- AWS Builder Center›
- builders.flash
AWS と LiteLLM で実現する、セキュアで柔軟な AI エージェント基盤のアーキテクチャ
2025-11-04 | 中山 祐平 (フリー株式会社)
はじめに
こんにちは、freee の AI 駆動開発チームです。
AI エージェント「Cline」をはじめとする AI ツールの活用を全社規模で推進するには、その裏側でリクエストを安全かつ効率的に処理するプロキシ基盤の存在が不可欠です。Amazon Q Developer などのマネージドサービスを活用する方法もありますが、自社の要件を満たすために独自の基盤の構築が必要になる場合もあり、多くの開発現場で「AI を導入したいが、セキュリティやコスト管理はどうすれば ?」といった課題が議論されているかと思います。
本記事では、この課題に対する freee の一つの答えとして、私たちがどのような思想で、どのようなアーキテクチャを設計し、どんな工夫を凝らしてこのプロキシ基盤を構築・運用しているのか、その設計思想やアーキテクチャ、実装の工夫に焦点を当てて、その内側をご紹介します。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
プロキシの要件とアーキテクチャ
AI エージェントの導入にあたり、私たちはプロキシ基盤に大きく 3 つの要件を設定しました。
- セキュリティとガバナンス : 開発者がツールを安全に利用できるよう、意図しない情報流出を防ぎ、誰がどのように利用しているかを把握できること。
- オブザーバビリティ : 単なるコスト監視に留まらず、利用動向を詳細に分析し、開発組織全体の生産性向上に繋げるためのインサイトを得られること。
