O blog da AWS
Lidando com bilhões de invocações — melhores práticas do AWS Lambda
Esta publicação foi escrita por Anton Aleksandrov, arquiteto principal de soluções da AWS Serverless e Rajesh Kumar Pandey, engenheiro principal do AWS Lambda.
O AWS Lambda é um serviço de computação Serverless altamente escalável e resiliente. Com mais de 1,5 milhão de clientes ativos mensais e dezenas de trilhões de invocações processadas, a escalabilidade e a confiabilidade são dois dos princípios de serviço mais importantes. Esta postagem fornece recomendações e insights para a implementação de aplicativos altamente distribuídos com base na experiência da equipe de serviços do Lambda na criação de seu sistema robusto e assíncrono de processamento de eventos. Ele aborda os desafios que você pode enfrentar, as técnicas de solução e as melhores práticas para lidar com vizinhos barulhentos.
Visão geral
Os desenvolvedores que criam aplicativos Serverless criam funções do Lambda para executar seu código na nuvem. Depois de carregar o código, as funções são invocadas usando o modo síncrono ou assíncrono.
As invocações síncronas são normalmente usadas para aplicativos interativos que esperam respostas imediatas, como APIs da web. O serviço Lambda recebe a solicitação de invocação, invoca o manipulador (handler) da função, espera pela resposta do manipulador e a retorna em resposta à solicitação original. Com as invocações síncronas, o cliente espera o retorno do manipulador de funções e é responsável por gerenciar os tempos limite e as novas tentativas de invocações com falha.

Figura 1. Diagrama de sequência de invocação síncrona
As invocações assíncronas permitem execuções de funções desacopladas. Os clientes enviam cargas para processamento sem esperar respostas imediatas. Isso é usado para cenários como processamento assíncrono de dados ou envios de pedidos/trabalhos. O serviço Lambda retorna imediatamente uma confirmação da invocação aceita e continua gerenciando outras invocações, tempos limite e novas tentativas do manipulador (handler) de forma assíncrona.
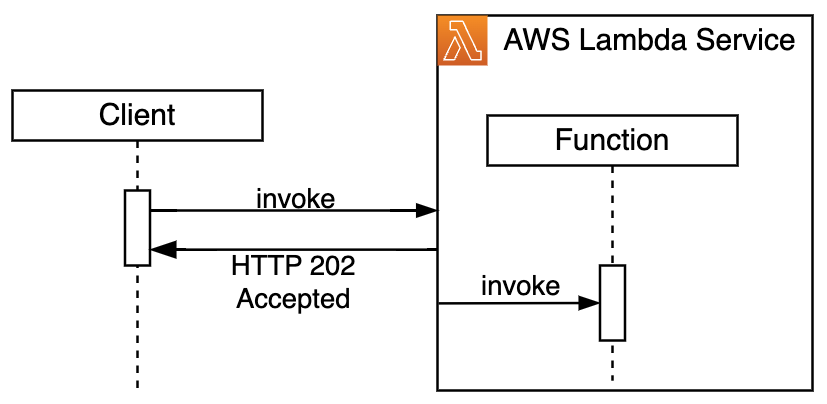
Figura 2. Diagrama de sequência de invocação assíncrona
Por dentro das invocações assíncronas
Para acomodar invocações assíncronas, o serviço Lambda coloca as solicitações em sua fila interna e retorna imediatamente o HTTP 202 ao cliente. Depois disso, um componente de pesquisa interno separado lê as mensagens da fila e invoca a função de forma síncrona.

Figura 3. Topologia de alto nível do fluxo de trabalho de invocações assíncronas
O mesmo sistema também cuida dos tempos limite (timeouts) e das novas tentativas em caso de handler exceptions. Quando a execução do código é concluída, o sistema envia a resposta do handler para o destino onSuccess ou onFailure, se configurado.

Figura 4. Diagrama de sequência detalhado do fluxo de trabalho de invocações assíncronas
A escalabilidade de sistemas altamente distribuídos para bilhões de solicitações assíncronas apresenta desafios únicos, como gerenciar vizinhos barulhentos e possíveis picos de tráfego para evitar a sobrecarga do sistema. As soluções variam de acordo com a escala — o que funciona para milhões de solicitações pode não atender bilhões. À medida que o tamanho da carga de trabalho aumenta, as soluções geralmente se tornam mais complexas e caras, portanto, o dimensionamento correto da abordagem é fundamental e deve evoluir com as mudanças nas necessidades.
Filas simples
Uma implementação simples de uma arquitetura assíncrona pode começar com uma única fila compartilhada. Essa é uma abordagem comum para muitos sistemas assíncronos, principalmente nos estágios iniciais. É eficaz quando você não está preocupado com o isolamento do tenant e quando o planejamento da capacidade indica que uma única fila pode lidar com o tráfego de entrada estimado de forma eficiente.

Figura 5. Fluxo de trabalho assíncrono com uma única fila
Mesmo com essa configuração simples, é fundamental instrumentar sua solução de observabilidade para detectar possíveis problemas o mais rápido possível. Você deve monitorar métricas importantes, como tamanho da lista de pendências da fila, tempo de processamento e erros, para indicar precocemente a capacidade de processamento insuficiente. Períodos de picos de tráfego inesperados e desempenho degradado podem ser um sinal de que você tem vizinhos barulhentos afetando outros tenants.
Para resolver isso, você pode escalar sua solução horizontalmente. Você pode implementar a colocação aleatória de solicitações em várias filas para distribuir a carga. O uso de um serviço Serverless como o Amazon SQS permite que você adicione e remova facilmente filas sob demanda. Um benefício notável dessa abordagem é sua simplicidade — você não precisa introduzir nenhum mecanismo de roteamento complexo; as solicitações são distribuídas uniformemente pelas filas. A desvantagem é que você ainda não tem limites de tenants. À medida que seu sistema cresce, tenants de alto volume e vizinhos barulhentos podem afetar potencialmente todas as filas, afetando assim todos os tenants.

Figura 6. Fluxo de trabalho assíncrono com várias filas e colocação aleatória de solicitações
Particionamento inteligente com hashing consistente
Para reduzir ainda mais o impacto potencial, você pode particionar seus tenants usando a atribuição fixa de tenants a partição com uma técnica de hash, como hash consistente. Esse método usa uma função hash para atribuir cada tenant a uma fila em um anel de hash consistente.

Figura 7. Fluxo de trabalho assíncrono com várias filas e posicionamento consistente do hashing
Essa técnica garante que tenants individuais permaneçam em suas partições de fila sem o risco de perturbar todo o sistema. Isso ajuda a resolver o problema em que alguns vizinhos barulhentos têm o potencial de sobrecarregar todas as filas e, como tal, afetar todos os outros tenants.
A abordagem consistente de hashing provou ser eficiente e permitiu que a Lambda oferecesse um desempenho robusto de invocação assíncrona aos clientes. À medida que o volume de tráfego e o número de clientes continuavam a crescer, a equipe de serviços da Lambda criou uma técnica inovadora de fragmentação aleatória para otimizar ainda mais a experiência e eliminar proativamente quaisquer possíveis problemas com vizinhos ruidosos.
Shuffle-sharding
Inspirando-se no artigo “The Power of Two Random Choices”, a equipe do Lambda explorou a técnica de shufle-sharding para o processamento assíncrono de invocações. Usando essa técnica, você divide os tenants em várias filas atribuídas aleatoriamente. Ao receber uma invocação assíncrona, você coloca a mensagem na fila com a menor lista de pendências para otimizar a distribuição da carga. Essa abordagem ajuda a minimizar a probabilidade de atribuir tenants a uma fila ocupada.

Figura 8. Fluxo de trabalho assíncrono com várias filas e posicionamento por shuffle-sharding
Para ilustrar o benefício dessa abordagem, considere um cenário em que você está usando 100 filas. A fórmula a seguir ajuda a calcular o número de shards unicos de fila (combinações), em que n é o número total de filas e r é o tamanho do shard (o número de filas que você está atribuindo por tenant).

Com n=100, r=2 (cada tenant é atribuído aleatoriamente a 2 das 100 filas), você obtém 4.950 combinações exclusivas (shards). A probabilidade de dois tenants serem atribuídos exatamente ao mesmo shard é de 0,02%. No caso de r=3, o número de combinações aumenta para 161.700. A probabilidade de dois tenants serem atribuídos exatamente ao mesmo shard cai para 0,0006%.
A técnica de shuffle-sharding mostrou-se extremamente eficaz. Ao distribuir os tenants em shards, a abordagem garante que apenas um subconjunto muito pequeno de tenants possa ser afetado por um vizinho barulhento. O impacto potencial também é minimizado, pois cada tenant afetado mantém o acesso às filas não afetadas. À medida que suas cargas de trabalho crescem, aumentar o número de filas aumenta a resiliência e reduz ainda mais a probabilidade de vários tenants serem atribuídos ao mesmo shard. Isso reduz significativamente o risco de um único ponto de falha, tornando o shuffle-sharding uma estratégia robusta para isolamento da carga de trabalho e tolerância a falhas.
Detecção proativa, isolamento automatizado, isolamento
Muitos serviços distribuídos terão uma grupo de tenants com tráfego de invocação assíncrona com picos verdadeiros. Isso pode ser causado por fatores sazonais, como compras de fim de ano ou processamento periódico em lotes. Reconhecendo essas necessidades comerciais reais, não ações maliciosas, você também deseja melhorar a qualidade do serviço para esses tenents, mantendo a estabilidade geral do sistema. Por exemplo, você pode melhorar ainda mais o desempenho da solução monitorando continuamente a profundidade da fila para detectar picos de tráfego e rotear o tráfego para filas dedicadas alocadas dinamicamente. Quando você usa invocações assíncronas do Lambda, essa complexidade interna é gerenciada para você pelo serviço, garantindo uma experiência de consumo perfeita.

Figura 9. O tenant D é automaticamente realocado para uma fila dedicada
Resiliência e tratamento de falhas
“Tudo falha, o tempo todo” é uma frase famosa do diretor de tecnologia da Amazon, Werner Vogels. A arquitetura distribuída e resiliente do Lambda foi criada para suportar possíveis interrupções de suas dependências e componentes internos, a fim de limitar as consequências para os clientes. Especificamente para o processamento de invocação assíncrona, o serviço de front-end cria um backlog de processamento durante uma interrupção, permitindo que o back-end se recupere gradualmente sem perder nenhuma mensagem em andamento.

Figura 10. O serviço Lambda mantém a resiliência durante a interrupção do componente
Após a recuperação, o serviço aumenta gradualmente o tráfego para processar a lista de pendências acumulada. Durante esse período, existem mecanismos automatizados para coordenar os componentes do sistema, evitando inadvertidamente o próprio DDoSing.
Para melhorar ainda mais o processo de aceleração da recuperação e fornecer uma restauração suave das operações normais, o serviço Lambda usa a técnica de redução de carga para garantir a alocação justa de recursos durante a recuperação. Ao tentar drenar o backlog o mais rápido possível, o serviço garante que nenhum cliente acabe consumindo uma grande parte dos recursos disponíveis. A adoção dessas técnicas pode ajudá-lo a melhorar seu tempo médio de recuperação (MTTR).
Observabilidade para processamento de invocações assíncronas
Ao usar o serviço Lambda para processamento assíncrono, você deseja monitorar suas invocações quanto à consciência situacional e possíveis lentidões. Use métricas como AsyncEventReceived, AsyncEventage e AsyncEventDropped para obter insights sobre o processamento interno.
AsyncEventReceived rastreia o número de invocações assíncronas que o serviço Lambda conseguiu enfileirar com sucesso para processamento. Uma queda nessa métrica indica que as invocações não estão sendo entregues ao serviço Lambda e você deve verificar sua fonte de invocação. Os possíveis problemas incluem configurações incorretas, permissões de acesso inválidas ou limitação. Verifique a configuração da fonte de invocação, os registros e a política de recursos da função para uma análise mais aprofundada.
O AsyncEventage rastreia quanto tempo uma mensagem passou na fila interna antes de ser processada por uma função. Essa métrica aumenta quando o processamento de invocações assíncronas é atrasado devido à concorrência insuficiente, falhas de execução ou limitações. Aumente a concorrência de funções para processar mais invocações assíncronas ao mesmo tempo e otimizar o desempenho da função para melhorar a taxa de transferência, ou seja, aumentando a alocação de memória para adicionar mais capacidade de vCPU. Experimente ajustar o tamanho do lote para permitir que as funções processem mais mensagens ao mesmo tempo. Use registros de invocação para identificar se o problema é causado pelo código da função gerando exceções. Verifique as métricas de limitadores e erros para uma análise mais aprofundada.
AsyncEventDropped rastreia o número de mensagens na fila interna que foram descartadas porque o Lambda não conseguiu processá-las. Isso pode ser devido à limitação, ao excesso do número de novas tentativas, ao excesso da idade máxima da mensagem ou ao lançamento de uma exceção pelo código da função. Configure o destino OnFailure ou uma fila de mensagens sem saída para evitar a perda de dados e salvar as mensagens descartadas para reprocessamento. Use registros de funções e métricas descritos acima para investigar se você pode resolver o problema aumentando a simultaneidade de funções ou alocando mais memória.
Ao monitorar essas métricas e abordar os problemas subjacentes, você pode garantir que suas funções do Lambda funcionem sem problemas, com o mínimo de atrasos e falhas no processamento de eventos. Você também pode habilitar o rastreamento do AWS X-Ray para capturar rastreamentos de serviços do Lambda. O segmento de rastreamento AWS: :Lambda captura o detalhamento do tempo que o serviço Lambda gasta roteando solicitações para filas internas, o tempo que uma mensagem passa em uma fila e o tempo antes de uma função ser invocada. Essa é uma ferramenta poderosa para obter insights sobre o processamento interno do Lambda.
Conclusão
O AWS Lambda processa dezenas de trilhões de invocações mensais em mais de 1,5 milhão de clientes ativos, demonstrando sua escalabilidade e resiliência excepcionais. Compreender os mecanismos subjacentes dos serviços da AWS, como o Lambda, permite que você enfrente proativamente possíveis desafios em seus próprios aplicativos. Ao aprender como esses serviços lidam com o tráfego, gerenciam recursos e se recuperam de falhas, você pode incorporar recursos semelhantes às suas próprias soluções. Por exemplo, aproveitar as métricas de invocação assíncrona do Lambda permite otimizar o desempenho do fluxo de trabalho. Esse conhecimento permite que você implemente estratégias como escalabilidade automatizada, monitoramento proativo e recuperação eficiente durante interrupções.
Veja abaixo os recursos para aprender sobre o uso de filas e shuffle-sharding em grande escala na Amazon
- Evitando atrasos de filas insuperáveis
- Isolamento da carga de trabalho usando fragmentação aleatória no Route53
- Melhore a resiliência da carga de trabalho usando fragmentação aleatória
- Shuffle Sharding: isolamento massivo e mágico de falhas
Para saber mais sobre arquiteturas serverless e padrões de invocação assíncrona do Lambda, consulte Serverless Land.
Este blog é uma tradução do conteúdo original em inglês (link aqui).
Biografia dos Autores
 |
Anton Aleksandrov, Principal Solutions Architect, AWS Serverless |
 |
Rajesh Kumar Pandey, Principal Engineer, AWS Lambda |
Biografia do Tradutor
 |
Rodrigo Peres é Arquiteto de Soluções na AWS, com mais de 20 anos de experiência trabalhando com arquitetura de soluções, desenvolvimento de sistemas e modernização de sistemas legados. |
Biografia do Revisor
 |
Daniel Abib é arquiteto de soluções sênior na AWS, com mais de 25 anos trabalhando com gerenciamento de projetos, arquiteturas de soluções escaláveis, desenvolvimento de sistemas e CI/CD, microsserviços, arquitetura Serverless & Containers e segurança. Ele trabalha apoiando clientes corporativos, ajudando-os em sua jornada para a nuvem. |