AWS Trainium
Trainium — 고성능, 비용 효율적 대규모 AI를 위해 특수 제작
Trainium을 선택해야 하는 이유
AWS Trainium은 Trainium1, Trainium2, Trainium3로 구성된 목적별 AI 액셀러레이터 제품군으로, 다양한 생성형 AI 워크로드에서 학습과 추론을 위한 확장 가능한 성능과 비용 효율성을 제공하도록 설계되었습니다.
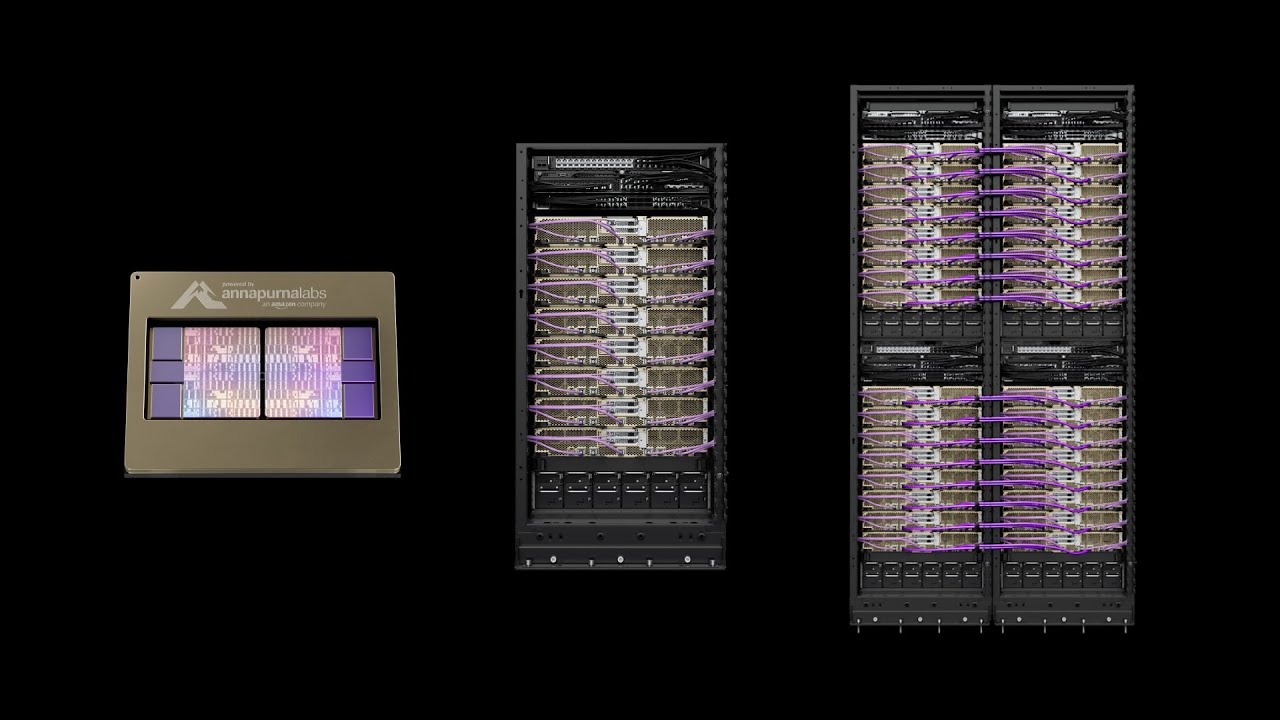
AWS Trainium 제품군
Trainium1
1세대 AWS Trainium 칩은 동급 Amazon EC2 인스턴스보다 훈련 비용이 최대 50% 낮은 Amazon Elastic Compute Cloud(Amazon EC2) Trn1 인스턴스를 구동합니다. Ricoh, Karakuri, SplashMusic, Arcee AI를 비롯한 많은 고객이 Trn1 인스턴스의 성능 및 비용 이점을 실현하고 있습니다.
Trainium2
AWS Trainium2 칩은 1세대 Trainium보다 최대 4배 높은 성능을 제공합니다. Trainium2 기반 Amazon EC2 Trn2 인스턴스와 Trn2 UltraServer는 GPU 기반 EC2 P5e 및 P5en 인스턴스보다 30~40% 우수한 가격 대비 성능을 제공하는, 생성형 AI용 목적별 인스턴스입니다. Trn2 인스턴스는 최대 16개의 Trainium2 칩을 탑재하며, Trn2 UltraServer는 AWS의 독자적인 칩 간 상호 연결 기술인 NeuronLink로 상호 연결된 최대 64개의 Trainium2 칩을 탑재합니다. Trn2 인스턴스와 UltraServer를 사용하여 대규모 언어 모델(LLM), 멀티모달 모델, 확산 트랜스포머 등 가장 까다로운 모델을 훈련 및 배포하여 광범위한 차세대 생성형 AI 애플리케이션을 구축할 수 있습니다.
Trainium3
차세대 에이전트, 추론 및 비디오 생성 애플리케이션을 위한 최고의 토큰 경제성을 제공하기 위해 특별히 설계된 AWS 최초의 3nm AI 칩입니다. AWS Trainium3 칩은 FP8 컴퓨팅 2.52 페타플롭(PFLOP)의 2배 높은 컴퓨팅 성능을 제공하고, Trainium2에 비해 메모리 용량을 1.5배, 대역폭을 1.7배 증가시켜 144GB의 Trainium2 메모리와 4.9TB/s의 메모리 대역폭을 제공합니다. Trn3 UltraServer는 Trainium3로 구동되어 Trn2 UltraServer 대비 최대 4.4배 우수한 성능, 3.9배 높은 메모리 대역폭, 4배 이상 향상된 에너지 효율을 제공합니다. Trainium3은 고급 데이터 유형(MXFP8 및 MXFP4)과 실시간, 멀티모달 및 추론(reasoning) 태스크를 위한 개선된 메모리-컴퓨팅 균형을 갖춘 고밀도 및 전문가 병렬 워크로드를 위해 설계되었습니다.
개발자를 위한 설계
새로운 Trainium3 기반 UltraServer는 AI 연구원을 위해 구축되었으며 AWS Neuron SDK를 기반으로 획기적인 성능을 제공합니다.
기본 PyTorch 통합을 사용하면 개발자는 코드를 단 한 줄도 변경하지 않고도 훈련을 실시해 배포할 수 있습니다. AI 성능 엔지니어를 위해 Trainium3에 대한 심층 액세스가 지원되므로, 개발자가 성능을 미세 조정하고, 커널을 사용자 지정하고, 모델을 더욱 발전시키는 것이 가능합니다. 혁신은 개방성을 기반으로 하기 때문에 당사는 오픈 소스 도구와 리소스를 통해 개발자와 소통하기 위해 최선을 다하고 있습니다.
자세한 내용은 Amazon EC2 Trn3 UltraServers를 참조하고 AWS Neuron SDK도 둘러보세요.
장점
Trn3 UltraServers에는 스케일업 UltraServer 기술 최신 혁신 요소가 탑재되어 최대 144개의 Trainium3 칩 전체에서 더 빠른 올투올 집합 통신을 제공하는 NeuronSetich-v1이 지원됩니다. Trn3 UltraServer는 최대 20.7TB의 HBM3e, 706TB/s의 메모리 대역폭, 362 MXFP8 PFLOP을 제공해 Trn2 UltraServer 대비 최대 4.4배 우수한 성능, 4배 이상의 에너지 효율을 제공합니다. Trn3는 최신 1T+ 파라미터 MoE 및 추론형 모델을 사용한 추론 시 훈련 및 추론 비용이 가장 적고, Trainium2 기반 인스턴스 대비 대규모 GPT-OSS 서비스에서 훨씬 많은 처리량을 제공합니다.
Trn2 UltraServer는 여전히 생성형 AI 훈련 및 추론을 위한 고성능, 비용 효율적 옵션입니다(단, 최대 1T 파라미터 모델에 한함). Trn2 인스턴스는 최대 16개의 Trainium2 칩을 탑재하며, Trn2 UltraServer는 독자적인 칩 간 상호 연결 기술인 NeuronLink로 연결된 최대 64개의 Trainium2 칩을 탑재합니다.
Trn1 인스턴스는 최대 16개의 Trainium 칩을 탑재하며, 최대 3 FP8 PFLOP, 512GB의 HBM,.9.8TB/s의 메모리 대역폭 및 최대 1.6Tbps의 EFA 네트워킹을 제공합니다.
AWS Neuron SDK를 사용하면 Trn3, Trn2 및 Trn1 인스턴스에서 최대 성능을 추출할 수 있으므로 모델을 구축 및 배포하고 출시 시간을 단축하는 데 집중할 수 있습니다. AWS Neuron은 PyTorch, JAX, 그리고 Hugging Face, vLLM, PyTorch Lightning 같은 필수 라이브러리와 기본적으로 통합됩니다. 분산 훈련 및 추론을 위해 즉시 모델을 최적화하는 동시에 프로파일링 및 디버깅에 대한 심층적인 인사이트를 제공합니다. AWS Neuron은 Amazon SageMaker, Amazon SageMaker Hyerpod, Amazon Elastic Kubernetes Service(Amazon EKS), Amazon Elastic Container Service(Amazon ECS), AWS ParallelCluster, AWS Batch 등의 서비스는 물론 Ray(Anyscale), Domino Data Lab, Datadog 같은 서드 파티 서비스와 통합됩니다.
정확도 목표를 충족하면서도 뛰어난 성능을 제공하기 위해, AWS Trainium은
BF16, FP16, FP8, MXFP8 및 MXFP4 같은 다양한 혼합 정밀도 데이터 유형을 지원합니다. 생성형 AI의 빠른 혁신 속도를 지원하기 위해,
Trainium2와와 Trainium3는 4배 희소성(16:4), 마이크로 스케일링, 확률적 반올림과 전용 집단 엔진에 대한
하드웨어 최적화를 제공합니다.
Neuron을 사용하면 개발자는 커널 개발에 Neuron Kernel Interface(NKI)를 사용하여 워크로드를 최적화할 수 있습니다. NKI는 Trainium ISA 전체를 노출하기 때문에 명령어 수준 프로그래밍, 메모리 할당 및 실행 스케줄링을 완벽하게 제어할 수 있습니다. 개발자는 자체 커널을 구축하고, 나아가 최적화된 커널을 배포할 수 있는 오픈 소스인 Neuron Kernel Library도 사용할 수 있습니다. 마지막으로, Neuron Explore는 전체 스택 가시성을 제공하여 개발자 코드를 하드웨어의 엔진에 연결합니다.
고객
Anthropic, Decart, poolside, Databricks, Ricoh, Karakuri, SplashMusic과 같은 고객이 Trn1, Trn2, Trn3 인스턴스와 UltraServer의 성능과 비용 이점을 실현하고 있습니다.
Trn3의 얼리 어답터들은 차세대 대규모 생성형 AI 모델에 필요한 새로운 수준의 효율성과 확장성을 달성하고 있습니다.

AI 성능, 비용, 규모 확보

획기적인 AI 성능을 위한 AWS Trainium2

AWS AI 칩 고객 사례

