLI/SLO の取り組みとその現状でした。 SLI/SLO の可視化とオブザーバビリティ向上によって問題の発見と原因特定までが実現できる状態になります。
これから導入してみようという方は、以下の 4 点を意識して取り組んでもらうとスムーズに進められるかもしれません。
- SLI/SLO はクリティカルユーザージャーニー、SLI 、SLO の順に設定するとスムーズに決まる
- クリティカルユーザージャーニーはユーザーに近い部署と連携して選定すると意味のあるものにしやすい
- SLO はどんなに低い数字になっても、現時点で実現可能な SLO を設定する
- 設定した SLO に対して、完璧でなくてもいいのでバーンレートアラートを設定すると、開発者に対する改善の動機づけになる
- オブザーバビリティは SLO 悪化の原因特定に貢献する
参考にしていただけると幸いです。
筆者プロフィール
目賀田 裕人 (@MegataYuto)
千株式会社 ものづくり部 コンシューマー開発グループ
2022 年に千株式会社に入社。 「はいチーズ!フォト」の写真販売サイトの開発や社内の SRE プラクティスの導入活動を行っている。
