O blog da AWS
Nuvemshop com Amazon Aurora: migração com rollback e menor custo
Por Ricardo Mantovani – DBRE Manager; João Rito DBRE; Rafael Dantas DBRE e Vinícius Aragão – DBRE.
Neste artigo, você vai descobrir como a Nuvemshop migrou uma carga crítica do Amazon RDS for MySQL para Amazon Aurora MySQL-Compatible Edition, mantendo a continuidade de negócio durante todo o processo. A empresa utilizou ProxySQL para roteamento de conexões e o AWS Database Migration Service (AWS DMS) Serverless para captura contínua de dados (CDC), o que permitiu criar um plano de reversão mensurável. Além do ganho operacional, a arquitetura orientada à nuvem permitiu reduzir duas classes de instância e diminuir os custos em aproximadamente 40% em relação ao trimestre anterior, preservando os níveis de disponibilidade e desempenho exigidos pelos aplicativos. Os resultados podem variar conforme o contexto, a arquitetura e as configurações específicas.
Este foi o playbook da Nuvemshop de como escalar com confiança, com rota de fuga pronta e foco total no cliente.
Sobre a Nuvemshop
A Nuvemshop é a empresa de e-commerce líder na América Latina com o compromisso de potencializar e motivar todos, desde empreendedores que estão começando, até marcas que já faturam milhões, a transformarem seus sonhos em histórias que transcendam. Com mais de 170 mil lojas, integra produtos, pagamentos, envios, automação de marketing, inteligência artificial (IA) e disponibiliza uma rede com mais de 4.000 parceiros, como Facebook, Instagram, marketplaces e lojas físicas. Atualmente, a companhia tem mais de 1.300 colaboradores e operações no Brasil, México, Argentina, Colômbia e Chile. Oferecemos serviços resilientes, segurança por padrão e dados em tempo real que sustentam picos de Black Friday com tranquilidade, enquanto a governança para múltiplas operações mantém o controle simples. Você lança rápido, cresce sem fricção e decide com clareza. A Nuvemshop projetou a plataforma para transformar os sonhos daqueles que vendem direto ao consumidor, em resultados. Sua marca cresce. Nossas soluções evoluem junto.
Nossa motivação é clara: o cliente no centro. Assumimos responsabilidade de ponta a ponta e, aqui, o problema tem dono. Nossa clareza operacional é respaldada por documentação sólida, testes abrangentes e dashboards interativos e acessível a todos, em qualquer idioma e sotaque, debatemos com dados e decidimos rápido. Pensamos grande, mirando padrões globais; executamos com excelência e mantemos humildade para aprender e construir confiança. Trabalhamos em equipe para que todos performem melhor, em um ambiente inspirador que não perdeu a veia de startup, rápido, colaborativo e inconformado. Esses princípios nos guiam do primeiro pedido ao próximo salto.
O desafio: escalar sem perder o ritmo
Operamos nossos bancos de dados na AWS, em Amazon Relational Database Service (Amazon RDS) for MySQL. Para uma startup, faz total sentido: serviço gerenciado, snapshots automáticos, Multi-AZ para resiliência, segurança aprimorada via security group e Amazon Virtual Private Cloud (Amazon VPC) é um caminho claro de crescimento. Nos últimos 4 anos, conseguiu atender aos requisitos de performance, a aplicação era mais monolítica, 1 instância era adequada para lidar com o tráfego e a latência seguia estável.
Conforme a base de lojistas e pedidos cresceram, escalamos de forma pragmática em todos os nossos bancos de dados. Primeiro verticalmente (classes maiores, armazenamento com IOPS provisionado), depois horizontalmente com read replicas para aliviar consultas pesadas e relatórios. Adotamos o ProxySQL e utilizamos diversos de seus recursos: roteamento de leitura/escrita por um único endpoint, pooling de conexões com multiplexação e cache de prepared statements, otimizamos índices e queries críticas. Ainda assim, durante cargas mais intensas, o replication lag aumentava, ainda sob controle.
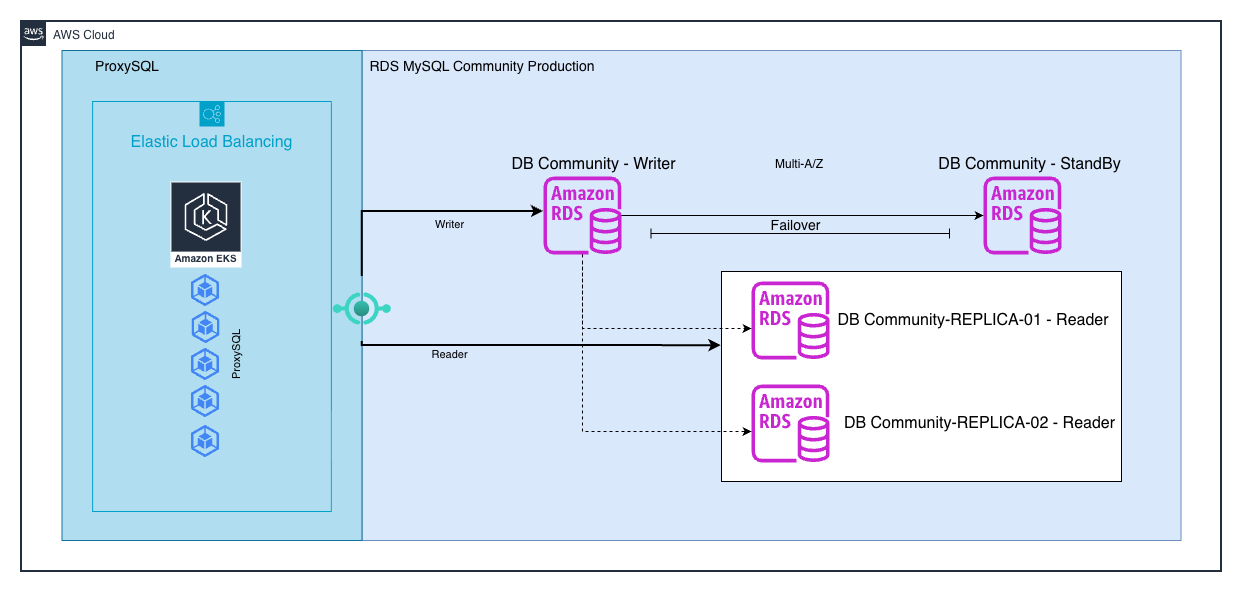
Imagem 1: Amazon RDS for MySQL + ProxySQL – Arquitetura Padrão Escrita e Leitura
Até que o crescimento atingiu um novo patamar de complexidade e se tornou um novo problema de engenharia. Aplicações críticas passaram a exigir de nossos bancos de dados, como picos de conexões e I/O. Os nós primários, em topologias único escritor, começaram a sentir contenção (flush de páginas, disputa por disco); os buffer pools sofriam com churn e as filas de queries cresciam justamente nos momentos que mais importavam. Quando era necessário o restore no Amazon RDS for MySQL (snapshots + replay de binlogs) o recovery time objective (RTO) era mais longo ainda que dentro do requerimento de negócio, e o failover demandava sincronização de logs que durava pelo menos 2 minutos, que significavam carrinhos abandonados e pedidos perdidos, algo que o negócio gostaria de evitar.
Esse foi o ponto de inflexão: a arquitetura original nos trouxe até ali com segurança, mas o próximo salto exigia mais escala de I/O, failover mais rápido e menor lag de replicação, sem perder a capacidade de voltar atrás em minutos se algo desse errado.
A solução: Amazon Aurora no centro, arquitetura construída para a nuvem de ponta a ponta
O planejamento inicial indicava uma abordagem direta: adotar Amazon Aurora MySQL-Compatible Edition e colher os ganhos de uma arquitetura construída para a nuvem. No mundo real, tínhamos mais de 280 bancos de dados, serviços com históricos diferentes e uma coleção de ferramentas open source que já nos ajudavam a operar no dia a dia. O plano foi colocar o Amazon Aurora no coração da infraestrutura e orquestrar o entorno para extrair o melhor do motor sem perder o que já funcionava.
