- AWS Builder Center›
- builders.flash
Amazon Bedrock Knowledge Bases + AWS CDK で作る社内向け RAG テンプレート ~ コマンド 1 つで社内展開
2025-11-04 | 森本 康太 (ダイキン工業株式会社), 五十嵐 悠生 (ダイキン工業株式会社)
はじめに
こんにちは。ダイキン工業株式会社の森本と五十嵐です。森本は、空調に特化した LLM の開発や、生成 AI を用いたシステムの Proof of Concept (PoC) など、社内での生成 AI 活用に取り組んでいます。五十嵐は、テクノロジーイノベーション・センター (TIC) において、生成 AI を用いたシステムの PoC や、開発プロセスへの生成 AI 活用検証などに取り組んでいます。
本記事では、Amazon Bedrock Knowledge Bases を活用した社内向けの Retrieval-Augmented Generation (RAG) テンプレートを、二人三脚で作成した事例を紹介します。
AWSの公式メッセージ から引用 すると、RAG は以下のように定義されます。
検索拡張生成 (RAG) は、大規模な言語モデルの出力を最適化するプロセスです。そのため、応答を生成する前に、トレーニングデータソース以外の信頼できる知識ベースを参照します。
RAG は、LLM の既に強力な機能を、モデルを再トレーニングすることなく、特定の分野や組織の内部ナレッジベースに拡張します。LLM のアウトプットを改善するための費用対効果の高いアプローチであるため、さまざまな状況で関連性、正確性、有用性を維持できます。
ここでいうナレッジベースは、Amazon Bedrock Knowledge Bases を使うことで、簡単に構築できます。
しかし、これをアプリケーションとして利用するには、フロントエンド、バックエンド、認証機能など、多岐にわたる要素の開発が必要になります。そこで、私たちはこれらの開発負担を軽減するため、社内向けに RAG を利用したチャットボットのテンプレートを作成しました。
本テンプレートは、当時 (2023 年)、Amazon Kendra をベースに作成していた時代の Generative AI Use Cases (通称 GenU) を参考にして作成しています。
本記事では、テンプレートに対して行った以下の 3 つの工夫や、社内でテンプレートを普及させる中で分かったことを紹介します。
1. 簡単デプロイ : コマンド 1 つで全てのリソースをデプロイ可能
2. メタデータの自動付与 & アクセス制御 : AWS が不慣れな方によるセキュリティ事故を防ぐため、複雑な権限付与手順を自動化
3. データの前処理 : 製造業ならではの複雑な文書形式に対応できる、Foundation models as a parser
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
RAG テンプレートの構築背景とプロセス
本節では、弊社内で RAG テンプレートを構築した背景と、その具体的な構築プロセスについて説明します。
なぜ社内向け RAG テンプレートを構築したのか
弊社内では生成 AI 活用の機運が高まっており、特に自社の知識やデータと組み合わせて活用したいというニーズが、IT 系/非 IT 系を問わず多くの部門から上がっています。こういったニーズを実際のシステムに落とし込むのは、RAG の実装はもちろん、インフラ構築から認証機能など幅広い分野の実装が必要です。特に非 IT 系の部門にとっては難しいものです。
現場が本当に検証したいのは「RAG で業務が改善できるか」という点なのに、その前段階のシステム構築に膨大な時間を取られてしまう。これは本質的な課題ではありません。
これを解決するため、素早く PoC を開始でき、価値が確認できたらそのまま本番運用に移行できる RAG テンプレートを作ることにしました。
どのように構築したのか
作成に当たっては、「社内で使われるシステム」を重視し進めました。
始めた当初、ニーズがあったことは確実でしたがどういった使われ方をするのかは明確ではありませんでした。そこで、各部署に β 版のテンプレートを一斉公開し、試行錯誤して得たナレッジをテンプレートにフィードバックする開発形式を取りました。
これにより社内全体の知見が集約され、現在はそのままの状態でもニーズの大部分を満たし、最小限のカスタムで迅速にデプロイできるものとなりました。
システムの全体像
本テンプレートのアーキテクチャ図を示します。
主要部分の概要
- フロントエンド: React SPA を Amazon CloudFront + Amazon Simple Storage Service (Amazon S3) 上で配信
- 認証 : Amazon Cognito (MFA)
- API : Amazon API Gateway + AWS Lambda によって Amazon DynamoDB から会話履歴を取得、回答生成は Lambda のストリームレスポンス
- RAG : 回答生成には Amazon Bedrock Knowledge Bases を使用。 ベクトルストアとして Amazon Aurora Serverless (PostgreSQL) を、ドキュメントの格納先に Amazon S3 を、それぞれ採用
今回の RAG テンプレートでは、主なユースケースとして社内の部署単位で使われるチャットボットを想定しています。
このため、基本的にはコスト面を意識し、ゼロスケールするサーバレスサービス(Amazon Aurora Serverless など)を多用した構成になっています。
また、これらの構成は AWS Cloud Development Kit (AWS CDK) により IaC 化をし、社内のコードリポジトリにて配布されているため、部署の垣根なく使用できます。
テンプレートの特徴
弊社は製造業ということもあり、RAG を利用した社内情報チャットボットは、以下の要求を満たす必要があります。
- 想定ユーザーの AWS に対する習熟度にバラツキがあるため、簡単に行える構築手順が必要
- データソースとして扱う文書に製造業特有の内容・形式のものが多数存在するため、簡単に Knowledge Bases に読み込ませる工夫が必要
そこで、本テンプレートではいくつかの工夫を行なっています。ここからは、それらの内容について解説します。
工夫その 1:コマンド 1 つで全てのリソースをデプロイ可能
本テンプレートは、フロントエンドのビルドも含め全てが以下のコマンドで完結するようになっています。
npm run deployRAG の構成パターン切り替え
そのため、構築時の認知負荷が少なく簡単な手順で構築が可能になっています。また、RAG の構成パターンは複数ありますが、それらについても以下のようなコマンドの切り替えで問題なく動作します。
npm run deploy # Amazon Bedrock Knowledge Bases パターン
npm run deploy:Kendra # Amazon Bedrock + Amazon Kendra パターン
# その他パターン (本記事では割愛)エントリーポイントの切り替え
基本的なコンストラクトは共通のまま、--app オプションを用いてエントリーポイントを以下のように切り替えることで実現しています。
// package.json
{
...
"scripts": {
"deploy": "npx -w @reference-architecture-rag/cdk cdk deploy --all", // Bedrock Knowledge Bases パターン(デフォルト)
"deploy:Kendra": "npx -w @rag-template/cdk cdk deploy --app \"npx ts-node bin/aws-rag-template.ts\" --all", // Bedrock + Kendra パターン
// その他パターンのデプロイコマンド
},
...
}また、フロントエンドのデプロイには、AWS Solutions Constructs の `aws-cloudfront-s3` を用いています。
これは、React アプリの S3 バケットへのアップロード、CloudFront のディストリビューション設定などをベストプラクティスを守りながら簡単に構築できるものです。
こういった L3 コンストラクトを適切に用いることで、デプロイの自動化をしつつ、 IaC コードのメンテナンスコストを下げることが可能になります。
工夫その2:メタデータの自動付与 & アクセス制御
RAG テンプレートを作成していく中で、ユーザの所属によってアクセスできる文書・データソースを変えたいという声が多数ありました。
Bedrock Knowledge Bases には、メタデータによるフィルタ機能 があり、それを用いてアクセス制御を実現できます。
しかし、この手順を運用する上では、以下の懸念がありました。
- AWS にある程度習熟した方しかメタデータ付与が行えず、運用が属人化する
- 不慣れな方がメタデータを付与した結果、本来閲覧できないはずの情報へアクセスできる状態になってしまう
このため、テンプレートには Amazon SQS + AWS Lambda でメタデータを自動付与するパイプラインを組み込むことにしました。このパイプラインと、Cognito ユーザープールの所属情報を連携させることで、各グループにそれぞれ対応するディレクトリのデータのみを用いた回答生成が可能になります。
パイプラインの構成イメージ
本パイプラインの構成イメージは以下です。
処理後のドキュメントのイメージ
アップロード用のバケットにオブジェクトがアップロードされると、そのディレクトリ構成に対応したメタデータが作成されるようになっています。以下が、処理後のドキュメントのイメージです。
# Bedrock Knowledge Bases 用 のデータソースバケット
docs/
├── General/ # 全員がアクセスできる
├── A/ # グループ A のみアクセスできる
│ ├── manual.pdf # Input バケットからコピー
│ └── manual.metadata.pdf # Lambda で自動生成
├── B/ # グループ B のみアクセスできる
└── ...回答生成時のフィルタリング
このメタデータと、 ユーザーのトークンから得られる所属情報を用いて、Knowledge Bases での回答生成時にフィルタをかけます。
const filter: RetrievalFilter = {
equals: {
key: 'directory',
value: targetDirectory,
},
}
const command = new RetrieveAndGenerateStreamCommand({
retrieveAndGenerateConfiguration: {
type: 'KNOWLEDGE_BASE',
KnowledgeBaseConfiguration: {
retrievalConfiguration: {
vectorSearchConfiguration: {
filter: filter, // ここでフィルタ
},
},
// その他パラメータ
},
},
})これにより、ユーザープールの所属に対応した、アクセス制御が可能となります。
また、これらを自動化することにより、ユーザー側の負荷が少なく運用可能となります。
フィルタ処理のイメージ
以下が、フィルタ処理のイメージです。
工夫その3:データの前処理 (Foundation models as a parser)
図表の多いリッチなドキュメントを使用
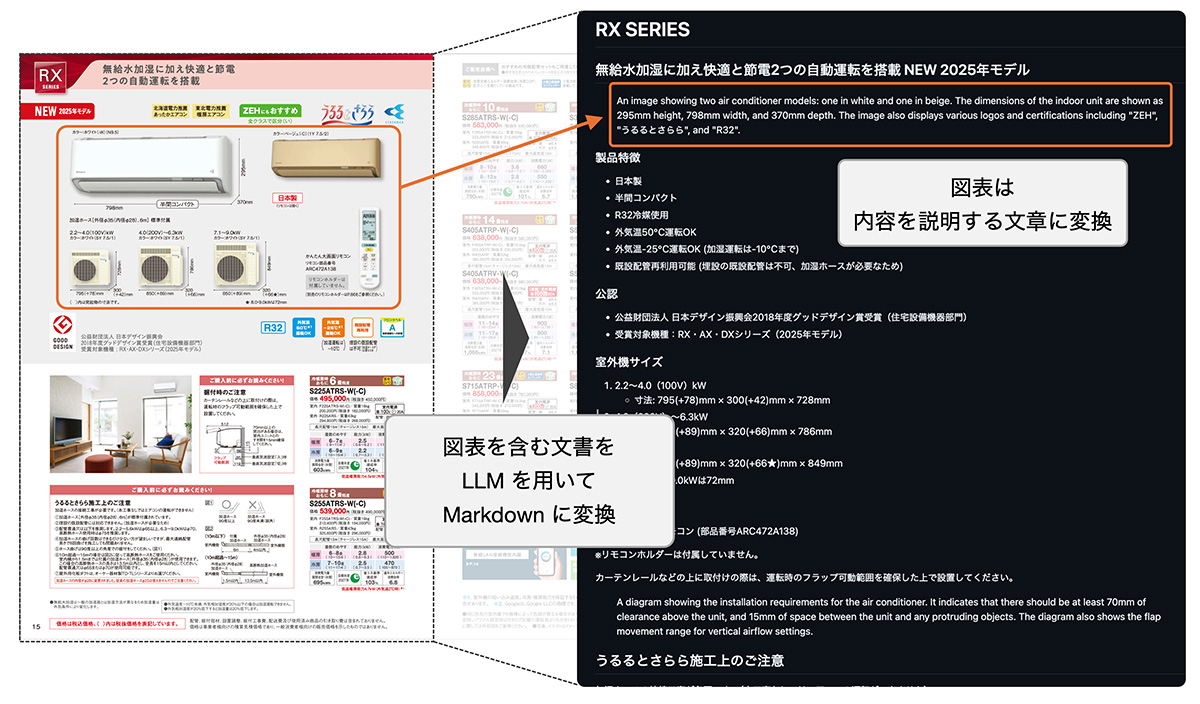
社内での利用状況
このテンプレートはリリース後半年で、コーポレート、研究、設計部門など幅広い分野に渡り、約 8 部門・チームで使われています。当初の予想以上にニーズが広がっており、特に普段の業務で AWS を直接触る機会が少ない部門からも活用されています。また、これをベースにさらに開発を進めようというプロジェクトもいくつか進んでいます。
RAG テンプレートがここまで素早く広がった主な理由は次の 3 つがあると考えています。
- すぐ始められる
AWS アカウントがあれば、約 2 時間程度で PoC をスタート可能 - 初期コストが小さい
Amazon Bedrock Knowledge Bases を利用することで、低コストでの導入が可能 - PoC から本番への移行がスムーズ
テンプレートは最初から本番運用を想定した作りになっているため、価値を確認したらそのまま本番環境として利用可能
さらに、社内の技術コミュニティや生成 AI コミュニティでの発表を通じて、実際の活用事例や効果が共有されたことも、導入を後押しする要因となりました。
各部門での成功体験が共有されることで、「まずは試してみよう」という文化が醸成され、結果として全社的な生成 AI 活用の推進につながっています。
まとめ
筆者プロフィール

森本 康太 (もりもと こうた)
ダイキン工業株式会社
電子システム事業部
ダイキン工業株式会社で、社内向けに RAG システムや AI エージェントの開発をしています。最近では、社内の空調に関する専門知識を学習した LLM の開発をしています。趣味は地下アイドルのライブに通うこと。

五十嵐 悠生(いがらし ゆうき)
ダイキン工業株式会社
テクノロジーイノベーション・センター
RAG をはじめとする生成 AI を使ったシステムの開発・検証や、生成 AI を活用したソフトウェア開発プロセス刷新に取り組んでいます。分割トラックボール付きキーボードを愛用しています。