- Amazon S3
- Features
Amazon S3 Object Lambda
Add your own code to S3 GET, HEAD, and LIST requests to modify and process data as it is returned to an application
Overview
With S3 Object Lambda, you can add your own code to S3 GET, HEAD, and LIST requests to modify and process data as it is returned to an application. You can use custom code to modify the data returned by S3 GET requests to filter rows, dynamically resize images, redact confidential data, and much more. You can also use S3 Object Lambda to modify the output of S3 LIST requests to create a custom view of objects in a bucket and S3 HEAD requests to modify object metadata like object name and size. Powered by AWS Lambda functions, your code runs on infrastructure that is fully managed by AWS, eliminating the need to create and store derivative copies of your data or to run expensive proxies, all with no changes required to your applications.
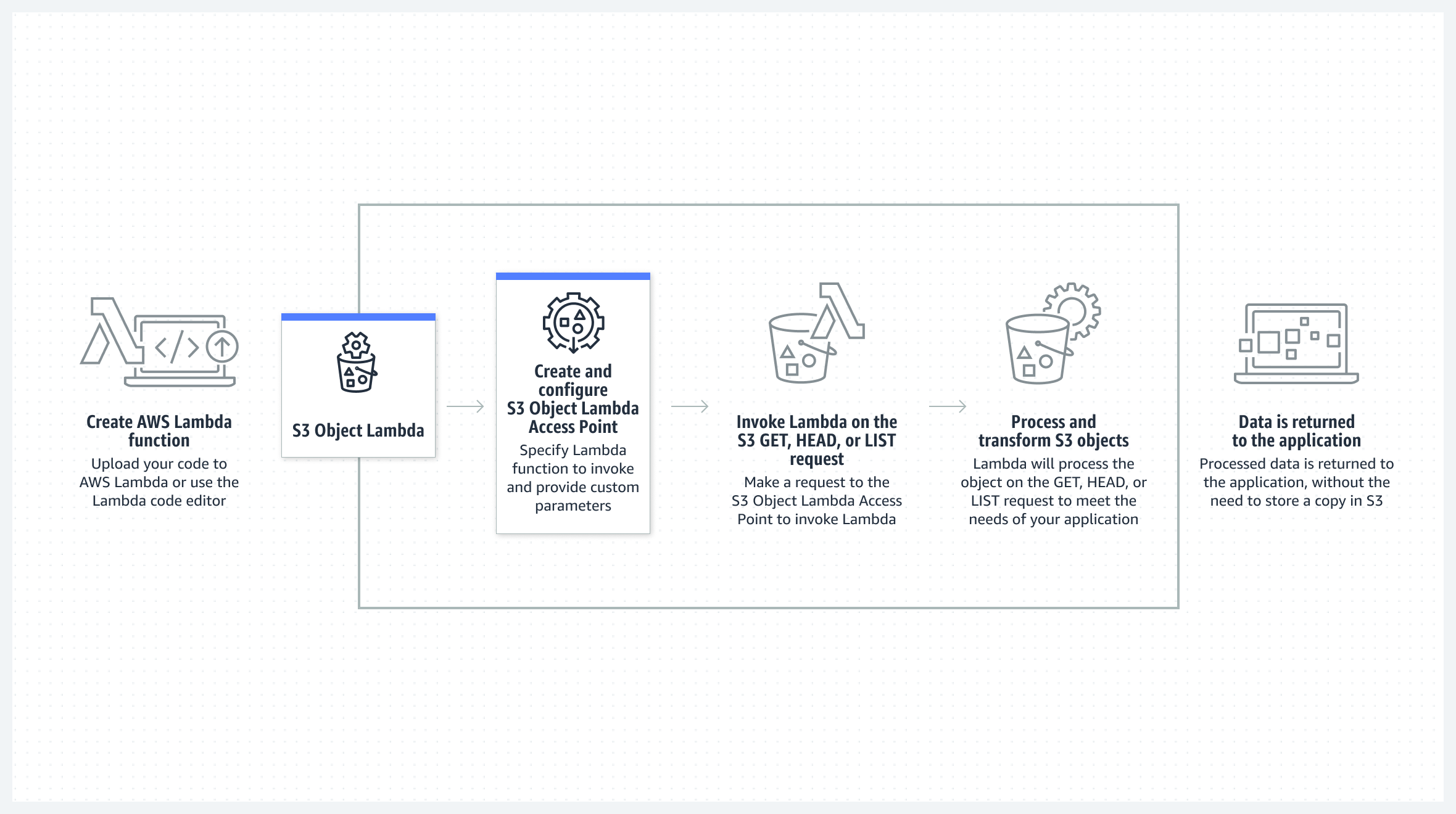
S3 Object Lambda uses AWS Lambda functions to automatically process the output of a standard S3 GET, HEAD, and LIST request. With just a few clicks in the AWS Management Console, you can configure a Lambda function and attach it to a S3 Object Lambda Access Point. From that point forward, S3 will automatically call your Lambda function to process any data retrieved through the S3 Object Lambda Access Point, returning a transformed result back to the application. You can author and execute your own custom Lambda functions, tailoring S3 Object Lambda’s data transformation to your specific use case.