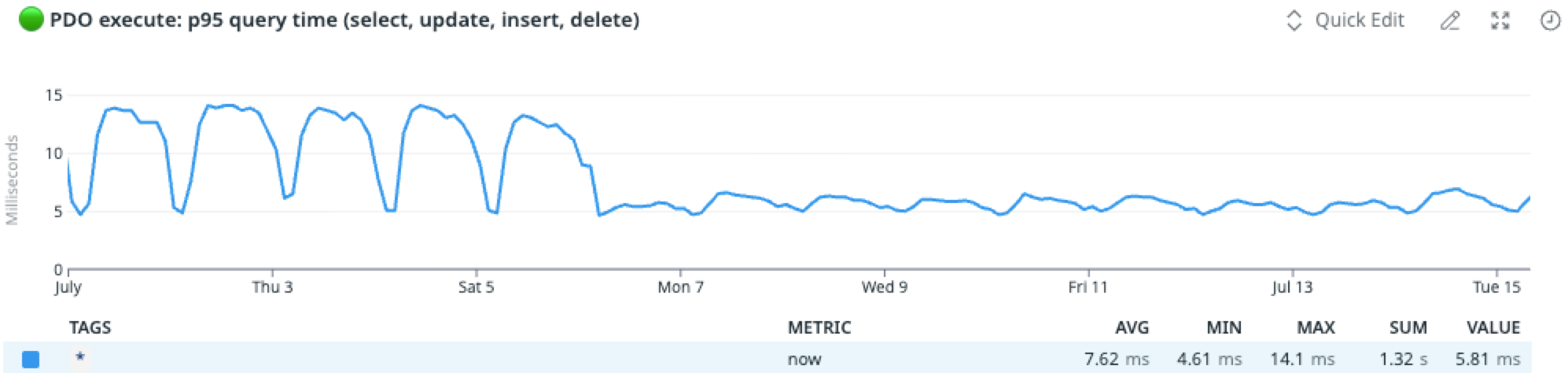
Imagem 2: Amazon RDS for MySQL vs Amazon Aurora – p95 de todas as operações de banco
No meio do caminho, vale explicar o “porquê” técnico. Amazon Aurora é um banco de dados gerenciado compatível com MySQL, que combina a velocidade e disponibilidade de bancos comerciais com a economia de bancos open source, mas com um desenho próprio de armazenamento distribuído e separado dos recursos de computação. Isso significa que o cluster replica os dados nativamente entre zonas de disponibilidade, com réplicas de leitura com lag mínimo e um endpoint de leitura que absorve tráfego sem acoplar tudo ao escritor. Na prática, obtivemos latência mais estável, escala elástica de leitura e failover auto gerenciado sem depender de longos replays de binlogs para voltar ao ar. Com backups contínuos e restauração pontual (PITR), o Amazon Aurora tornou o tempo de restore mais previsível. O resultado que obtivemos foi melhor performance e escalabilidade, com maior previsibilidade operacional.
Compondo a arquitetura com Amazon Aurora, mantivemos nosso ProxySQL, um proxy de nível SQL (camada 7) que provê pooling e multiplexação de conexões, roteamento baseado em regras de leitura/escrita, regras por usuário/esquema/regex e failover otimizado. Isso reduz picos de conexão nos nossos bancos de dados, centraliza decisões de roteamento e torna a troca de papéis (escritores vs leitores) de forma transparente para as aplicações. Com o Amazon Aurora, o ProxySQL oferece funcionalidades adicionais: direciona leituras intensivas para o endpoint de leitura, mantém stickiness quando precisamos de consistência, e diminui picos para que o cluster não sofra com picos de conexões vindas de centenas de pods e processos diferentes.
Com esta arquitetura, atacamos quatro objetivos de negócio e engenharia ao mesmo tempo: melhorar performance e escalabilidade dos nossos bancos de dados, reduzir risco operacional com failovers e restores mais rápidos, adotar uma arquitetura construída para a nuvem alinhada às boas práticas da AWS e diminuir os custos operacionais antes necessários em Amazon RDS for MySQL. Menos tempo “cuidando” de réplicas e replays; mais tempo evoluindo produto, confiabilidade e experiência.
Quem cuida dos nossos bancos de dados: nasce o time de DBRE
Para sustentar a próxima fase de crescimento, formamos um novo time de DBRE (Database Reliability Engineering) da Nuvemshop. A missão é direta e ambiciosa: alta disponibilidade, resiliência e performance, modernizando todo o nosso parque de bancos de dados com padrões construídos para a nuvem, automações e observabilidade de ponta a ponta. É o grupo que trata banco de dados como produto, com visão de ciclo de vida, SLOs claros e mudanças seguras.
Nossa equipe é nova, mas chega com lastro. Reúne experiência em empresas entre as 30 maiores do Brasil e startups, com 3 dos 4 membros vindos do mercado financeiro, acostumada a cerca de 520 milhões de transações diárias e ambientes complexos onde cada milissegundo conta. Esse repertório se traduz em práticas maduras: planejamento de capacidade, tuning de queries e esquemas, engenharia do caos e simulações de restore, runbooks versionados, post-mortems objetivos e uma cultura de melhoria contínua.
