AWS News Blog
Category: Amazon Simple Storage Service (S3)

AWS Weekly Roundup: NY Summit recap, Local Zone in Hanoi, Grok 4.3 in Bedrock, price reductions, and more (June 22, 2026)
Last week AWS Summit New York City brought together thousands of customers, partners, and builders for a free, one-day event showcasing the latest in cloud and AI innovation. Dr. Swami Sivasubramanian, VP of Agentic AI at AWS unveiled a stack of AI launches in his keynote, all built around one thesis: agents that compound value […]

Top announcements of the AWS Summit in New York, 2026
A recap of the top announcements from AWS’s New York Summit 2026

Amazon S3 annotations: attach rich, queryable context directly to your objects
Amazon S3 now lets you attach up to 1 GB of rich, mutable, and queryable context directly to your objects using annotations, purpose-built for AI agents and autonomous workflows that need to discover, understand, and act on data at scale without maintaining separate metadata systems.
AWS Weekly Roundup: Claude Mythos Preview in Amazon Bedrock, AWS Agent Registry, and more (April 13, 2026)
In my last Week in Review post, I mentioned how much time I’ve been spending on AI-Driven Development Lifecycle (AI-DLC) workshops with customers this year. A common theme in those sessions is the need for better cost visibility. Teams are moving fast with AI, but as they go from experimenting to full production, finance and […]

Launching S3 Files, making S3 buckets accessible as file systems
Amazon S3 Files makes S3 buckets accessible as high-performance file systems on AWS compute resources, eliminating the tradeoff between object storage benefits and interactive file capabilities while enabling seamless data sharing with ~1ms latencies.
AWS Weekly Roundup: Amazon S3 turns 20, Amazon Route 53 Global Resolver general availability, and more (March 16, 2026)
Twenty years ago this past week, Amazon S3 launched publicly on March 14, 2006. While Amazon Simple Storage Service is often considered the foundational storage service that defined cloud infrastructure, what began as a simple object storage service has grown into something far larger in scope and scale. As of March 2026, S3 stores more […]
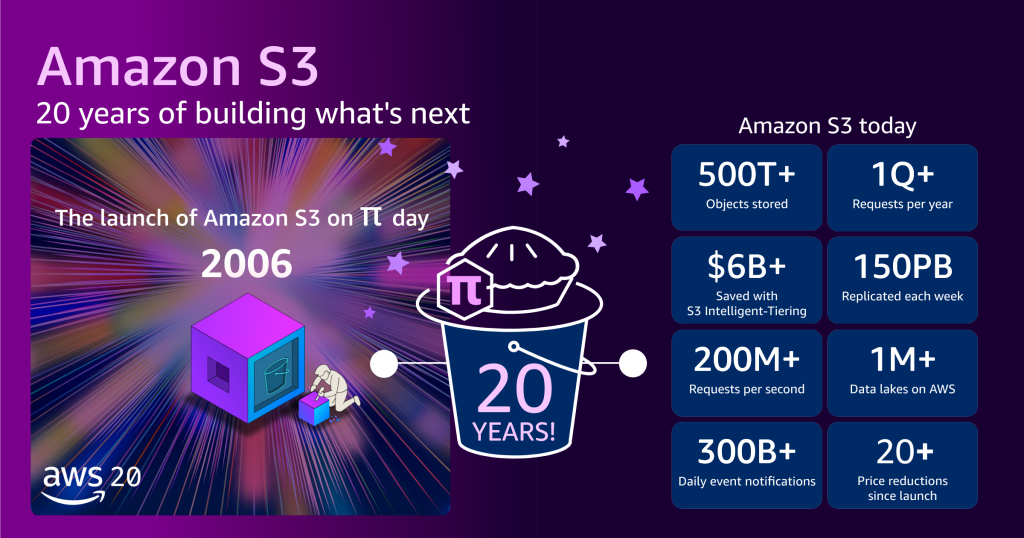
Twenty years of Amazon S3 and building what’s next
Some reflections on 20 years of innovations in Amazon S3 including S3 Tables, S3 Vectors and S3 Metadata.

Introducing account regional namespaces for Amazon S3 general purpose buckets
AWS launches a new feature of Amazon S3 that lets you create general purpose buckets in your own account regional namespace simplifying bucket creation and management as your data storage needs grow in size and scope.