Benefits
S3 Object Lambda gives you the flexibility to invoke Lambda functions directly from S3 GET, HEAD, and LIST requests to process data to meet the specific requirements of your applications. S3 Object Lambda uses the fully managed infrastructure of S3 and AWS Lambda, and all of its features and capabilities. You can use new or existing AWS Lambda functions to process your data such as filtering, masking, redacting, compressing, changing the format, or modifying objects for your specific applications.
Powered by AWS Lambda functions, your code runs on infrastructure that is fully managed by AWS, eliminating the need to create and store derivative copies of your data or to run expensive proxies, all with no changes required to applications. You can run AWS Lambda functions with S3 GET, HEAD, and LIST requests to process objects by updating your application to use an S3 Object Lambda Access Point, which will invoke a Lambda function, and deliver the processed object to requesting clients.
S3 Object Lambda makes it easy transform S3 data for different applications by eliminating complex software and infrastructure, or the need to create derivative copies of your data. You can add your own code to process data as its retrieved from S3 before returning it to an application. S3 Object Lambda works with your existing applications, and you don’t need to change your code. You can easily present multiple views of your data for different applications with a standard S3 GET, HEAD, and LIST request.
How does S3 Object Lambda work?
S3 Object Lambda helps you to easily meet the unique data format requirements of any application without having to build and operate additional infrastructure, such as a proxy layer, or having to create and maintain multiple derivative copies of your data. S3 Object Lambda uses AWS Lambda functions to automatically process the output of a standard S3 GET, HEAD, and LIST request. AWS Lambda is a serverless compute service that runs customer-defined code without requiring management of underlying compute resources.
With just a few clicks in the AWS Management Console, you can configure a Lambda function and attach it to a S3 Object Lambda Access Point. Standard S3 GET, HEAD, and LIST requests made through an S3 Object Lambda Access Point will now invoke the specified Lambda function. From that point forward, S3 will automatically call your Lambda function to process any data retrieved through the S3 Object Lambda Access Point, returning a transformed result back to the application. You can author and execute your own custom Lambda functions, tailoring S3 Object Lambda’s data transformation to your specific use case. To learn more read the S3 Object Lambda user guide.
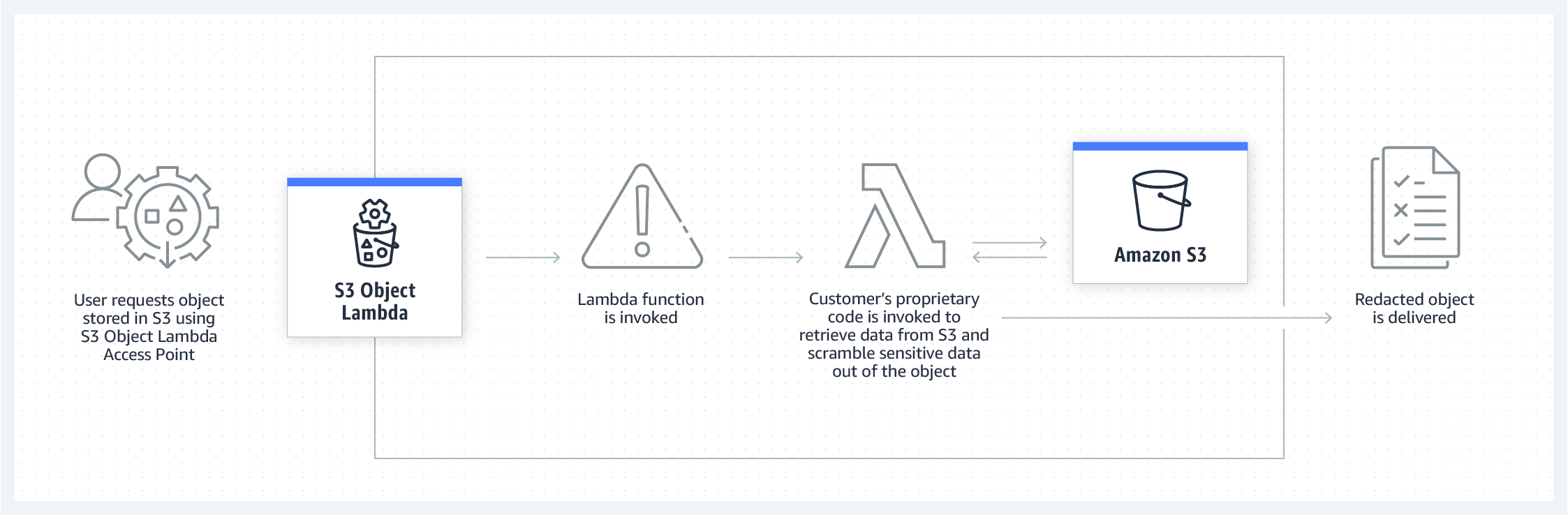
S3 Object Lambda use case: Redacting sensitive data
S3 Object Lambda can be used to redact sensitive information from an object in S3 for specific applications, without changing the existing object or creating and maintaining multiple derivative copies of the data. The Lambda function will retrieve the object from a standard S3 GET request, process the data to remove the sensitive details, and return the redacted object to the application. To learn more about other use cases, read the S3 Object Lambda user guide.
Pixieset
Pixieset is an all-in-one platform for modern photographers, offering photo client galleries, websites, online stores and studio management software tools.
Pixieset transforms images on-the-fly with Amazon S3 Object Lambda
"Pixieset’s mission is to support photographers and creatives across the world as they run and grow their business. Our customers upload photos that are then shared with their clients on different viewing devices, such as a smartphone, tablet, or desktop. To optimize the distribution of photos, we currently generate copies with different resolutions shortly after an image is uploaded to Amazon S3 using AWS Lambda. We’re super excited about Amazon S3 Object Lambda’s integration with Amazon CloudFront because we can apply transformations and watermarks on-the-fly as images are accessed from Amazon CloudFront. We are able to take advantage of the benefits of global caching, while no longer needing to store multiple copies of the same image."
Sam Lin, Head of Engineering - Pixieset

Audible
Audible is the leading creator and provider of premium audio storytelling, offering customers a new way to enhance and enrich their lives every day. Audible content includes more than 790,000 audiobooks, podcasts, and Audible Originals. Audible has millions of members around the world who subscribe to one of 10 localized services designed for customers in Australia, Canada, France, Germany, India, Italy, Japan, Spain, the UK, and the US.
Audible uses Amazon S3 Object Lambda to dynamically modify manifests to offer the most performant streaming
Blog: How Audible uses Amazon S3 Object Lambda to improve streaming playback performance
"Users access and stream content on Audible from a wide range of devices and geographies, varying from strong to limited internet connectivity. We use Amazon S3 Object Lambda to dynamically modify manifests and segment sizes to provide users with the most performant and high quality streaming and audio entertainment experience, whether they are at home or on the go. With S3 Object Lambda, we are able to improve playback performance, and in turn, further enhance the customer experience through technological innovation and superior programming. "
Saurabh Gandhi, Sr. Director of Software Development - Audible

Trend Micro
Trend Micro, a global cybersecurity leader, helps make the world safe for exchanging digital information. Fueled by decades of security expertise, global threat research, and continuous innovation, Trend Micro's cybersecurity platform protects hundreds of thousands of organizations and millions of individuals across clouds, networks, devices, and endpoints. Trend Micro’s cybersecurity platform delivers a powerful range of advanced threat defense techniques optimized for AWS.
Blog: How Trend Micro uses Amazon S3 Object Lambda to help keep sensitive data secure
"We love the simplicity in getting started. By using S3 Object Lambda in our File Storage Security solution, we were able to complete a proof-of-concept in less than a day, with the first full version including integration into the existing plugin set finished a day later."
Mike Milner, Director of Product Management - Trend Micro

Druva
Druva delivers data protection and management across endpoints, data centers and cloud workloads eliminating dependence on complex infrastructure and time-consuming administration.
"Our 4,000 customers need to meet expanding global data protection, compliance, and security requirements. Amazon S3 Object Lambda is a market-changing innovation that brings compute resources closer to centralized data repositories, making it possible for our customers to extract more value from their data. As a platform built entirely on AWS, Druva prides itself on continuously enhancing the user experience with AWS’s latest features and technology. The combination of the Druva Cloud Platform, powered by AWS, and Amazon S3 Object Lambda will bring organizations unmatched integration opportunities as well as direct access and analysis to unlock the full potential of their backup data."
Stephen Manley, Chief Technology Officer - Druva

Nasuni
Nasuni is disrupting file storage with a cloud based approached backed by Amazon S3 replacing traditional on-premises primary and secondary storage. Nasuni delivers a file storage platform using object storage delivering a simpler, lower cost, and more efficient cloud solution that scales to handle rapid unstructured data growth.
"S3 Object lambda is a game changer for Nasuni and it will be a core technology in our cloud file storage service on AWS. We use S3 Object Lambda to create a simple, scalable API to our proprietary object storage based file system. Our enterprise customers can use this to access their files directly from their S3 bucket instead of going through a Nasuni Edge Appliance. This means they can easily connect unstructured data from Nasuni to AWS analytic services like Macie and Kendra enabling enterprises to gain insights from their file data."
Russ Kennedy, Chief Product Officer - Nasuni

PetaGene
PetaGene was founded in Cambridge, the birthplace of genomics, to address the rapidly growing data management problems of the genomics industry. PetaGene has become known for the industry-leading performance and usability of its genomic compression and encryption solutions — the company's software now provides encryption, selective data sharing and auditing solutions for all kinds of data, and these solutions also benefit from the same seamless transparent access methods.
"PetaGene enables organizations to protect data so that they can control and audit what different users can see, exposing only the content within each file that the user is allowed to see. PetaGene also efficiently compresses already compressed NGS genomic data up to 11x smaller without loss of any kind. Although users can already transparently access protected and/or compressed data in their original native formats by loading our user-mode readback library into their environment, with S3 Object Lambda it is possible for users to access data in their original native formats via standard S3 GET requests, without the need for any library installation by users. This makes it even easier for customers to deploy PetaGene's data protection, compliance, and compression products for their end-users."
Dan Greenfield, PhD, Co-Founder and CEO - PetaGene

S3 Object Lambda resources
S3 Object Lambda blogs
Get started
S3 Object Lambda can be set up in the S3 Management Console, with three simple steps. First, navigate to the Object Lambda Access Point tab on console. Second, create an S3 Object Lambda Access Point and in its configuration provide a name for this resource, the Lambda function to invoke against your S3 GET, HEAD, or LIST requests, and a supporting S3 Access Point. There are example Lambda function implementations in the AWS documentation to help you get started with the service. Lastly, update your SDK and application to use the new S3 Object Lambda Access Point to retrieve data from S3 using the language SDK of your choice. S3 Object Lambda will begin to process your standard S3 GET, HEAD, and LIST requests.
Access the S3 Object Lambda getting started tutorial and read the user guide for more information on how to get started.