Na prática, nosso time DBRE é o “cérebro operativo” por trás do nosso movimento para Amazon Aurora, ProxySQL e uma base construída para a nuvem na AWS. Define guardrails (limites de conexão, timeouts, split de leitura/escrita), padroniza, automatiza, configura Multi-AZ, AWS Key Management Service (AWS KMS), backups contínuos e PITR, e garante observabilidade medindo o que importa: latência p95/p99, throughput, replication lag, waits e erros da aplicação. Quando é hora de mudar, fazemos com segurança: blue/green, canário, rollback em minutos e cache aquecido para evitar “choques” pós-cutover.
O resultado são nossos bancos de dados mais previsíveis, custos operacionais menores e uma infraestrutura que aguenta picos de tráfego intenso em datas como a Black Friday.
Do laboratório ao tráfego real: o método DBRE
Primeiramente precisávamos arrumar a casa. Atualizamos as versões antigas do ProxySQL para uma release mais recente, compatível com Amazon Aurora e livre de bugs conhecidos que afetam nosso cenário. Essa etapa pode parecer simples, mas foi essencial: padronizamos a configuração, avaliamos regras de roteamento e garantimos que o proxy tivesse o comportamento esperado em alto volume, com health checks confiáveis e pooling estável.
Em seguida, configuramos o cluster Amazon Aurora com nós de escrita e leitura, porém o tratamos, nessa fase, como um destino de leitura controlada. Parametrizamos o ambiente para impedir qualquer escrita acidental no escritor do Amazon Aurora durante o aquecimento. Combinando parâmetros, permissões e guardrails de rede, reproduzimos o footprint de produção para que índices, estatísticas e comportamento de cache fossem os mais fiéis possíveis. A ideia era simples: preparar o “motor” novo sem causas impactos no ambiente produtivo.
Com o ProxySQL atualizado, criamos uma configuração “bi-modal”, capaz de entender Amazon Aurora e Amazon RDS for MySQL ao mesmo tempo. Mapeamos cada backend em seus hostgroups e usamos a funcionalidade de pesos nos leitores para dosar o tráfego real de produção. Começamos enviando uma carga de 10% de leituras para o leitor do Amazon Aurora, o suficiente para esquentar o cache sem arriscar a estabilidade. À medida que os gráficos evidenciavam latência e waits no lugar, elevamos gradualmente o peso até completar o warmup, momento em que toda a leitura passou a ir para a réplica do Amazon Aurora.
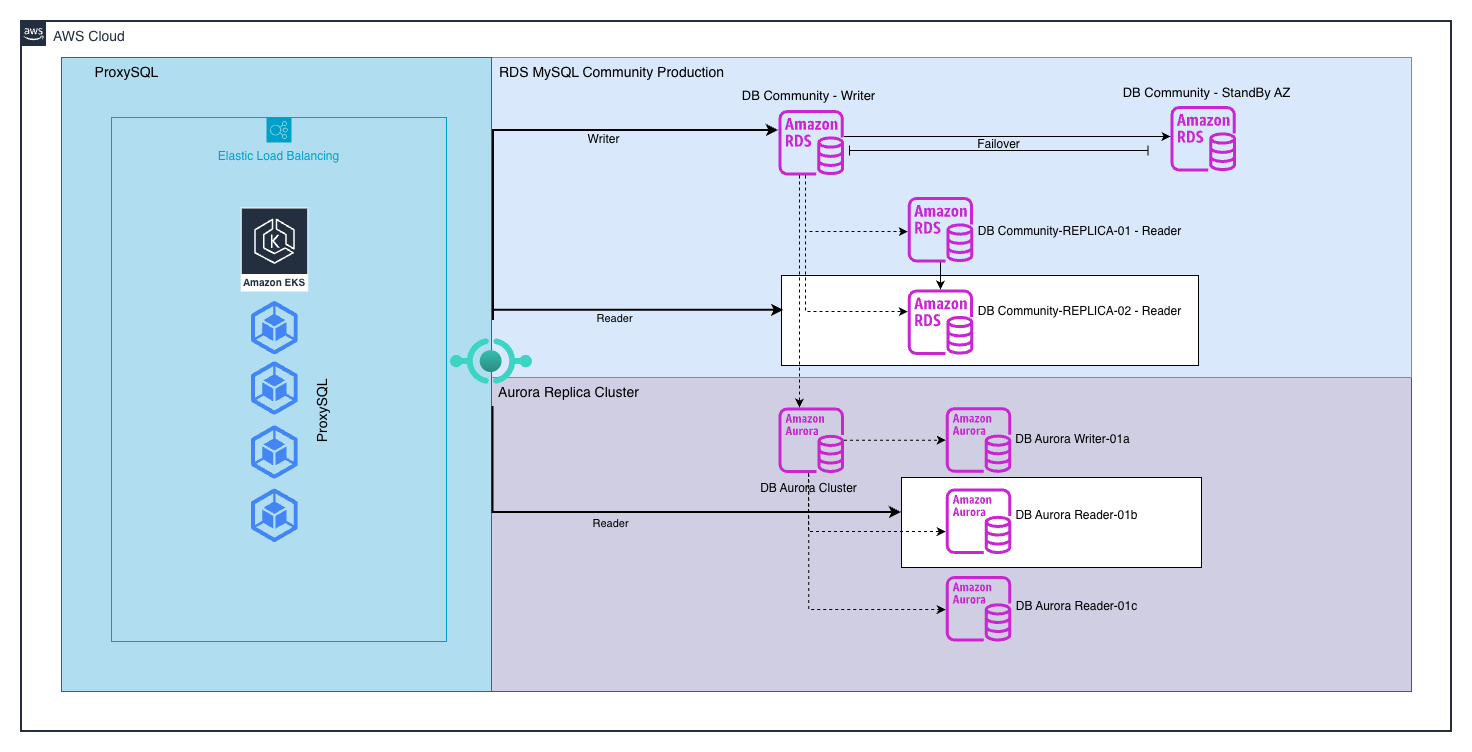
Nesse ponto, o arranjo ficou assim (imagem 3): Usando um único endpoint do ProxySQL que lida tanto com a forte consistência e com a consistência eventual graças às nossas parametrizações, as escritas continuavam no primary do Amazon RDS for MYSQL, enquanto as leituras eram balanceadas entre duas réplicas, uma no Amazon RDS for MySQL e outra no Amazon Aurora. Essa configuração nos permitiu um teste A/B real de leitura antes da migração: as mesmas queries, sob as mesmas cargas e com pesos iguais, rodando em paralelo. Medimos tempos p95/p99 com ajuda dos times de desenvolvimento, waits e comportamentos de plano, comparando réplica contra réplica em produção, não em laboratório. Em uma semana rodando assim, ganhamos exatamente o que buscamos: confiança técnica necessária para dizer que compatibilidade, estabilidade e performance estavam onde precisavam estar.
Com leitura validada em campo e cache quente no destino, restava o último passo: o cutover de escrita, mantido sob o mesmo princípio de prudência, mudança orquestrada via ProxySQL, observabilidade de ponta a ponta e rollback facilitado se qualquer métrica saísse do planejado.
Criando um rollback seguro do Amazon Aurora para Amazon RDS for MySQL
Havia algo primordial que precisávamos garantir, e foi justamente o que não encontrávamos documentado em lugar nenhum, o que nos motivou a escrever este blog: como voltar do Amazon Aurora para Amazon RDS for MySQL em minutos, caso algo falhasse após o cutover. Em ambientes menos complexos, um plano de rollback para o Amazon RDS for MySQL pode levar horas sem impacto ao negócio. Entretanto, em um ambiente complexo como o nosso ambiente em questão, a história é outra. Consultamos a AWS, conversamos com consultores e a resposta foi honesta: não há solução automatizada oficial documentada para garantir o rollback do Amazon Aurora para Amazon RDS for MySQL em produção.
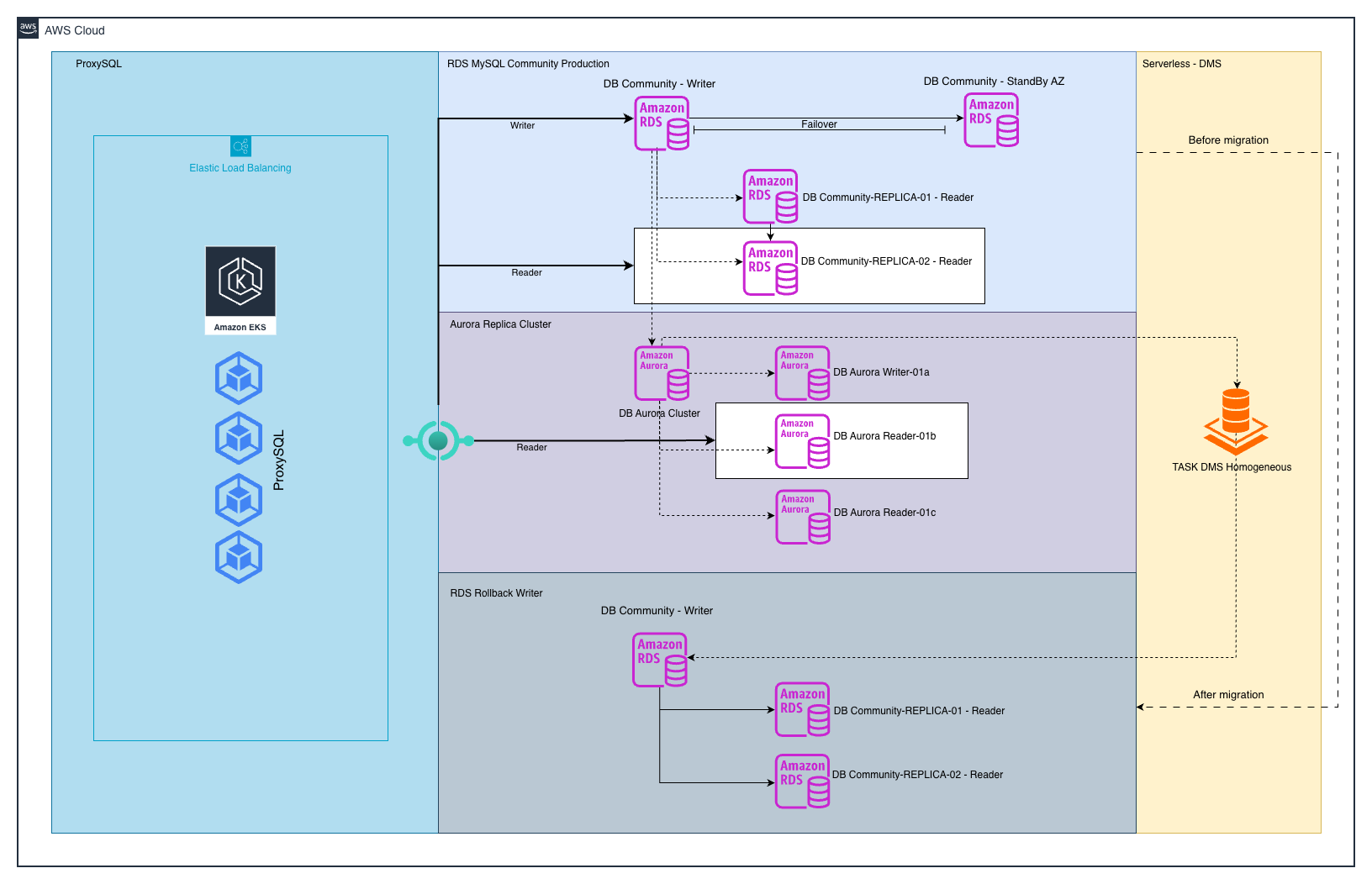
Imagem 4 – Garantindo o Rollback – Aurora primary replicando para um RDS standalone
O nosso trunfo foi adotar o AWS DMS Serverless para migração homogênea que é um produto relativamente novo. Em termos simples, migração homogênea é quando a origem e o destino usam o mesmo engine (MySQL → MySQL). O AWS DMS Serverless lê as mudanças diretamente do binlog e as reproduz no destino, mantendo tipos de dados idênticos. Já na migração heterogênea, na versão clássica do AWS DMS Serverless existe um trabalho de conversão de tipos e transformações de dados que aumenta a superfície de risco. Para Rollback, a fidelidade dos tipos faz toda a diferença: não queríamos descobrir, no meio de um retorno emergencial, que um “decimal(12,2)” virou “numeric(12,3)” em algum ponto do caminho ou algo do tipo.
Com isso em mente, desenhamos a volta antes mesmo de virar a chave. Criamos uma nova instância Amazon RDS for MySQL para receber a replicação de rollback e montamos os fluxos de replicação via AWS DMS Serverless.
Imediatamente após o corte: invertemos a direção para iniciar a replicação de rollback. O Amazon Aurora (agora escritor**)** passou a replicar para o Amazon RDS for MySQL recém-criado de uma réplica do Amazon RDS for MySQL primary. Assim, se qualquer métrica saísse do trilho, bastava apertar o rollback, apontar o ProxySQL de volta para o Amazon RDS for MySQL e seguir vendendo com recovery point objective (RPO) mínimo e recovery time objective (RTO) de minutos.
Na prática, o downtime do corte ficou abaixo de 5 minutos. O ProxySQL já estava preparado para entender, ao mesmo tempo, o Amazon Aurora e o Amazon RDS for MySQL, e manter as rotas sob controle. Seguimos com o AWS DMS Serverless ligado por mais uma semana, comparando leituras, observando waits, latências p95/p99 e consistência de dados entre as pontas. Ter um processo de rollback real e testado nos deu a confiança que faltava: em caso de falhas não teríamos impacto de dias, seria um procedimento rápido.
Esse foi o nosso diferencial: usar AWS DMS Serverless homogêneo para um rollback íntegro, enquanto o ProxySQL orquestrava a troca de papéis sem espalhar complexidade para os serviços.
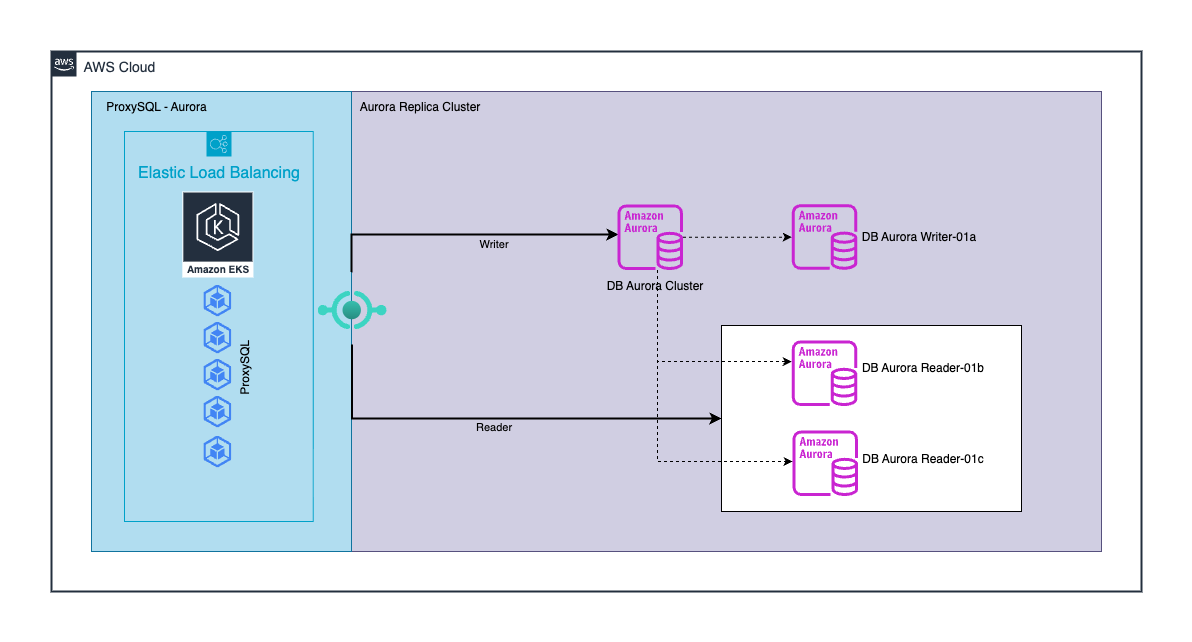
Imagem 5 – Arquitetura Final – Migração Amazon RDS for MySQL para Amazon Aurora com mínimo Downtime
Resultados em números
Nossa virada para Amazon Aurora + ProxySQL (com rollback homogêneo via AWS DMS Serverless em minutos) trouxe não somente benefícios de arquitetura: mas também performance, resiliência e otimização de custo.

Imagem 6 – Resultados da migração – performance e métricas
Mais disponibilidade, menor mean time to recovery (MTTR), leituras que escalam sob demanda e custo mais otimizado.
Nota: Os resultados de performance e otimização de custo apresentados refletem a experiência da Nuvemshop nesta migração, com sua arquitetura, carga de trabalho e configurações particulares. Os resultados podem variar dependendo de fatores como padrões de uso, configuração de aplicações, volume de dados e arquitetura específica de cada implementação.
Conclusão
No fim, esta jornada não é sobre trocar tecnologia; é sobre aumentar a confiança para crescer. Otimizamos a observabilidade, reduzimos o mean time to recovery (MTTR), estabilizamos latência em cenários de pico, ganhamos a segurança operacional e otimizamos o custo em cerca de 40% através da redução das classes de instância necessárias para nossa carga de trabalho.
É a combinação de arquitetura construída para a nuvem com disciplina de DBRE: decisão rápida com segurança e excelência na execução, com foco na priorização da continuidade do negócio.
O novo time de DBRE trouxe método, disciplina e coragem para simplificar o que era complexo. Na Nuvemshop, acreditamos que cada venda direta ao consumidor é muito mais do que uma transação: é a chance de construir uma marca forte, independente e dona do próprio destino. É com essa liberdade que nos movemos, com tecnologia confiável e escalável para que empreendedores cresçam livres, resilientes e preparados para conquistar o futuro que desejam.
Recursos adicionais para aprofundamento
Para quem deseja se aprofundar nos temas abordados neste artigo, recomendamos a consulta aos seguintes recursos oficiais da AWS:
O que é o Amazon Aurora? – Documentação completa sobre Amazon Aurora
O que é AWS Database Migration Service? – Guia completo para migrações de banco de dados
Práticas recomendadas do Amazon RDS – Melhores práticas para Amazon RDS
Pilar Confiabilidade: AWS Well-Architected Framework – Princípios de confiabilidade na AWS
Autores
 |
Ricardo Mantovani é DBRE Manager, com mais de 25 anos de experiência na área de bancos de dados, desenvolvimento de software, arquiteturas de soluções escaláveis, distribuídas, nativas da nuvem e orientadas a eventos. Entusiasta open source, especialista PostgreSQL e tendo um histórico de desenvolvimento de soluções empresariais, bem como experiência em grandes empresas e em várias startups, incluindo a experiência como sócio em uma startup do setor financeiro.
https://www.linkedin.com/in/ricardodsmantovani/ |
 |
João Rito é DBRE Staff, com sólida experiência em bancos de dados, desenvolvimento de software e automação de processos, atuando em ambientes de missão crítica nos setores financeiro e de e-commerce. Certificado como AWS Solutions Architect – Professional e AWS Database – Specialty, foi protagonista na adoção de tecnologias em nuvem, colaborando com design partners na criação de soluções personalizadas e escaláveis. Reconhecido por unir visão estratégica e profundidade técnica, apoia equipes de arquitetura e desenvolvimento de produtos com foco em inovação, confiabilidade e eficiência operacional. https://www.linkedin.com/in/joaovictorrito/
|
 |
Rafael Dantas é DBRE, com mais de 19 anos de experiência em TI, sendo os últimos 14 anos dedicados a projetos de bancos de dados. Especialista em bancos relacionais e não relacionais, atuou em ambientes on-premises e cloud, com foco em performance, automação e alta disponibilidade. Com passagem por grandes empresas dos setores financeiro e de mídia dando suporte a grandes eventos nacionais e internacionais, com milhões de transações simultâneas, contribuindo para maior escalabilidade, resiliência e otimização de custos de infraestrutura. Destaca-se pela experiência em ambientes críticos de alta escala e práticas modernas de administração de bancos de dados.
https://www.linkedin.com/in/rdantas-silva/
|
 |
Vinícius Hastenreiter é DBRE, com mais de 15 anos de experiência em administração de bancos de dados, atuando em projetos de alta disponibilidade e ambientes de missão crítica nos setores financeiro e governamental. Certificado como PostgreSQL Advanced 16, possui profundo domínio em PostgreSQL, MySQL e SQL Server, além de sólida atuação em cloud computing. Já atuou em consultoria para instituições financeiras, promovendo melhores práticas e conduzindo iniciativas de recuperação em cenários de desastre. https://www.linkedin.com/in/viniciusahs/ |
 |
Gonzalo Vásquez é Senior Solutions Architect da AWS Chile para clientes do segmento Independent Software Vendor (ISV) da Argentina e Chile. Engenheiro Eletrônico especializado em Sistemas Computacionais e Digitais, com mais de 25 anos de experiência na indústria de tecnologia e 3 anos na AWS, antes de se juntar à AWS, atuou como desenvolvedor de software, arquiteto de sistemas, gerente de pesquisa e desenvolvimento e CTO em empresas baseadas no Chile. É Area of Depth (AoD) da Technical Field Community (TFC) de Sustentabilidade Ambiental da AWS, atuando como especialista no assunto (SME) neste domínio técnico. https://www.linkedin.com/in/gvasquez/ |