AWS in Switzerland and Austria (Alps)
Switzerland’s Open-Source Apertus LLMs now available on Amazon SageMaker AI
Today, we are excited to announce that the Apertus family of large language models (LLMs) developed by Swiss AI are available in Amazon SageMaker JumpStart. In this blog post, we explore how you can deploy these models efficiently on Amazon SageMaker AI.
The Swiss AI Initiative, a partnership between ETH Zurich and EPFL Lausanne recently released Apertus — a new family of LLMs developed on public infrastructure. Apertus enables transparency by open-sourcing training/inference code, documentation and references of the training data as well as the training methodology.
The Apertus model family consists of Apertus 70B and Apertus 8B in both pretrained as well as instruction-tuned (“Instruct”) variants and represents a ground-up effort by Swiss public institutions to create a competitive LLM that supports over 1,000 languages while maintaining compliance with Swiss copyright and data protection laws as well as the EU AI Act. Apertus was trained on the Swiss ALPS supercomputer using over 4,000 NVIDIA GH200 GPUs, predominantly carbon-neutral electricity, and sustainable lake-cooling technology from Lake Lugano. Further background information on Apertus is available in the ETH Launch Blog as well as in the Technical Report.
“Training the model was our contribution to open AI research. AWS makes our innovation easily accessible to any organization that can now run our model privately on AWS global infrastructure, including the AWS Europe (Zurich) Region.” says Martin Jaggi, Associate Professor at EPFL and Head of Machine Learning and Optimization Laboratory.
Get started with Apertus on AWS Infrastructure in your preferred region through Amazon SageMaker AI
Apertus marks an important step in Switzerland’s open-source AI development. As the model and its ecosystem mature, it can be applied across a wide range of domains, from public services and healthcare to finance and research. Apertus can be deployed on AWS’ AI-ready global infrastructure, including the AWS Europe (Zurich) Region, and scale seamlessly from experimentation to production-ready. This enables Swiss and European organizations to leverage AI while keeping data residency aligned with their geographic preferences. Amazon SageMaker AI provides the enterprise-grade infrastructure needed to handle the scale and complexity of 70/8-billion parameter models, delivering the flexibility and reliability essential for both public sector and commercial customers. Deploying the model on SageMaker AI also gives customers full control over their data, helping organizations meet strict privacy, security, and compliance requirements. For more details, see the AWS Trust Center.
SageMaker JumpStart is a machine learning (ML) model hub that accelerates your ML journey. With SageMaker JumpStart, you can evaluate, compare, and deploy pre-trained foundation models (FMs), including the newly available Apertus family. As part of the AWS AI offerings, SageMaker JumpStart provides customizable ML solutions which you can deploy to SageMaker AI inference endpoints within your AWS infrastructure. It complements Amazon Bedrock, which offers serverless API foundation model inference along with features like customizations, knowledge bases, agents, and guardrails.
Key technical benefits of SageMaker AI and SageMaker JumpStart include:
- Optimized inference stack – Pre-built containers for LLM inference with GPU acceleration, memory optimization, and efficient tokenization
- Auto-scaling endpoints – Managed infrastructure automatically scales compute resources based on request volume and latency requirements, including scale-to-zero
- Production-ready API – SageMaker real-time inference endpoints with standardized API calls, SDK and AWS Identity and Access Management (IAM) integration
- Integrated monitoring – Built-in metrics for throughput, latency, and resource utilization with an Amazon CloudWatch integration
- Enterprise security – Amazon Virtual Private Cloud (VPC) deployment with IAM access control and network isolation options
Deploying Apertus on SageMaker AI
Deploying the Apertus models to SageMaker AI can be done via the JumpStart web UI as well as programmatically through the Amazon SageMaker Python SDK for which we provide an example notebook. In this blog post, we will explore both methods, providing maximum flexibility. We recommend that you use the following instance types for deployment and request the respective Service Quota for Amazon SageMaker AI inference endpoints depending on your needs. Further details on the achievable throughput with Apertus models on popular instance types are included in the “Throughput Performance” section of this blog post.