- プロバイダーの柔軟な選択肢 : 特定の LLM プロバイダーだけでなく、将来にわたって用途に応じた最適なモデルを迅速かつ容易に使い分けられる拡張性を持つこと。
これらの要件を満たすため、私たちはオープンソースの LiteLLM と AWS の各種サービスを組み合わせたアーキテクチャを設計しました。
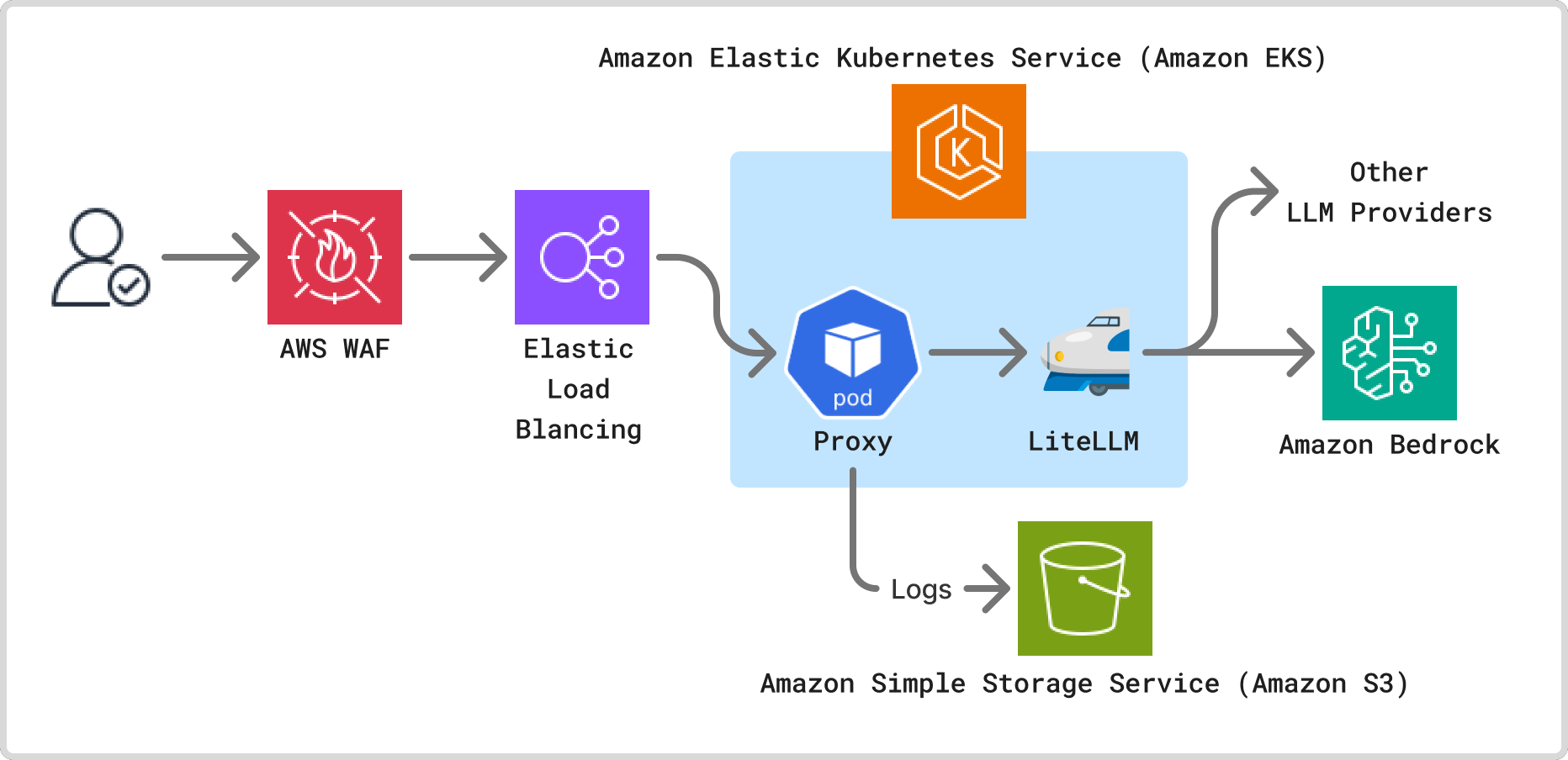
クライアントからのリクエストは、まずAWS WAFによるセキュリティチェックを経たのち、Application Load Balancer へと到達します。その後、リクエストは Amazon EKS クラスター上で稼働するプロキシーアプリケーションに転送されます。このアプリケーションで認証やガードレール、コンテキスト識別といった処理が行われ、最終的に LiteLLM を通じて Amazon Bedrock などの LLM プロバイダーへとルーティングされます。LLM プロバイダーには様々なサービスがありますが、Amazon Bedrock となった決め手は、利用できるモデルの数やデータ利用ポリシーの明快さでした。
アプリケーション実装における 3 つの工夫
このアーキテクチャを実現するにあたり、私たちが実装した 3 つの主な工夫をご紹介します。
工夫① アプリケーションレイヤーでの多層ガードレール
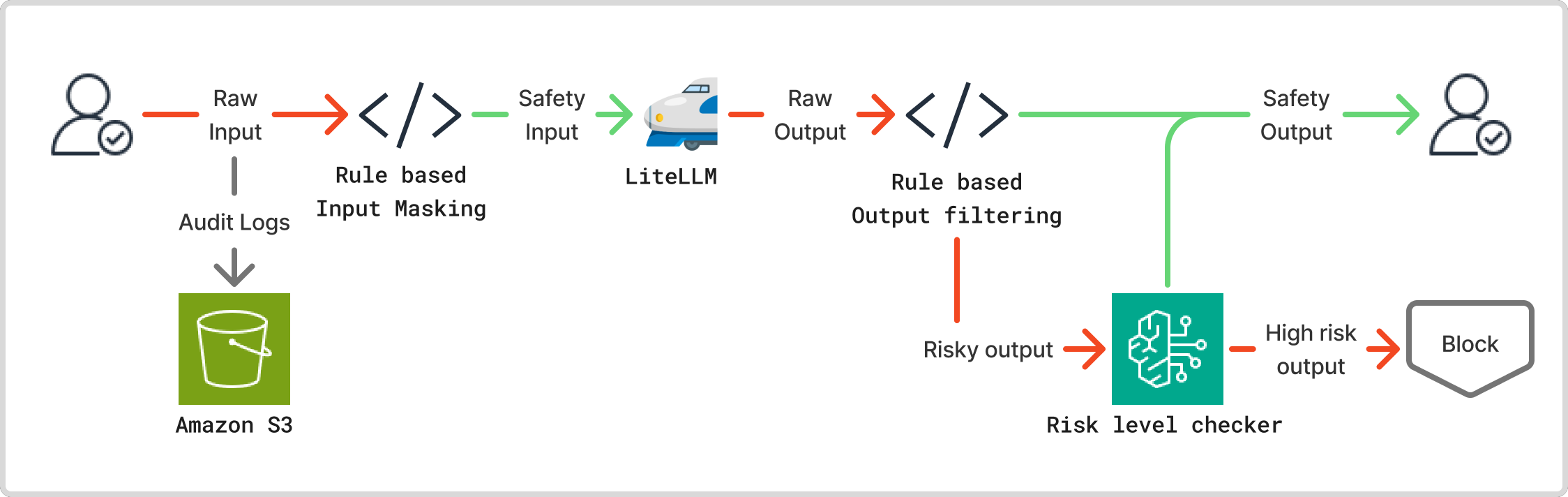
セキュリティとガバナンスを徹底するため、私たちはプロキシのアプリケーションレイヤーに多層的なガードレールを実装しました。
- 監査ログ : ガバナンスとトレーサビリティの担保のために、プロキシへの入出力をすべてロギングします。すべての入出力の監査ログは Amazon S3 に記録されます。
- 入力ガードレール: ユーザーからのプロンプトに、意図せず AWS のアクセスキーや個人情報などの機微な情報が含まれていないかを正規表現でチェックし、該当した場合は自動でマスキング処理を施します。これにより、機密情報が LLM プロバイダーに送信されるリスクを低減します。
- 出力ガードレール : LLM からの応答も同様にチェックします。特に AI エージェントが生成する実行コマンドを多角的に検査します。まず、正規表現を用いて sudo や chmod といった権限昇格に繋がるコマンドや、curl wget による意図しない外部通信など、危険と想定されるコマンドパターンを静的に検出します。さらに、それだけでは判断が難しいコマンドについては、別の LLM にそのコマンドのリスク評価を問い合わせます。 LLM がリスクレベルを「高」と判定したコマンドは実行をブロックすることで、静的チェックをすり抜けるような未知の脅威にも対応できる仕組みを構築しています。
なぜ自前で実装するのか?
「Amazon Bedrock Guardrails」のようなマネージドサービスもありますが、私たちはアプリケーション側での実装を選択しました。その理由は「柔軟性」です。バックエンドで利用する LLM が Amazon Bedrock 以外の場合でも一貫したセキュリティポリシーを適用でき、また、「このツールからのリクエストの場合は、このガードレールを緩和する」といった、より複雑でビジネスロジックに依存した動的な制御を可能にするためです。
工夫② リクエストコンテキストに基づく動的な制御とログ
私たちのプロキシは、単にリクエストを中継するだけではありません。すべてのリクエストに対して「誰が、どのツールから、何のために」使っているかを識別し、そのコンテキスト情報をログや制御に活用しています。
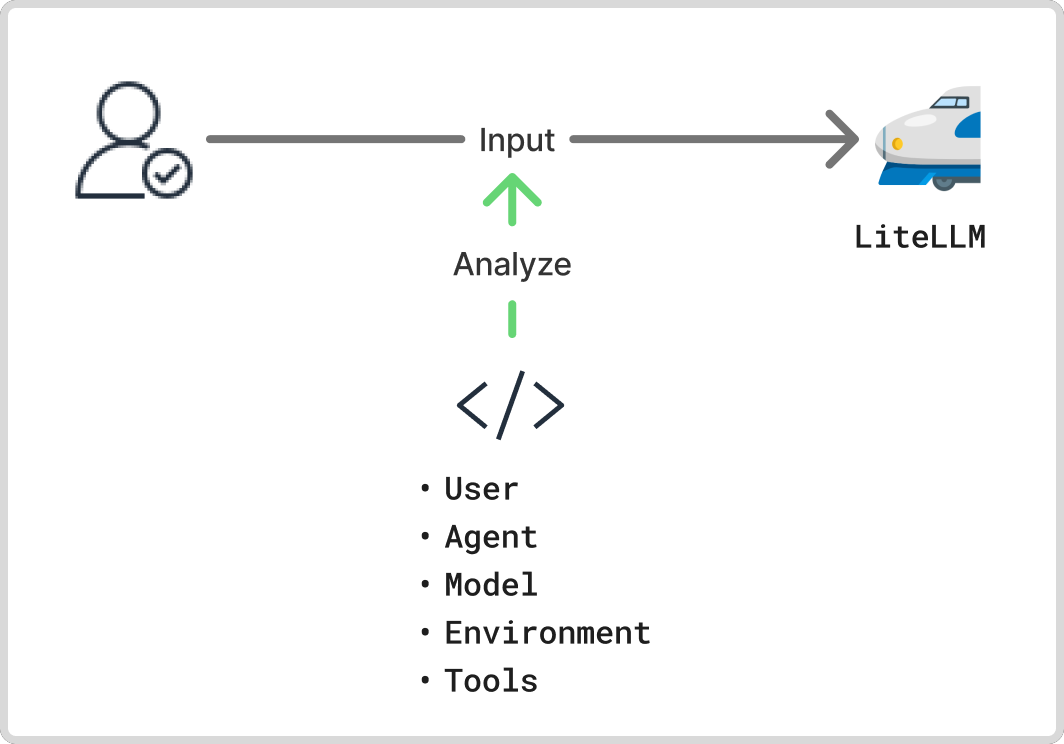
どのように識別しているか?
