AWS News Blog
Category: Amazon Redshift

AWS Weekly Roundup: AWS Transform at 1 year, Claude Platform on AWS, EC2 M3 Ultra Mac instances, and more (May 18, 2026)
Just a year ago, we launched AWS Transform for .NET, Mainframe and VMware workloads, the first agentic AI service purpose-built for modernizing enterprise applications at scale. At re:Invent 2025, we introduced AWS Transform custom, which enables organizations to modernize and transform code at scale using AWS-managed and custom transformations. You can upgrade language versions, migrate […]
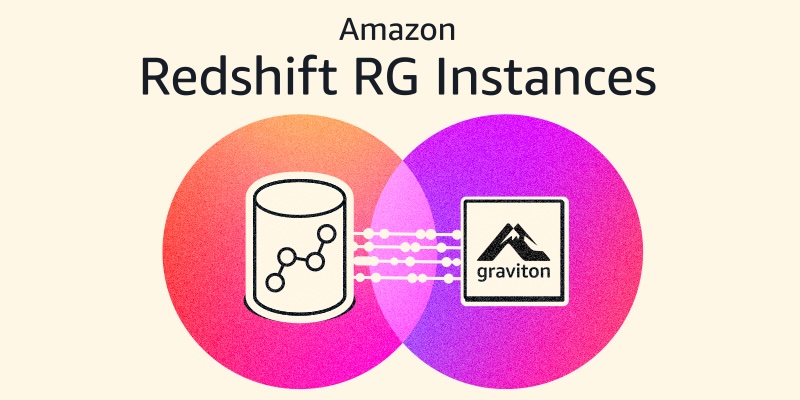
Amazon Redshift introduces AWS Graviton-based RG instances with an integrated data lake query engine
Amazon Redshift RG instances, powered by AWS Graviton, run data warehouse and data lake workloads up to 2.4x as fast as RA3 instances at 30% lower price per vCPU. Its integrated data lake query engine supports open table formats such as Apache Iceberg.
AWS Weekly Roundup: NVIDIA Nemotron 3 Super on Amazon Bedrock, Nova Forge SDK, Amazon Corretto 26, and more (March 23, 2026)
Hello! I’m Daniel Abib, and this is my first AWS Weekly Roundup. I’m a Senior Specialist Solutions Architect at AWS, focused on the generative AI and Amazon Bedrock. With over 28 years of experience in solution architecture, software development, and cloud architecture, I help Startups & Enterprises harness the power of generative AI with Amazon […]
AWS Weekly Roundup: Amazon S3 turns 20, Amazon Route 53 Global Resolver general availability, and more (March 16, 2026)
Twenty years ago this past week, Amazon S3 launched publicly on March 14, 2006. While Amazon Simple Storage Service is often considered the foundational storage service that defined cloud infrastructure, what began as a simple object storage service has grown into something far larger in scope and scale. As of March 2026, S3 stores more […]
Amazon S3 Storage Lens adds performance metrics, support for billions of prefixes, and export to S3 Tables
New capabilities help optimize application performance, analyze unlimited prefixes, and simplify metrics analysis through S3 Tables integration.
AWS Weekly Roundup: Omdia recognition, Amazon Bedrock RAG evaluation, International Women’s Day events, and more (March 24, 2025)
As we celebrate International Women’s Day (IWD) this March, I had the privilege of attending the ‘Women in Tech’ User Group meetup in Shenzhen last weekend. I was inspired to see over 100 women in tech from different industries come together to discuss AI ethics from a female perspective. Together, we explored strategies such as […]

Simplify analytics and AI/ML with new Amazon SageMaker Lakehouse
Unifying data silos, Amazon SageMaker Lakehouse seamlessly integrates S3 data lakes and Redshift warehouses, enabling unified analytics and AI/ML on a single data copy through open Apache Iceberg APIs and fine-grained access controls.

New Amazon DynamoDB zero-ETL integration with Amazon SageMaker Lakehouse
Effortlessly analyze operational data in Amazon SageMaker Lakehouse, freeing developers from building custom pipelines and enabling seamless insights extraction.