- AWS Builder Center
- builders.flash
知財業務を革新するオムロンの知財 AI エージェント実装事例
2025-11-04 | Author : 津田 学 (オムロン株式会社), 熊巳 創 (オムロン株式会社), 日下 武紀 (オムロン デジタル株式会社)
はじめに
研究開発プロセスのデジタルトランスフォーメーションが企業の競争力を左右する時代において、生成 AI の登場は大きなブレイクスルーをもたらしました。特に知的財産 (知財) 業務は、膨大な特許情報の分析など、高度な専門知識と多くの時間を要する領域です。オムロン株式会社では、アマゾン ウェブ サービス (AWS) のクラウド基盤を活用して、研究開発に特化した生成 AI 活用環境基盤「RD Buddy」を構築しており、RD Buddy 上に知財 AI エージェントを実装しました。知財 AI エージェントの実装方法と、その効果について解説します。
builders.flash メールメンバー登録
builders.flash メールメンバー登録で、毎月の最新アップデート情報とともに、AWS を無料でお試しいただけるクレジットコードを受け取ることができます。
知財業務における課題
知財業務、特に特許関連業務には多くの課題が存在します。世界中で日々数千件の特許が出願され、その全てを把握することは人力では不可能です。また、技術と知的財産の両面の専門知識が必要であり、限られた期間内での調査・分析・判断が求められます。さらに、取り扱う情報の多くが企業の競争力に直結する機密情報であるため、情報セキュリティの確保も重要な課題となっています。
これらの課題に対し、生成 AI の活用が期待されていましたが、パブリックな生成 AI サービスを利用する場合、情報漏洩リスクやコスト増大という新たな課題が生じています。そこでこれらの課題を解決するため、独自の生成 AI 基盤上にAI エージェントの実装を行いました。
知財 AI エージェントの実装
基盤となる RD Buddy は、研究開発プロセスに特化した独自の生成 AI 基盤です。AWS 上に構築されたサーバーレスアーキテクチャを採用し、外部サービスへの機密情報流出リスクを最小化しています。多層的セキュリティ設計による情報漏洩防止、サーバーレスアーキテクチャによるコスト最適化、そしてユースケースに応じた最適なモデル選択が可能な柔軟性を特徴としています。RD Buddy を基盤として、知財業務に特化した知財 AI エージェントを実装しました。
このシステムでは以下のステップで特許情報の高度な検索・分析を実現しています:
- 特許データの取り込みと前処理
- 意味的検索
- 生成 AI 連携
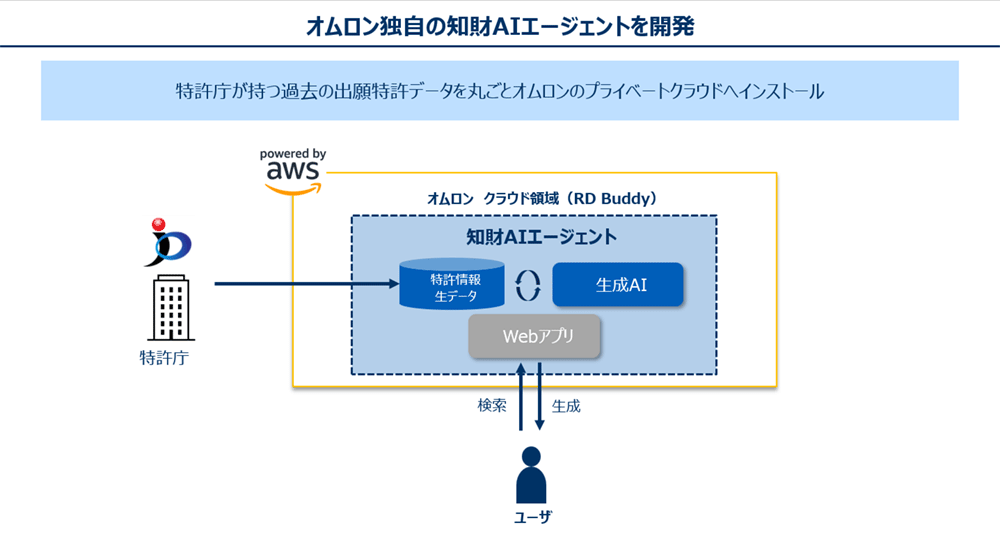
RD Buddy のアーキテクチャ構成
各機能について
特許データの取り込みと前処理
特許庁の公開情報を Amazon S3 に保存し、S3 イベント通知をトリガーとして AWS Lambda 関数が自動実行されます。Lambda 関数では特許 XML ファイルを解析し、構造化データに変換します。処理されたメタデータは Amazon DynamoDB で管理し、効率的なデータアクセスを実現しています。
意味的検索
意味的検索を実現するためにベクトル検索基盤を構築します。Amazon OpenSearch Serverless を採用し、特許文書を Amazon Bedrock の基盤モデル (Amazon Titan Text Embeddings V2) でベクトル化しています。これにより、従来のキーワード検索では発見困難な、意味的に類似した特許の高速検索が可能になりました。各特許の技術分野、課題、解決手段など、特許情報の高度な検索・分析に適した要素ごとにベクトル化することで、より精緻な検索を実現しています。
生成 AI 連携
Amazon Bedrock の提供モデル (Claude 3.5 Sonnet) と連携し、自然言語での特許検索や分析ができるエージェントを構築しています。入力情報全体をフラットに処理できるモデルとして採用し、効果的な分析を行っています。
これら実装により、特許の専門家でなくても自然言語で「自動運転に関する画像認識技術」のような複雑な問い合わせが可能となり、関連特許の迅速な発見と分析を実現しました。
知財 AI エージェントの実装における工夫点
最適な知財 AI エージェントを実現するために、エージェントはスクラッチ開発で実装しました。スクラッチで開発するにあたって、以下点を工夫しています:
- セキュリティ対策の徹底
- 精度向上への取り組み
1. セキュリティ対策の徹底
IAM ベースのアクセス制御
AWS Identity and Access Management (IAM) を活用し、最小権限の原則に基づく厳密な権限管理を実装しています。各 Lambda 関数には必要最小限の権限のみを付与し、Amazon OpenSearch Serverless へのアクセスも認証済みプリンシパルに限定しています。また、Amazon OpenSearch Serverless のインデックス制御にはデータアクセスポリシーの管理が必要となっており、サービスへのアクセス権限だけでは登録データへアクセスできません。この仕様は登録されたデータの情報漏洩防止に寄与します。
データ暗号化の徹底
全てのデータを保存時・転送時ともに暗号化しています。具体的には、Amazon S3 ではSSE-S3 による自動暗号化と HTTPS 通信の強制を行い、OpenSearch Serverless では AWS 管理キーによる暗号化ポリシーを適用しています。さらに、DynamoDB では保存時暗号化と Point-in-Time Recovery (PITR) の有効化を実施し、通信においては全ての AWS サービス間通信で TLS 1.2 以上を使用しています。
ネットワークセキュリティ設計
情報漏洩リスクを排除するため、以下の多層的なネットワークセキュリティ設計を実装しています。
閉域ネットワークによる分離
データクレンジング用 Amazon EC2 インスタンスと、特許分析専用アプリケーションはAWS Direct Connect で接続されたオムロン社内 LAN との閉域ネットワーク内に配置しています。これにより、大規模データクラウドリフトの帯域確保とセキュリティの両立を実現しています。
サーバーレス機能のセキュリティ
その他のサーバーレス機能 (Lambda、OpenSearch Serverless) については上記 IAM ベースのアクセス制御を行っています。
この設計により、機密情報を扱うコンポーネントは完全に管理された環境で動作し、外部からの不正アクセスを防止しています。
監査とトレーサビリティ
AWS CloudTrail を使用して、全ての API 呼び出しの詳細を記録しています。Amazon CloudWatch Logs を利用して、Lambda 関数の実行ログを記録し、自動アラートを設定しています。Amazon S3と Amazon Athena を組み合わせて、外部リクエストのAPIおよび生成 AI による発生費用ログを管理しています。これらのログは OpenX JSON SerDe 形式で保存され、Athena クエリを使用して利用状況やコスト分析をユーザーや組織単位で実現しています。さらに、AWS X-Ray を使用して、分散トレーシングによるパフォーマンス監視を行っています。
2. 精度向上への取り組み
特許データの取り込みと前処理
生成 AI の出力を適応的に制御し、専門家のフィードバック精度を損なうことなく応答する仕組みを構築しました。単純な文字数制限ではなく、重要キーワードを保持するインテリジェントな要約により、情報の要点を損なわないよう工夫しています。