これは、HTTP ヘッダーの User-Agent や、各ツールが生成する特有の定型的なシステムプロンプト (例: You are Cline,...) をプロキシ側で解析することで実現しています。これにより、リクエストが「A さんが、Cline を使って、macOS から」発行されたものである、といった詳細なコンテキストを自動で判定できます。
識別して何が嬉しいのか ?
このコンテキスト情報は、単なるアクセスログ以上の情報を活用できます。まず、オブザーバビリティの向上に繋がり、ダッシュボードで「Cline の利用率が急上昇している」「このチームは Copilot をよく使っている」といった利用実態を定量的に把握し、ツールの ROI 測定や利用促進策の検討に役立てています。さらに、このコンテキストに基づいて「Copilot からのリクエストの場合は、ファイル書き込み系のガードレールを有効にする」といった動的な制御も可能になり、セキュリティと利便性のバランスを取っています。
工夫③ LiteLLM によるマルチ LLM 戦略とパフォーマンス最適化
幅広い技術やサービスの選択肢を持たせておくことは、変化の速い AI 領域において重要です。私たちはその戦略の核として LiteLLM を採用しました。
マルチ LLM 戦略
LiteLLM は、多様なLLMプロバイダーの API 差異を吸収するプロキシです。これをアーキテクチャに組み込むことで、バックエンドの LLM を Amazon Bedrock 上のモデルから、他のプロバイダーが提供するモデルへ切り替える選択肢を残すことが出来ます。これにより、常にコストと性能のバランスが取れたモデルを選択し続けることが可能になります。
パフォーマンス最適化
さらに、私たちはこのプロキシ基盤で最適化も行っています。例えば、Amazon Bedrock のプロンプトキャッシュ機能を活用するために、リクエストに対してプロキシ側で自動的に cache_control パラメータを付与する処理を実装しました。これにより、繰り返し発生する類似の対話において API コールを効率化し、低レイテンシとコスト削減を同時に実現しています。
可用性の担保
また、プロキシ基盤は、Amazon Bedrock のクロスリージョン推論を有効にすることで高い可用性を実現しています。さらに、LiteLLM でフォールバック先のモデルを設定しており、制限などでモデルの呼び出しに問題が発生した場合に、自動的に別のモデルに切り替えることができます。これにより、システム全体の可用性を担保し、安定した基盤の提供を実現しています。
まとめ
本記事では、freee が AI エージェントの全社活用を支えるために構築した、プロキシ基盤のアーキテクチャとその設計思想についてご紹介しました。
- アプリケーションレイヤーでの多層ガードレールによるセキュリティ確保
- リクエストコンテキストの識別によるオブザーバビリティの向上と動的な制御
- LiteLLM の活用によるプロバイダーの柔軟性とパフォーマンス最適化
freee では、これからも AI 技術の進化に対応しながら、開発者がより安全で効率的に AI を利用できる環境を目指していきます。この記事が、皆さんの組織における AI 活用基盤の構築の一助となれば幸いです。
筆者プロフィール
フリー株式会社 AI駆動開発チーム
面白法人カヤックに新卒入社後、Web 開発や AR/VR コンテンツ制作に従事。その後 IoT 関連のスタートアップやフリーランスを経て 2022 年から現職。freee では、プロダクト横断の基盤サービスの設計や開発を担当。開発の中で AI ツールの活用などを模索し、2025 年 4 月からは AI 駆動開発の専門チームに所属。Cline をはじめとした AI ツールの社内導入やそれらを活用した開発プロセス探索の取り組みを行っている。
