- AWS Solutions Library›
- Guidance for Agentic Data Exploration on AWS
Guidance for Agentic Data Exploration on AWS
Overview
This Guidance demonstrates how to overcome data fragmentation challenges by using a team of AI agents to automate the discovery, connection, and analysis of information across siloed systems. Users interact with an Amazon Bedrock Supervisor Agent that orchestrates specialized collaborator agents to perform data exploration tasks like schema analysis and transformation. The process begins when diverse data is uploaded to Amazon S3, then processed through Amazon Bedrock Knowledge Bases, while Amazon Bedrock Prompt Flow analyzes data entities to infer relationships and store them in Amazon Neptune graph database. You gain actionable, scalable, and AI-ready insights that drive better decision-making across your organization without manual data integration efforts.
Benefits
Transform your organization's ability to derive value from both structured and unstructured data through an intelligent multi-agent system. This architecture automatically processes, analyzes, and connects information across formats, enabling comprehensive data exploration without specialized coding skills.
Empower business users to interact naturally with complex datasets through an intuitive chat interface backed by specialized AI agents. This approach reduces time-to-insight by automating data preparation, relationship discovery, and complex query processing across your organization's information assets.
Deploy a serverless, event-driven architecture that automatically processes incoming data and makes it accessible through natural language interactions. This solution eliminates manual data preparation tasks while maintaining security controls, allowing your teams to focus on extracting business value rather than managing infrastructure.
How it works
Data Ingestion
This architecture diagram illustrates how to effectively support agentic data exploration on AWS. It shows the key components of the data ingestion process for structured and unstructured data.
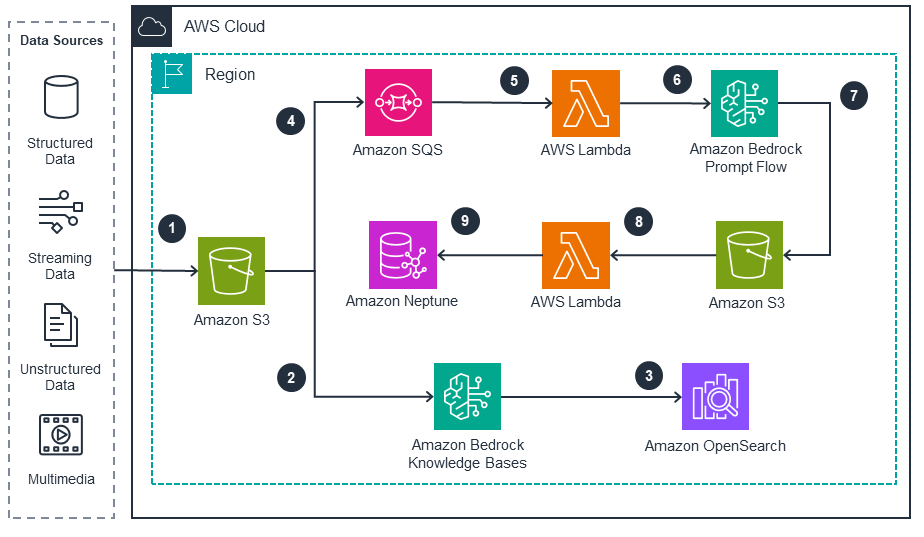
Data Exploration
This architecture diagram illustrates how to effectively support agentic data exploration on AWS. It shows the key components of the multi-agent application used to analyze, process, and search data.
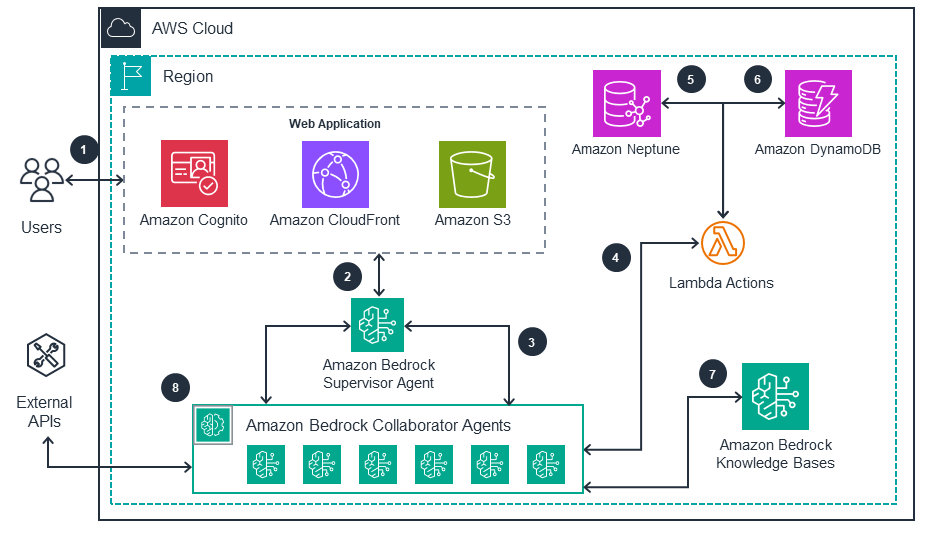
Deploy with confidence
Ready to deploy? Review the sample code on GitHub for detailed deployment instructions to deploy as-is or customize to fit your needs.
Disclaimer
The sample code; software libraries; command line tools; proofs of concept; templates; or other related technology (including any of the foregoing that are provided by our personnel) is provided to you as AWS Content under the AWS Customer Agreement, or the relevant written agreement between you and AWS (whichever applies). You should not use this AWS Content in your production accounts, or on production or other critical data. You are responsible for testing, securing, and optimizing the AWS Content, such as sample code, as appropriate for production grade use based on your specific quality control practices and standards. Deploying AWS Content may incur AWS charges for creating or using AWS chargeable resources, such as running Amazon EC2 instances or using Amazon S3 storage.
References to third-party services or organizations in this Guidance do not imply an endorsement, sponsorship, or affiliation between Amazon or AWS and the third party. Guidance from AWS is a technical starting point, and you can customize your integration with third-party services when you deploy the architecture.
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages