- AWS Builder Center
- builders.flash
ココナラにおける SLO 設定の実践ガイド ~ ユーザー満足度の向上に向けた SRE のプラクティス適用
2025-11-04 | Author : 川崎 雄太 (株式会社ココナラ)
はじめに
こんにちは、株式会社ココナラの川崎です。
SRE・社内情報システム・セキュリティのエンジニアリングマネージャーと技術広報を中心とした開発の進化を担うロールを持っています。
以前、セキュリティ運用に関する記事を 2 件寄稿していますので、もし良かったらそちらもご覧ください。
本記事では、ココナラがどのようなSLOを設定していて、どのように監視・計測し、改善対応をしているか?について、実際の運用に基づいた工夫や注意点を紹介します。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
なぜココナラに SLO が必要だったのか
まずはココナラのビジネスの特性からご紹介しますと、スキルのマーケットプレイスとして多様なサービスを提供しており、ユーザー (出品者と購入者) 間のマッチング、取り引きの安定性・決済の信頼性など、求められることが多いです。
特に取り引きの成立率やリピート率は、ユーザー体験の質に直結します。今まではユーザーの問い合わせやご意見箱へ投稿といったリアクティブな情報収集しかできておらず、不具合への対応が後手後手に回っていました。
ユーザー体験の悪化をリアクティブでしか気付けない状況はユーザーの離脱や流通高の低下を招くため、事業成長にも影響を与えると言わざるを得ません。
その状況をいち早く改善するために、私たちはサイトの信頼性を定量的に評価し、継続的な改善が実現できるように SLO (Service Level Objective) の導入に踏み出しました。
ココナラで設定している SLO
ココナラで SLO を設定しているのは以下の点です。
|
項目
|
SLI 定義
|
SLO 目標
|
|---|---|---|
|
リクエスト成功率
|
成功したリクエストの割合 |
99.96% |
|
ユーザーアクションの発生数
|
単位時間あたりの回数 |
※ユーザーアクションごとに個別設定 |
「リクエスト成功率」は全てのパスに対して、2xx 系で返却している割合を計測しています。
WAF で 4xx 系を返却するものは対象外としています。
「ユーザーアクションの発生数」はココナラにおいて重要と識別しているユーザーアクション (たとえば、ログインや決済、トークルーム / DM など) の回数を単位時間ごとに計測しています。
ココナラで実施しているモニタリング運用
まずは監視基盤について、ご説明します。
Amazon EC2 上で構築している Grafana / Prometheus で SLO を測定しており、可視化やアラート発砲も実現しています。
おもに SRE チームが日々モニタリングしたりしており、毀損している部分を Amazon CloudWatch / Amazon Athena を用いた深堀りを行います。
それに加えて、SLO とパフォーマンス改善にコミットする委員会を立ち上げ、アプリケーション開発者と協業してユーザー体験を高めるためにはどうしていくべきか ? を議論しています。
また、アラートがオオカミ少年状態になりがちでしたので「ユーザーに影響がある、かつ、対応が必要なもの」に絞り込みの実施などの運用改善を行うことで、アラート対応の高速化・効率化を実現しようと試みています。
別の切り口として、SIEM on Amazon OpenSearch Service を用いたセキュリティログ分析をセキュリティエンジニア中心に実施しており、攻撃の予兆の検知と対応の高速化を実現しています。
詳細は冒頭でご紹介した記事に記載がありますので、ぜひそちらも合わせてご参照いただけますと幸いです。
先ほどの「ココナラで設定している SLO」に照らし合わせますと、以下のとおりの運用をしています。
リクエスト成功率
- 「リクエストが単位時間あたりに 2xx 系で返却された割合が 99.96% を下回った場合」にアラートを通知するような仕組みを構築しています。
- パス単位に計測しており、サブドメイン単位に集約してモニタリングを行っています。
ユーザーアクションの発生数
- 「直近の各デバイスのユーザー行動回数が、過去 1 年間の同曜日、同時間帯の回数に比べて統計的に明らかに少ない場合」にアラートを通知するような仕組みを構築しています。
- 時間帯は直近 30 分、直近 1 時間・2 時間・4 時間・8 時間、直近 1 日・7 日といった括りで比較を行っています。
後者を取り組んだきっかけですが、リクエスト成功率だけでは見えない問題を検知するために異常検知を導入することで、直近の数値との比較を行うようにしました。
ココナラの監視基盤イメージ図
実際の運用と工夫
前述の運用の中でアラート通知や委員会でのモニタリング・議論を行っていますが、それ以外の定点確認としてチームの朝会を活用しています。朝会の中でダッシュボードや Slack の通知を確認し、傾向分析 ~ 次のアクション創出までを行っています。
実際は SLO 以外のメトリクスもモニタリングしているので、モニタリング対象の 1 つという位置づけですが、アラートやモニタリングの仕組みで検知できないような変化を複視で見ることで、プロアクティブな改善に向けたアクションを創出しています。
現在のモニタリング手法では、深堀りするのに時間を要したり、エラーをピンポイントかつ一気通貫で見ることができない状況のため、AWS X-Ray を導入することで業務効率化と調査迅速化を実現しようと改善を進めています。
クラウドサービスを使う上で考えなくてはならないのが、
- 責任共有モデルを正しく理解したうえで、サービス運用を行う必要がある
- クラウドサービスといっても 100% の稼働率ではないので、「何かトラブルが起きる」という前提で、システムを構築する
という点です。
クラウドサービスの特性を理解し、うまく利活用することで、サービス側が対応すべきところの責務が明確化したうえで、より SLO 達成に向けた運用に注力できる状況を作れることが望ましいです。
注意点としては「何でもかんでも計測すれば良いわけではない」です。たとえば「ユーザー体験を損なう」というのはクリティカルユーザージャーニーで言うとどの部分にあたるか ? を明確化し、それらに対する SLO を設定します。
アラート疲れを起こさず、ユーザー体験を確実に改善するために選択と集中を行うことが大切です。
各ダッシュボードのイメージ
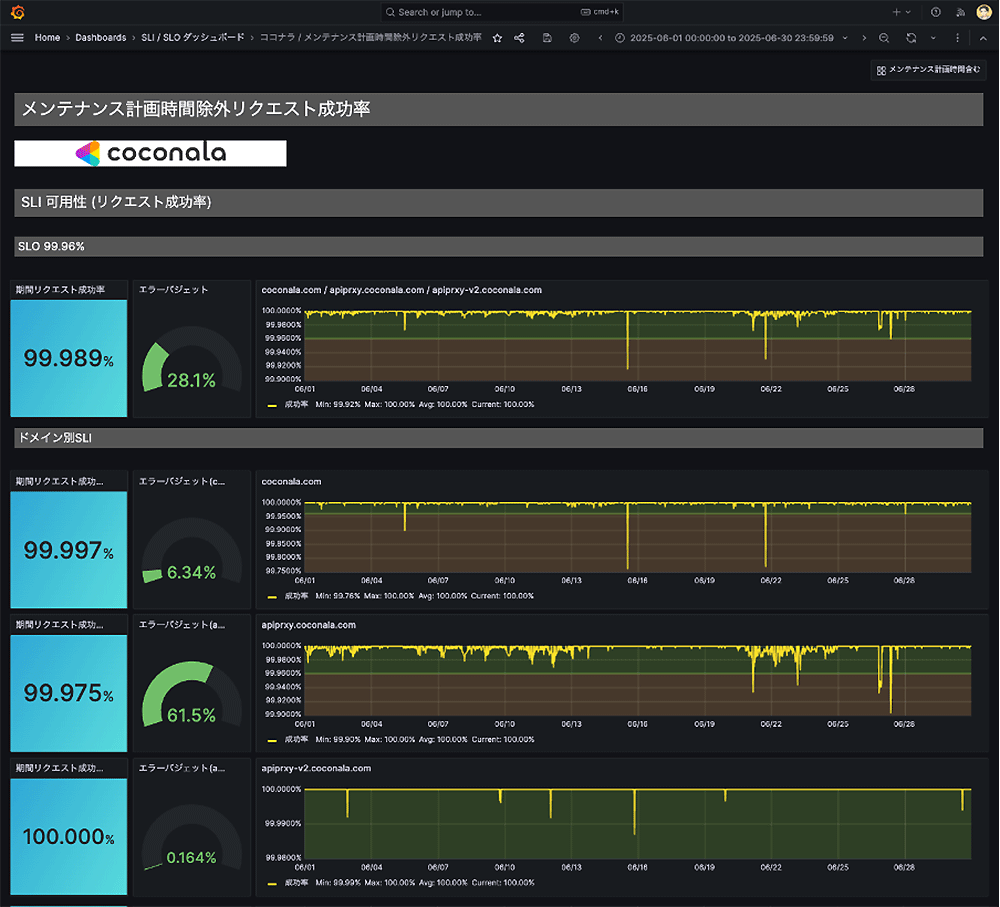
「リクエスト成功率」のダッシュボードイメージ

「ユーザーアクションの発生数」の Slack 通知イメージ
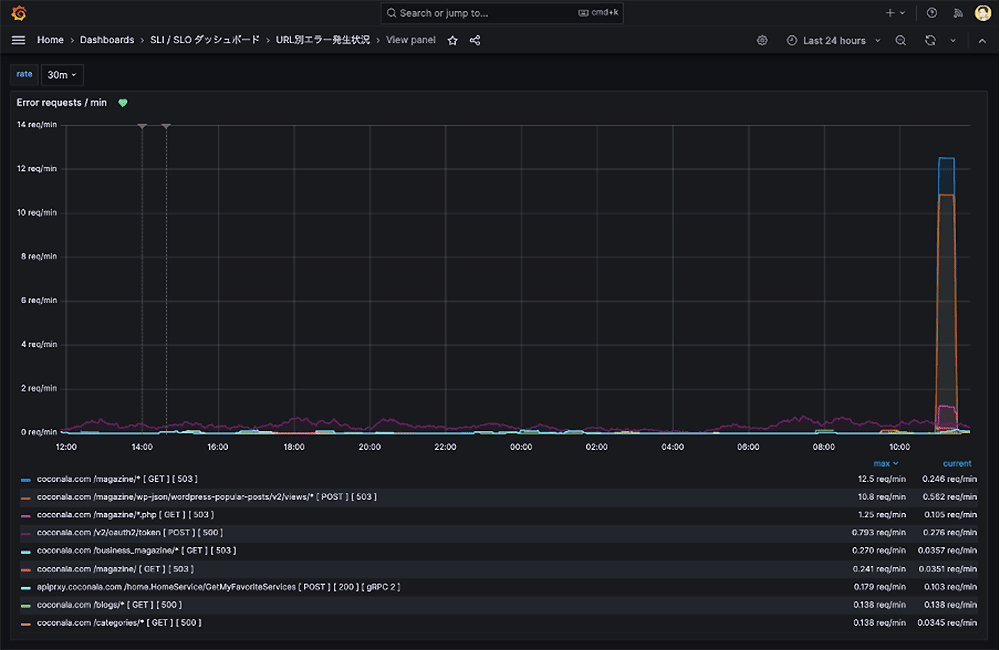
URL 別のエラー発生状況確認ダッシュボードイメージ
成果と今後の展望
SLO 運用を開始することで今まではリアクティブにしか気づくことができなかったユーザー体験の悪化に対して、検知早期化 ~ 改善までのサイクルを高速化することができました。
プロアクティブに対応ができればユーザーの満足度悪化を局所化することができ、結果としては流通高の増加にも寄与できると考えています。副次的な効果としてエンジニアの品質意識が高くなったことも挙げられます。
今後はモバイルアプリの領域やシステム連携している外部サービスの SLO / パフォーマンスの状況も明らかにしていき、さらなるユーザー満足度向上を目指します。
これは自社だけの話ではありませんが、SLO 運用については試行錯誤して取り組んでいる企業が多いと思うので、builders.flash を中心とした AWS のドキュメントから自社のベストプラクティスを探してほしいです。
また、日々開催されているイベントやカンファレンスで得られる知見も大事ですので、ぜひさまざまなところから情報収集をしていただけるとより良いと思います。
筆者プロフィール
川崎 雄太
株式会社ココナラ
システムプラットフォーム部 部長 兼 Dev Enabling室 室長
株式会社ココナラテック 執行役員 情報基盤統括本部長
SRE・社内情報システム・セキュリティのエンジニアマネージャー。Dev Enabling 室の室長も兼務しており、技術広報を中心とした開発の進化に関するミッションも持っている。
2024 年 9 月から株式会社ココナラテックの執行役員も兼任。
2025 年の AWS Community Builder (Security) に選出。