切り詰めた部分から重要語彙を抽出して追加することで、検索精度や応答の質を向上させています。
AI モデルの最適化
用途に応じて最適な AI モデルを選択・組み合わせることで、より高い精度を実現しています。また、最適なモデルを選択・組み合わせることで、より高い精度を実現しています。モデル組み合わせやクエリパターンについては機微情報のため公開できませんが、各モデル特性を踏まえた選択を行うことでパフォーマンス、コストの最適化を図っています。
さらに、出力制御においては単純な文字数制限ではなく、重要キーワードを保持することで、情報の要点を損なわないようにインテリジェントな切り詰めを行っています。また、切り詰めた部分から重要語彙を抽出して追加することで、検索精度や応答の質を向上させています。
知財 AI エージェントの活用事例
知財 AI エージェントの導入により、特許分析の効率化に大きな成果を上げています。従来、特許分析には膨大な時間と労力が必要でしたが、AI エージェントの導入により、分析時間を大幅に削減することに成功しました。関連特許からの詳細な分析レポートを自動生成する際などに効果を発揮しています。
また、特許出願戦略の最適化にも活用することができます。知財 AI エージェントは、既存特許の分析から技術トレンドの可視化、競合他社の特許動向分析などを行い、最適な出願戦略を提案します。さらに、社内の他の DB との連携により、特許情報を起点とした多角的な調査・分析を可能としています。
今後の展望
まとめ
オムロンの知財 AI エージェントは、Amazon Bedrock をはじめとする AWS サービスを活用することで、セキュリティとコスト効率を両立しながら、知財業務の効率化と高度化を実現しました。特に重要なのは、単なる業務効率化ツールではなく、知財の専門家の能力を拡張し、より戦略的な知財活動を支援するパートナーとしての役割を果たしている点です。
生成 AI の進化は今後も続きますが、その技術を安全かつ効果的に活用するためのアーキテクチャ設計と運用ノウハウが、企業の競争力を左右する重要な要素となるでしょう。
筆者プロフィール

津田 学
オムロン株式会社
技術・知財本部 デジタルソリューションセンタ
デジタルプラットフォーム部 部長
研究開発エンジニアの Digital Employee Experience 向上をライフワークとし、AWS クラウド開発環境「RDinX」や生成 AI 活用基盤「RD Buddy」などの研究開発 DX 基盤の構築・運用を推進。これらの取り組みは社内外から高く評価され、AWS 社の各種イベントでの登壇や、メディアでの紹介多数。AI ガバナンス委員会の運営も担当し、オムロングループ AI 統制の浸透にも貢献している。

熊巳 創
オムロン株式会社
技術・知財本部 知的財産センタ 知財専門職
知財情報分析にデータサイエンスを融合した次世代型データ分析手法の開発・導入を推進。社内生成 AI 推進活動「AIZAQ」にテクニカルアドバイザーとして参画し、社内表彰を複数回受賞。社内の生成 AI 活用文化の醸成に貢献。また、AWSクラウド開発環境「RDinX」を活用し、知財業務に最適化された知財 AI エージェントの開発にも参画し、実装をリード。外部に向けても、講演や論文執筆を通じて生成 AI と知財の融合に関する知見を発信し、オムロンにおける知財 DX と AI 活用推進をリードしている。

日下 武紀
オムロン デジタル株式会社
コア技術センタ アセット推進部 先端技術グループ主査
オムロングループの生成 AI 基盤構築を主導し、全社横断的な AI システム展開を推進。企業内の多様な部門における AI 活用のための PoC 支援やコンサルティングを行い、汎用基盤と個別ニーズの両立を実現。AWS 技術を活用した生成 AI 基盤の設計・開発チームをリードし、技術と顧客ニーズの架け橋として活躍している。