AWS News Blog
Introducing Amazon S3 Object Lambda – Use Your Code to Process Data as It Is Being Retrieved from S3

|
March 15, 2023 – You can now use S3 Object Lambda with Amazon CloudFront to tailor content for end users.
August 13, 2024 – Added a note clarifying that, when following the walkthrough, you should not mark the Specify Lambda function version option that was added after this post was published.
When you store data in Amazon Simple Storage Service (Amazon S3), you can easily share it for use by multiple applications. However, each application has its own requirements and may need a different view of the data. For example, a dataset created by an e-commerce application may include personally identifiable information (PII) that is not needed when the same data is processed for analytics and should be redacted. On the other side, if the same dataset is used for a marketing campaign, you may need to enrich the data with additional details, such as information from the customer loyalty database.
To provide different views of data to multiple applications, there are currently two options. You either create, store, and maintain additional derivative copies of the data, so that each application has its own custom dataset, or you build and manage infrastructure as a proxy layer in front of S3 to intercept and process data as it is requested. Both options add complexity and costs, so the S3 team decided to build a better solution.
Today, I’m very happy to announce the availability of S3 Object Lambda, a new capability that allows you to add your own code to process data retrieved from S3 before returning it to an application. S3 Object Lambda works with your existing applications and uses AWS Lambda functions to automatically process and transform your data as it is being retrieved from S3. The Lambda function is invoked inline with a standard S3 GET request, so you don’t need to change your application code.
In this way, you can easily present multiple views from the same dataset, and you can update the Lambda functions to modify these views at any time.
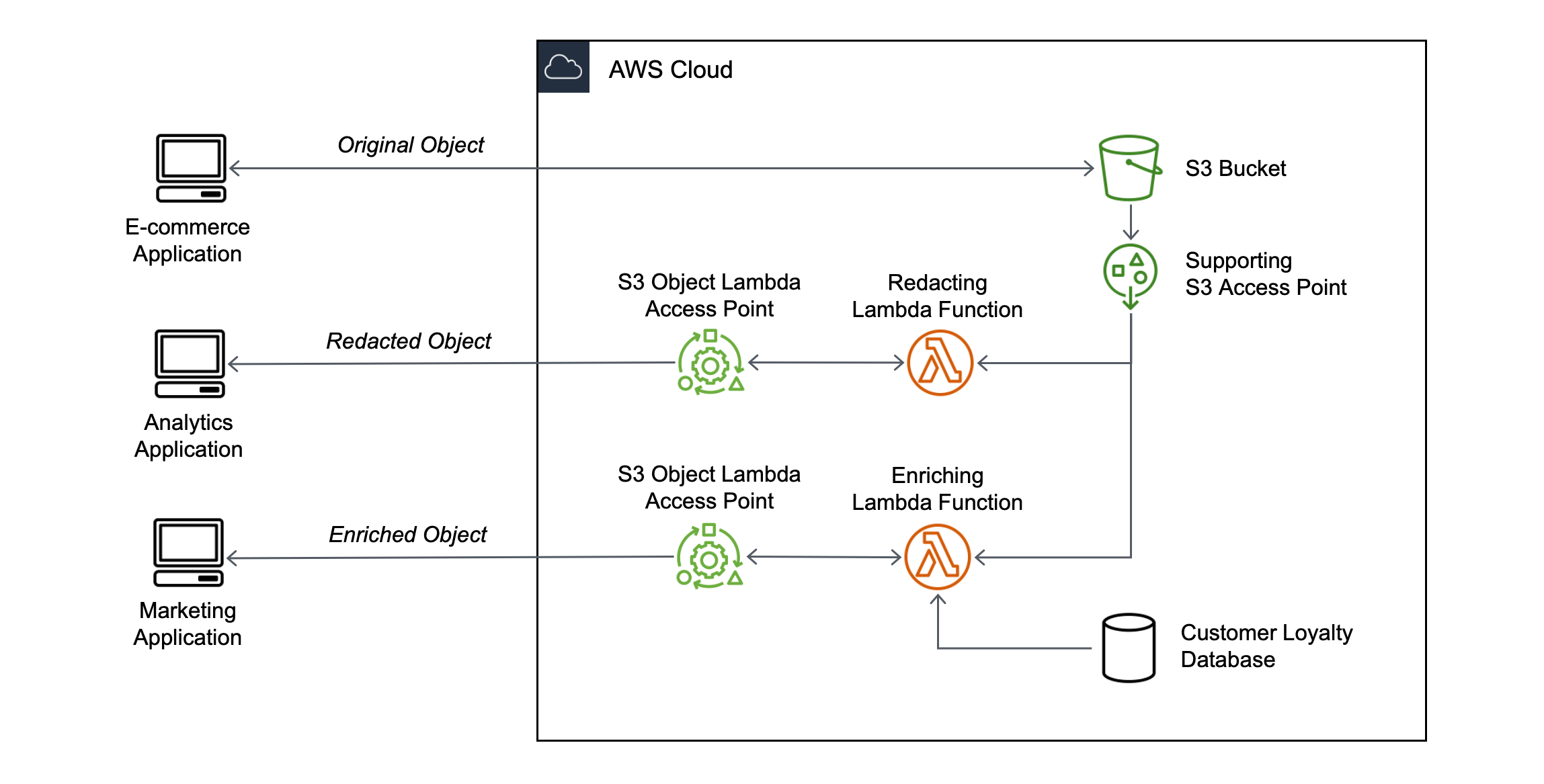
There are many use cases that can be simplified by this approach, for example:
- Redacting personally identifiable information for analytics or non-production environments.
- Converting across data formats, such as converting XML to JSON.
- Augmenting data with information from other services or databases.
- Compressing or decompressing files as they are being downloaded.
- Resizing and watermarking images on the fly using caller-specific details, such as the user who requested the object.
- Implementing custom authorization rules to access data.
You can start using S3 Object Lambda with a few simple steps:
- Create a Lambda Function to transform data for your use case.
- Create an S3 Object Lambda Access Point from the S3 Management Console.
- Select the Lambda function that you created above.
- Provide a supporting S3 Access Point to give S3 Object Lambda access to the original object.
- Update your application configuration to use the new S3 Object Lambda Access Point to retrieve data from S3.
To get a better understanding of how S3 Object Lambda works, let’s put it in practice.
How to Create a Lambda Function for S3 Object Lambda
To create the function, I start by looking at the syntax of the input event the Lambda function receives from S3 Object Lambda:
{
"xAmzRequestId": "1a5ed718-5f53-471d-b6fe-5cf62d88d02a",
"getObjectContext": {
"inputS3Url": "https://myap-123412341234.s3-accesspoint.us-east-1.amazonaws.com/s3.txt?X-Amz-Security-Token=...",
"outputRoute": "io-iad-cell001",
"outputToken": "..."
},
"configuration": {
"accessPointArn": "arn:aws:s3-object-lambda:us-east-1:123412341234:accesspoint/myolap",
"supportingAccessPointArn": "arn:aws:s3:us-east-1:123412341234:accesspoint/myap",
"payload": "test"
},
"userRequest": {
"url": "/s3.txt",
"headers": {
"Host": "myolap-123412341234.s3-object-lambda.us-east-1.amazonaws.com",
"Accept-Encoding": "identity",
"X-Amz-Content-SHA256": "e3b0c44297fc1c149afbf4c8995fb92427ae41e4649b934ca495991b7852b855"
}
},
"userIdentity": {
"type": "IAMUser",
"principalId": "...",
"arn": "arn:aws:iam::123412341234:user/myuser",
"accountId": "123412341234",
"accessKeyId": "..."
},
"protocolVersion": "1.00"
}The getObjectContext property contains some of the most useful information for the Lambda function:
- The
inputS3Urlis a presigned URL that the function can use to download the original object from the supporting Access Point. In this way, the Lambda function doesn’t need to have S3 read permissions to retrieve the original object and can only access the object processed by each invocation. - The
outputRouteand theoutputTokenare two parameters that are used to send back the modified object using the newWriteGetObjectResponseAPI.
The configuration property contains the Amazon Resource Name (ARN) of the Object Lambda Access Point and of the supporting Access Point.
The userRequest property gives more information of the original request, such as the path in the URL, and the HTTP headers.
Finally, the userIdentity section returns the details of who made the original request and can be used to customize access to the data.
Now that I know the syntax of the event, I can create the Lambda function. To keep things simple, here’s a function written in Python that changes all text in the original object to uppercase. When creating this function in the Lambda console, I select the Python 3.7 runtime.
import boto3
import requests
def lambda_handler(event, context):
print(event)
object_get_context = event["getObjectContext"]
request_route = object_get_context["outputRoute"]
request_token = object_get_context["outputToken"]
s3_url = object_get_context["inputS3Url"]
# Get object from S3
response = requests.get(s3_url)
original_object = response.content.decode('utf-8')
# Transform object
transformed_object = original_object.upper()
# Write object back to S3 Object Lambda
s3 = boto3.client('s3')
s3.write_get_object_response(
Body=transformed_object,
RequestRoute=request_route,
RequestToken=request_token)
return {'status_code': 200}
Looking at the code of the function, there are three main sections:
- First, I use the
inputS3Urlproperty of the input event to download the original object. Since the value is a presigned URL, the function doesn’t need permissions to read from S3. - Then, I transform the text to be all uppercase. To customize the behavior of the function for your use case, this is the part you need to change. For example, to detect and redact personally identifiable information (PII), I can use Amazon Comprehend to locate PII entities with the
DetectPiiEntitiesAPI and replace them with asterisks or a description of the redacted entity type. - Finally, I use the new
WriteGetObjectResponseAPI to send the result of the transformation back to S3 Object Lambda. In this way, the transformed object can be much larger than the maximum size of the response returned by a Lambda function. For larger objects, theWriteGetObjectResponseAPI supports chunked transfer encoding to implement a streaming data transfer. The Lambda function only needs to return the status code (200 OKin this case), eventual errors, and optionally customize the metadata of the returned object as described in the S3GetObjectAPI.
I package the function and its dependencies, including an updated version of the AWS SDK for Python (boto3) implementing the new write_get_object_response method, and upload it to Lambda. Note that the maximum duration for a Lambda function used by S3 Object Lambda is 60 seconds, and that the Lambda function needs AWS Identity and Access Management (IAM) permissions to call the WriteGetObjectResponse API.
How to Create an S3 Object Lambda Access Point from the Console
In the S3 console, I create an S3 Access Point on one of my S3 buckets:

Then, I create an S3 Object Lambda Access Point using the supporting Access Point I just created. The Lambda function is going to use the supporting Access Point to download the original objects.

During the configuration of the S3 Object Lambda Access Point as shown below, I select the Lambda function I created above and not mark the Specify Lambda function version option (that was added after the following screenshot was taken).
Optionally, I can enable support for requests using a byte range, or using part numbers. For now, I leave them disabled. To understand how to use byte range and part numbers with S3 Object Lambda, please see the documentation.

When configuring the S3 Object Lambda Access Point, I can set up a string as a payload that is passed to the Lambda function in all invocations coming from that Access Point, as you can see in the configuration property of the sample event I described before. In this way, I can configure the same Lambda function for multiple S3 Object Lambda Access Points, and use the value of thepayload to customize the behavior for each of them.

Finally, I can set up a policy, similar to what I can do with normal S3 Access Points, to provide access to the objects accessible through this Object Lambda Access Point. For now, I keep the policy empty. Then, I leave the default option to block all public access and create the Object Lambda Access Point.
Now that the S3 Object Lambda Access Point is ready, let’s see how I can use it.
How to Use the S3 Object Lambda Access Point
In the S3 console, I select the newly created Object Lambda Access Point. In the properties, I copy the ARN to have it available later.
With the AWS Command Line Interface (AWS CLI), I upload a text file containing a few sentences to the S3 bucket behind the S3 Object Lambda Access Point:
Using S3 Object Lambda with my existing applications is very simple. I just need to replace the S3 bucket with the ARN of the S3 Object Lambda Access Point and update the AWS SDKs to accept the new syntax using the S3 Object Lambda ARN.
For example, this is a Python script that downloads the text file I just uploaded: first, straight from the S3 bucket, and then from the S3 Object Lambda Access Point. The only difference between the two downloads is the value of the Bucket parameter.
import boto3
s3 = boto3.client('s3')
print('Original object from the S3 bucket:')
original = s3.get_object(
Bucket='danilop-data',
Key='s3.txt')
print(original['Body'].read().decode('utf-8'))
print('Object processed by S3 Object Lambda:')
transformed = s3.get_object(
Bucket='arn:aws:s3-object-lambda:us-east-1:123412341234:accesspoint/myolap',
Key='s3.txt')
print(transformed['Body'].read().decode('utf-8'))I start the script on my laptop:
And this is the result I get:
Original object on S3:
Amazon Simple Storage Service (Amazon S3) is an object storage service that offers industry-leading scalability, data availability, security, and performance. This means customers of all sizes and industries can use it to store and protect any amount of data for a range of use cases, such as data lakes, websites, mobile applications, backup and restore, archive, enterprise applications, IoT devices, and big data analytics.
Object processed by S3 Object Lambda:
AMAZON SIMPLE STORAGE SERVICE (AMAZON S3) IS AN OBJECT STORAGE SERVICE THAT OFFERS INDUSTRY-LEADING SCALABILITY, DATA AVAILABILITY, SECURITY, AND PERFORMANCE. THIS MEANS CUSTOMERS OF ALL SIZES AND INDUSTRIES CAN USE IT TO STORE AND PROTECT ANY AMOUNT OF DATA FOR A RANGE OF USE CASES, SUCH AS DATA LAKES, WEBSITES, MOBILE APPLICATIONS, BACKUP AND RESTORE, ARCHIVE, ENTERPRISE APPLICATIONS, IOT DEVICES, AND BIG DATA ANALYTICS.
The first output is downloaded straight from the source bucket, and I see the original content as expected. The second time, the object is processed by the Lambda function as it is being retrieved and, as the result, all text is uppercase!
More Use Cases for S3 Object Lambda
When retrieving an object using S3 Object Lambda, there is no need for an object with the same name to exist in the S3 bucket. The Lambda function can use information in the name of the file or in the HTTP headers to generate a custom object.
For example, if you ask to use an S3 Object Lambda Access Point for an image with name sunset_600x400.jpg, the Lambda function can look for an image named sunset.jpg and resize it to fit the maximum width and height as described in the file name. In this case, the Lambda function would need access permission to read the original image, because the object key is different from what was used in the presigned URL.
Another interesting use case would be to retrieve JSON or CSV documents, such as order.json or items.csv, that are generated on the fly based on the content of a database. The metadata in the request HTTP headers can be used to pass the orderId to use. As usual, I expect our customers’ creativity to far exceed the use cases I described here.
Here’s a short video describing how S3 Object Lambda works and how you can use it:
Availability and Pricing
S3 Object Lambda is available today in all AWS Regions with the exception of the Asia Pacific (Osaka), AWS GovCloud (US-East), AWS GovCloud (US-West), China (Beijing), and China (Ningxia) Regions. You can use S3 Object Lambda with the AWS Management Console, AWS Command Line Interface (AWS CLI), and AWS SDKs. Currently, the AWS CLI high-level S3 commands, such as aws s3 cp, don’t support objects from S3 Object Lambda Access Points, but you can use the low-level S3 API commands, such as aws s3api get-object.
With S3 Object Lambda, you pay for the AWS Lambda compute and request charges required to process the data, and for the data S3 Object Lambda returns to your application. You also pay for the S3 requests that are invoked by your Lambda function. For more pricing information, please see the Amazon S3 pricing page.
If you’re looking for another example, here’s a complete implementation by my colleague Greg Davis using S3 Object Lambda to return a thumbnail version of an image in S3.
This new capability makes it much easier to share and convert data across multiple applications.
Start using S3 Object Lambda to simplify your storage architecture today.
— Danilo