- AWS Solutions Library›
- Guidance for a Secure Data Mesh with Distributed Data Asset Ownership on AWS
Guidance for a Secure Data Mesh with Distributed Data Asset Ownership on AWS
Overview
How it works
Overview
This architecture diagram illustrates an overview of a data mesh design that allows for distributed data ownership and control while providing centralized data sharing and governance to address security challenges. The subsequent diagram highlights the essential AWS services used in implementing this design pattern.
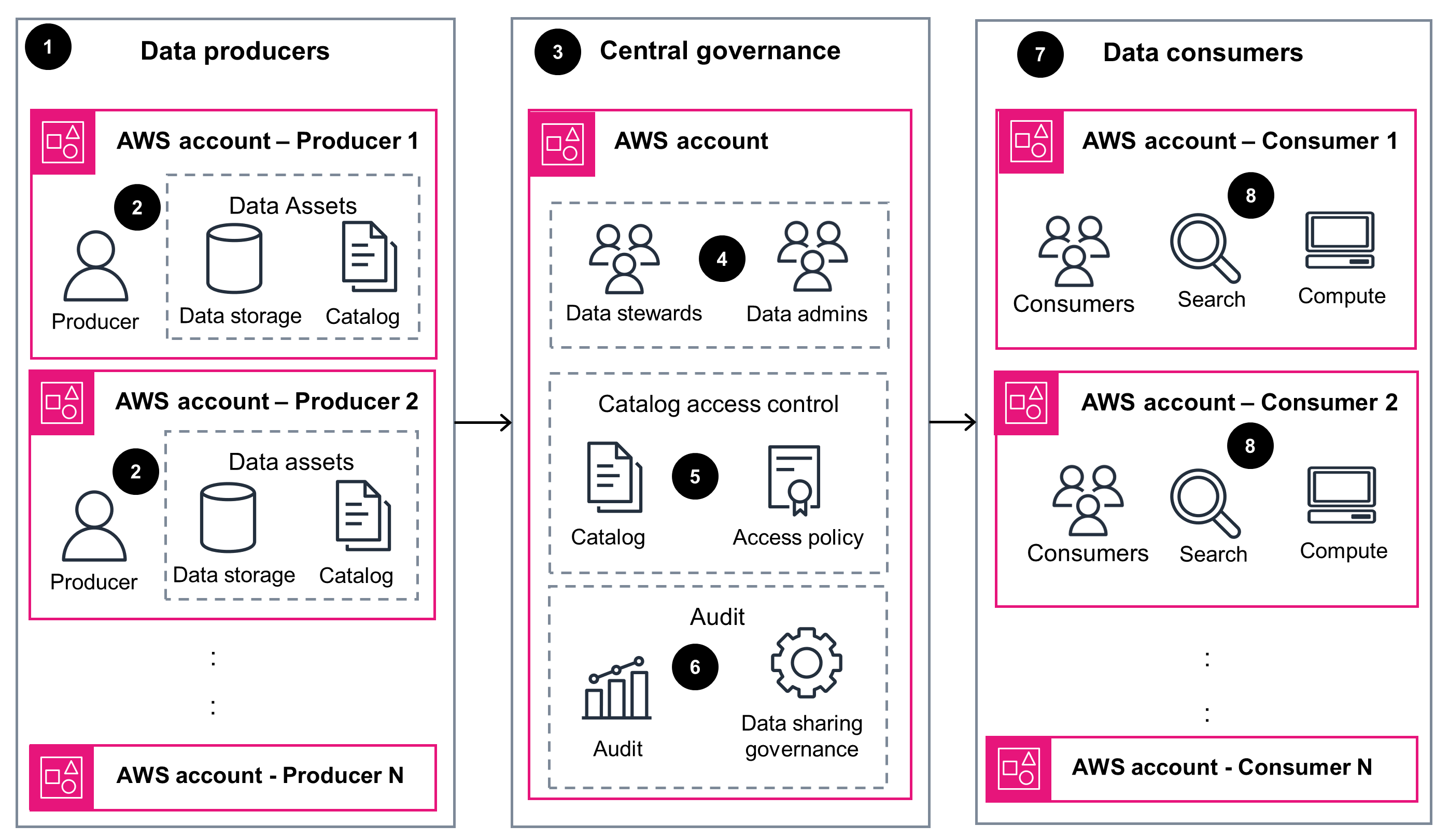
Architecture and core AWS services
This architecture diagram shows the pivotal AWS services that allow the various components of this Guidance to function seamlessly within the data mesh architecture on AWS.
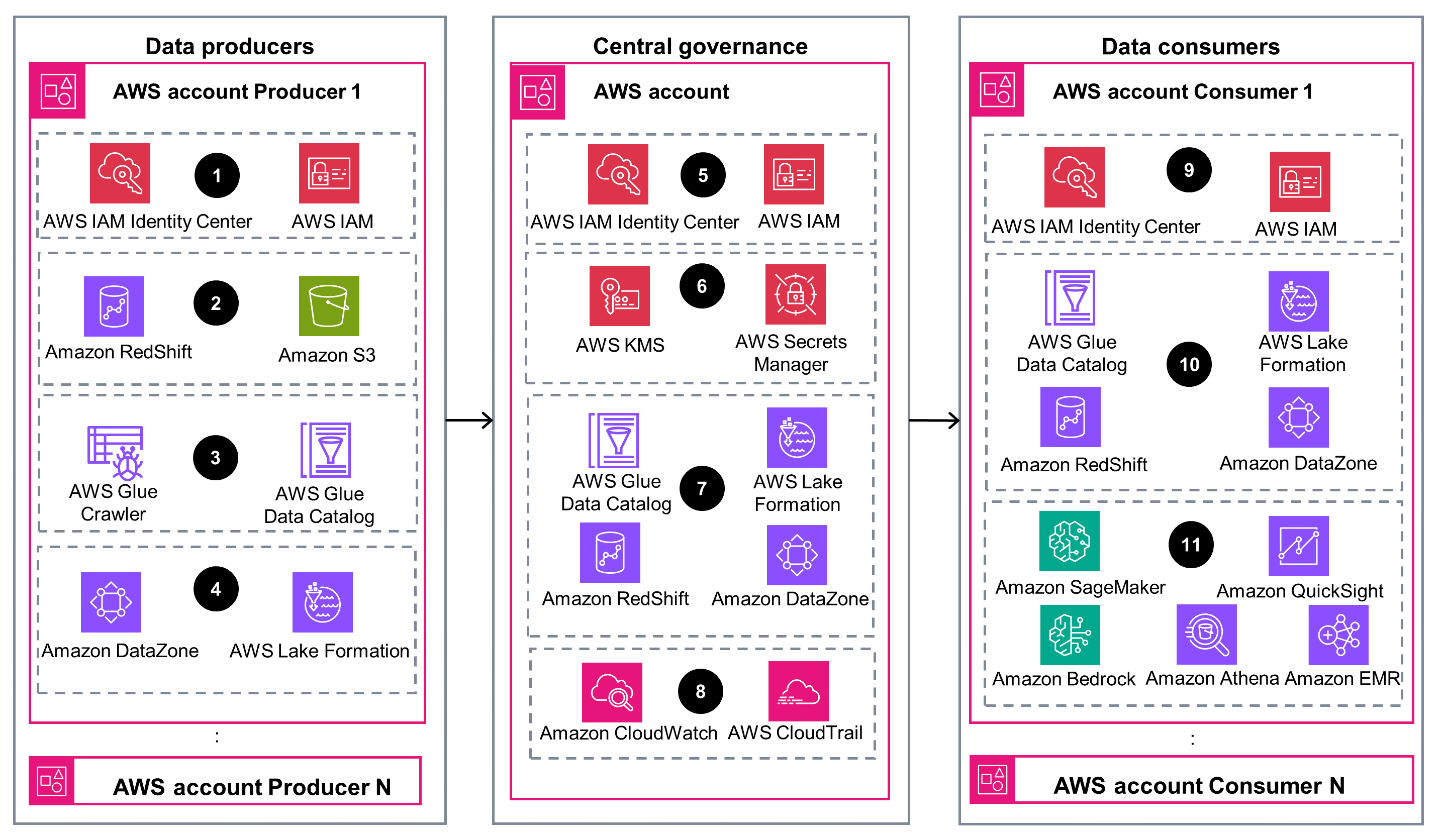
Well-Architected Pillars
The architecture diagram above is an example of a Solution created with Well-Architected best practices in mind. To be fully Well-Architected, you should follow as many Well-Architected best practices as possible.
CloudWatch provides comprehensive visibility into your resources and services, enabling proactive monitoring, quick troubleshooting, and prompt incident response. CloudTrail allows you to audit your AWS account, supporting governance and compliance through detailed activity logs. Use these services to maintain the operational excellence of your architecture and respond effectively to events and incidents.
Prioritize the security of your data and resources with IAM and AWS KMS. IAM allows you to centrally manage fine-grained permissions, specifying who or what can access your AWS services and resources. AWS KMS, on the other hand, allows you to define encryption keys for data encryption at rest and in transit, preserving the confidentiality and integrity of your sensitive information.
Safeguard the reliability of your data and applications with Amazon S3 and Data Catalog. Amazon S3 is designed to provide high durability and availability, automatically replicating your data across multiple Availability Zones. The Data Catalog serves as a centralized metadata repository, helping you maintain a consistent and reliable view of your data sources across different data stores.
Optimize the performance of your data processing and analytics with Amazon Redshift and Athena. Amazon Redshift is a fully managed, massively parallel processing (MPP) data warehouse service that helps you make fast and cost-effective business decisions. Athena, a serverless interactive query service, allows you to analyze data directly in Amazon S3 using standard SQL without the need to manage any infrastructure.
As a fully managed, serverless service, Amazon S3 eliminates the need to provision and manage infrastructure, reducing the associated costs. Use the various storage classes offered by Amazon S3, including the Amazon S3 Intelligent-Tiering storage class, S3 Standard, S3 Standard-IA, and S3 Glacier, to match your data storage and access requirements with the most cost-effective options.
Amazon DataZone helps reduce data redundancy, enforces data governance policies, and facilitates secure data sharing, leading to optimized storage usage and a reduced environmental impact. By centralizing your data and enabling collaborative data sharing, you can minimize the need for data duplication across your organization, contributing to a more sustainable data environment.
Disclaimer
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages