Что такое конвейер данных?
Что такое конвейер данных?
Конвейер данных – это серия шагов по обработке, необходимых для подготовки корпоративных данных к анализу. Организации получают большой объем данных из различных источников, таких как приложения, устройства Интернета вещей (IoT) и другие цифровые каналы. Однако необработанные данные бесполезны; их нужно перемещать, сортировать, фильтровать, переформатировать и анализировать для бизнес-аналитики. Конвейер данных включает в себя различные технологии для проверки, обобщения и поиска закономерностей в данных для принятия обоснованных бизнес-решений. Хорошо организованные конвейеры данных поддерживают такие проекты на основе больших данных, как визуализация данных, поисковый анализ данных и машинное обучение.
Каковы преимущества конвейера данных?
Конвейеры данных позволяют интегрировать данные из различных источников и преобразовывать их для анализа. Они устраняют разрозненность данных и делают аналитику данных более надежной и точной. Ниже перечислены основные преимущества конвейера данных.
Улучшение качества данных
Конвейеры данных очищают и уточняют необработанные данные, повышая их полезность для конечных пользователей. Они стандартизируют форматы таких полей, как даты и номера телефонов, и проверяют ошибки ввода. Они также устраняют избыточность и обеспечивают постоянное качество данных в рамках всей организации.
Эффективная обработка данных
Инженерам по обработке данных приходится выполнять множество повторяющихся задач при преобразовании и загрузке данных. Конвейеры данных позволяют автоматизировать задачи по преобразованию данных и сосредоточиться на поиске наилучших возможностей для бизнеса. Конвейеры данных также помогают инженерам по обработке данных быстрее выполнять работу с исходными данными, которые со временем теряют свою ценность.
Комплексная интеграция данных
Конвейер данных абстрагирует функции преобразования данных для интеграции наборов данных из разрозненных источников. Система может перепроверять значения одних и тех же данных из нескольких источников и устранять несоответствия. Например, представьте, что один и тот же клиент совершает покупку на вашей платформе электронной коммерции и в вашем цифровом сервисе. Однако в цифровом сервисе они неправильно пишут свое имя. Конвейер может исправить это несоответствие перед отправкой данных для анализа.
Как работает конвейер данных?
Подобно тому, как по водопроводу вода поступает из резервуара в краны, по конвейеру данные поступают из точки сбора в хранилище. Конвейер данных извлекает данные из источника, вносит изменения, а затем сохраняет их в определенном месте назначения. Ниже мы расскажем о важнейших компонентах архитектуры конвейера данных.
Источники данных
Источником данных может быть приложение, устройство или другая база данных. Данные в конвейер могут поступать из разных источников. Конвейер может также извлекать точки данных с помощью вызова API, объекта webhook или процесса дублирования данных. Вы можете синхронизировать извлечение данных для обработки в режиме реального времени или собирать данные в запланированные интервалы времени из источников данных.
Преобразование
По мере прохождения необработанных данных по конвейеру они изменяются и становятся более полезными для бизнес-аналитики. Преобразования – это операции, такие как сортировка, переформатирование, дедупликация, проверка и валидация, которые изменяют данные. Ваш конвейер может фильтровать, обобщать или обрабатывать данные в соответствии с вашими требованиями к анализу.
Зависимости
Поскольку изменения происходят последовательно, могут существовать специфические зависимости, которые снижают скорость перемещения данных в конвейере. Существует два основных типа зависимостей – технические и деловые. Например, если конвейер должен ждать, пока центральная очередь заполнится, прежде чем приступить к работе, то это техническая зависимость. И наоборот, если конвейер должен приостановиться, пока другое бизнес-подразделение не проведет перекрестную проверку данных, то это зависимость от бизнеса.
Целевые объекты
Конечной точкой вашего конвейера данных может быть хранилище данных, озеро данных или другое приложение для бизнес-анализа или анализа данных. Иногда пункт назначения также называют получателем данных.
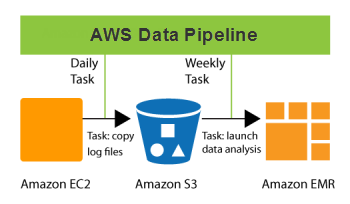
Какие существуют типы конвейеров передачи данных?
Существует два основных типа конвейеров обработки данных – конвейеры потоковой обработки и конвейеры пакетной обработки.
Рабочие нагрузки конвейеров
Поток данных – это непрерывная, инкрементная последовательность пакетов данных небольшого размера. Обычно он представляет собой серию событий, происходящих в течение определенного периода. Например, поток данных может показывать данные датчиков, содержащие измерения за последний час. Единичное действие, например, финансовая операция, также можно назвать событием. Потоковые конвейеры обрабатывают серию событий для анализа в режиме реального времени.
Потоковые данные требуют низкой задержки и высокой отказоустойчивости. Ваш конвейер данных должен быть способен обрабатывать данные, даже если некоторые пакеты данных потеряны или поступают не в том порядке, в котором ожидалось.
Конвейеры пакетной обработки
Конвейеры пакетной обработки данных обрабатывают и хранят данные в больших объемах или партиями. Они подходят для выполнения эпизодических задач с большим объемом работы, таких как ведение ежемесячной отчетности.
Конвейер данных содержит серию последовательных команд, и каждая команда выполняется на всей партии данных. Конвейер данных предоставляет выход одной команды в качестве входа для следующей. После завершения всех преобразований данных конвейер загружает весь пакет в облачное хранилище данных или другое подобное хранилище.
Подробнее о пакетной обработке »
Разница между конвейерами пакетной и потоковой обработки данных
Конвейеры пакетной обработки запускаются нечасто и, как правило, в непиковые часы. Они требуют высокой вычислительной мощности в течение короткого периода времени, когда они работают. В отличие от них, конвейеры потоковой обработки работают непрерывно, но требуют низкой вычислительной мощности. Вместо этого им нужны надежные сетевые соединения с низкой задержкой.
В чем разница между конвейерами данных и конвейерами ETL?
Конвейер извлечения, преобразования и загрузки (ETL) – это особый тип конвейера данных. Инструменты ETL извлекают или копируют необработанные данные из нескольких источников и хранят их во временном расположении, называемом промежуточная среда. Они преобразуют данные в промежуточной среде и загружают их в озера данных или хранилища.
Не все конвейеры данных соблюдают последовательность ETL. Некоторые могут извлекать данные из источника и загружать их в другое место без преобразований. Другие конвейеры данных следуют последовательности извлечения, загрузки и преобразования (ELT), где они извлекают и загружают неструктурированные данные непосредственно в озеро данных. Они выполняют изменения после перемещения информации в облачные хранилища данных.
Как AWS может поддержать ваши требования к конвейеру данных?
AWS Glue — это бессерверный сервис интеграции данных, который упрощает аналитикам поиск, подготовку, перемещение и интеграцию данных из нескольких источников для аналитики, машинного обучения и разработки приложений.
- Можно найти и подключиться к более чем 80 различным хранилищам данных.
- Управлять данными можно в централизованном каталоге данных.
- Инженеры по обработке данных, разработчики ETL, аналитики данных и бизнес-пользователи могут использовать AWS Glue Studio для создания, запуска и мониторинга конвейеров ETL для загрузки данных в озера данных.
- AWS Glue Studio предлагает интерфейсы Visual ETL, Notebook и редактора кода, поэтому у пользователей есть инструменты, соответствующие их навыкам.
- С помощью интерактивных сеансов инженеры по обработке данных могут изучать данные, а также создавать и тестировать задания, используя удобную для них среду разработки или ноутбук.
- AWS Glue — это бессерверный сервис, автоматически масштабируемый по запросу, поэтому можно сосредоточиться на сборе аналитической информации из петабайтов данных без необходимости управлять инфраструктурой.
Начните работу с AWS Glue, создав аккаунт AWS.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages