Containers
Optimizing your Kubernetes compute costs with Karpenter consolidation
Introduction
Karpenter was built to solve issues pertaining to optimal node selection in Kubernetes. Karpenter’s what-you-need-when-you-need-it model simplifies the process of managing compute resources in Kubernetes by adding compute capacity to your cluster based on a pod’s requirements. With the recent release of workload consolidation, Karpenter can now be enabled to continuously monitor and optimize the placement of pods to improve instance resource utilization and lower your compute costs.
This post explores Karpenter’s consolidation capabilities and walks through the impact it can have on optimizing Kubernetes data plane costs with a hands-on example.
Karpenter’s workload consolidation
In previous versions, Karpenter would only de-provision worker nodes that were devoid of non-daemonset pods. Over time, as workloads got rescheduled, some worker nodes could become underutilized. Workload consolidation aims to further realize the vision of Karpenter’s efficient and cost-effective auto scaling by consolidating workloads onto the fewest, least-cost instances, while still adhering to the pod’s resource and scheduling constraints. Workload consolidation can be enabled in Karpenter’s Provisioner Custom Resource Definition (CRD). Provisioners are responsible for the lifecycle actions of Karpenter controlled nodes in the cluster. They allow teams to define capacity constraints, as well as behaviors (like expiration and consolidation) for the nodes they’ve launched.
When enabled in the Provisioner, Karpenter continuously monitors your cluster workloads for opportunities to consolidate the compute capacity for better node utilization, as well as cost efficacy. Karpenter also honors any scheduling constraints that you have specified (i.e., pod affinity rules, topology spread constraints, etc). Since Karpenter spins up nodes based on workload requirements, it’s important to accurately specify them. To do this, you should add both the central processing unit (CPU) and memory requests for your pods. This helps prevent resource starvation or hogging, especially when running multiple workloads alongside each other on the cluster. Furthermore, it’s an important requirement for the workload consolidation feature in Karpenter to be effective.
Prerequisites
To carry out the example in this post, you’ll need to setup the following:
- Provision a Kubernetes cluster in AWS
- Install Karpenter for cluster autoscaling
- Install Amazon Elastic Kubernetes Service (Amazon EKS) Node Viewer
To automate the process of this setup, you can use Amazon EKS blueprints for Terraform, which has an example for deploying Karpenter as an add-on to your cluster. You don’t have to modify the Terraform source code in order to carry out the example in this post.
Provisioners
Karpenter controls nodes based on the Provisioner Custom Resource Definition (CRD). The Provisioner is a configuration file responsible for determining things like the type of computing capacity, instance types, additional kubelet configurations, resource parameters, and other node lifecycle specifications. You can deploy multiple Provisioner CRDs to your cluster depending on their respective uses, and as long as they don’t overlap.
Amazon EKS blueprints has example provisioners in the examples/karpenter/provisioners folder. In this case, we’ll be working with a single Provisioner for a Node.js example application called express-test. As such, any pods for this application won’t be scheduled unless its dedicated Provisioner is deployed to the cluster.
The Provisioner file is provided in the following code:
Provisioner
You can save this file and deploy it to your cluster with the following command:
Walkthrough
Workload consolidation example
In this section, we’ll deploy the express-test application with multiple replicas, one CPU core for each pod, and a zonal topology spread constraint. In addition to this, the workload manifest will specify a node selector rule for pods to be scheduled to compute resources managed by the Provisioner we created in the previous step. After observing how Karpenter provisions the initial set of nodes, we’ll modify the deployment by updating the number of replicas and track Karpenter’s consolidation in response to this change.
The application’s resource manifest is specified in the following code.
Application manifest
You can save and apply the Deployment to your cluster by running the following command:
After that, we can view the compute usage and cost of the Karpenter nodes using the Amazon EKS Node Viewer.

Karpenter has added 3 nodes (2 x t3.2xlarge instances and 1 x c6a.2xlarge) to our cluster that fulfill the requirements specified in our manifest, catering to both the compute requirements and the scheduling constraints. These are Spot instances with eight CPU cores, and each node has been provisioned in a separate availability zone (AZ), eu-west-1a, eu-west-1b, and eu-west-1c. Karpenter added nodes that account for the one CPU core that was requested for 20 replicas (spread across different AZs), along with daemonset CPU usage and resources reserved for the kubelet.
As you can see in the screenshot above, the eks-node-viewer CLI tool displays what the current node setup would cost per month.
The next step is to modify the original deployment manifest. As shown below, we’ll reduce the number of pod replicas from 20 to 10, which in turn reduces the requested resource utilization.
Application manifest
You can deploy these changes by running the kubectl apply -f deployment.yaml command again.
At this point our nodes are underutilized. Previously, Karpenter added three nodes, each with approximately eight CPUs available, to account for the 20 replicas. Now the only way to reduce the cluster cost is to remove the underutilized node. First, it’s isolated and then drained of its pods. If you continue monitoring the nodes, you’ll notice this sequence of events take place. Finally, the pods are scheduled between the two remaining Spot instances. The results of these changes can be seen in the following image.
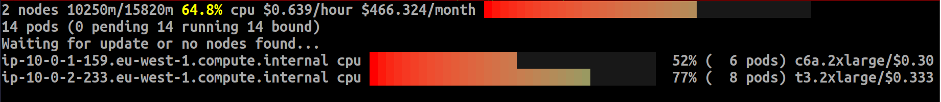
As the results show, with consolidation enabled, Karpenter optimized our cluster compute costs by removing one of the three instances, while still fulfilling the defined resource requirements and the topology spread constraint for our application workload. The data plane cost for this workload was reduced as shown in the screenshot above.
For production environments, it’s recommended to use a tool like kubecost alongside Karpenter to monitor and manage Kubernetes costs. You can follow this user guide on how to setup kubecost for cost monitoring in Amazon EKS.
Cleanup
To avoid incurring additional operational costs, remember to destroy all the infrastructure you created for the examples in this post. First, you need to delete the nodes created by Karpenter. These are managed by the Provisioner CRD, so you can delete this resource from your Kubernetes cluster. After that, you can delete the rest of the infrastructure using Terraform. Make sure you are in the right folder in your terminal and then execute the terraform destroy command. You can also follow the clean up steps for Amazon EKS blueprints.
Conclusion
In this post, we showed you how to combine Karpenter’s new workload consolidation feature and following good practices around resource requests can help reduce your data plane costs in Kubernetes.
Here are some additional resources on the topic:
Karpenter for Kubernetes | Karpenter vs Cluster Autoscaler
Karpenter consolidation in Kubernetes
To learn more about Karpenter, you can read the docs and join the join the community Kubernetes slack channel #karpenter.