- For a testing setup we recommend:
- g6.48xlarge, g5.48xlarge or g6e.48xlarge for Apertus 70B
- any g5/g6/g6e instance for Apertus 8B
- For a production setup with > 10 concurrent requests per second we recommend:
- p4d.24xlarge or p5.48xlarge for Apertus 70B
- g5.xlarge, g6e.xlarge or p4d.24xlarge for Apertus 8B
Deploying Apertus with SageMaker JumpStart
All four variants of the Apertus models are available on SageMaker JumpStart. We recommend the “Instruct” versions for most users, as they are fine-tuned to follow natural language instructions more effectively:
- Apertus 8B/70B Instruct 2509
- Apertus 8B/70B 2509
Complete the following steps to deploy Apertus through the SageMaker JumpStart UI:
-
- To access SageMaker JumpStart, use one of the following methods:
- In Amazon SageMaker Studio, choose JumpStart in the navigation panel.
- To access SageMaker JumpStart, use one of the following methods:
-
-
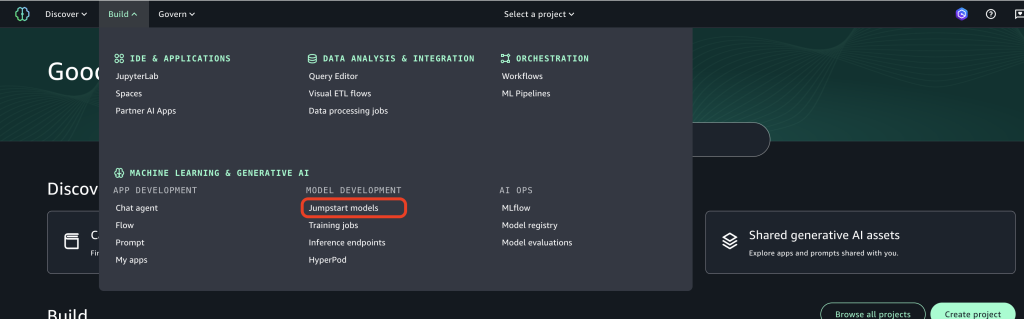
- Alternatively, in Amazon SageMaker Unified Studio, on the Build menu, choose JumpStart models under Model Development.
-
-
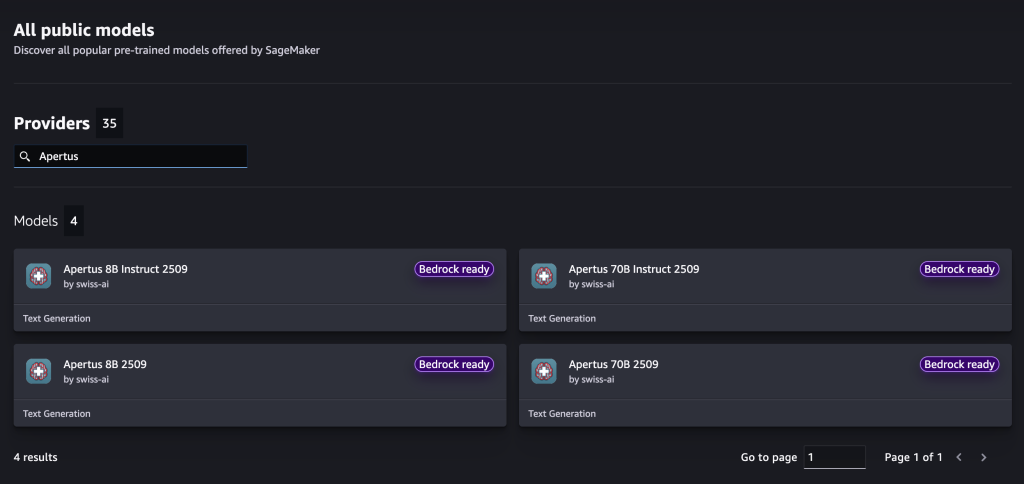
- Search for Apertus 70B/8B Instruct in the model browser
-
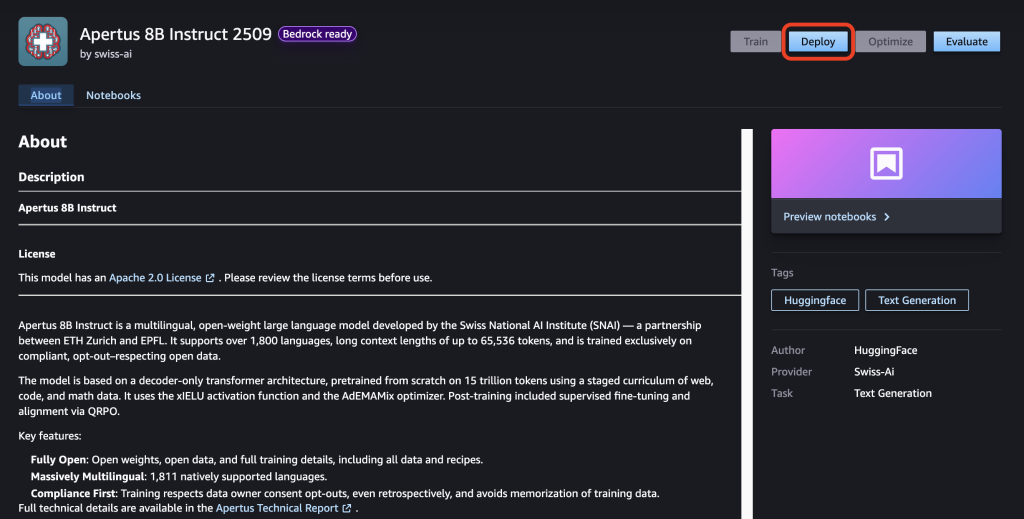
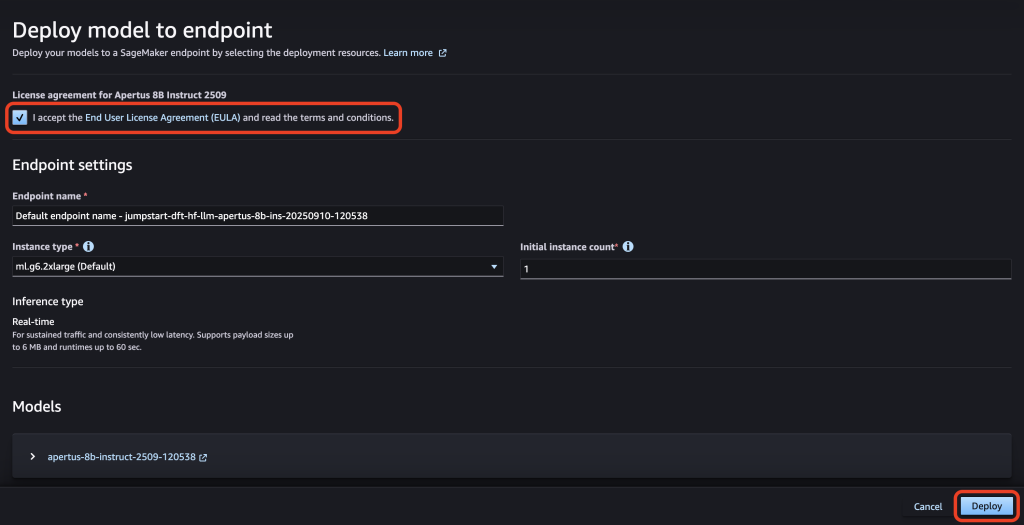
- Select your preferred model and click on Deploy.
-
- Select your preferred Instance Type and click on Deploy.
-
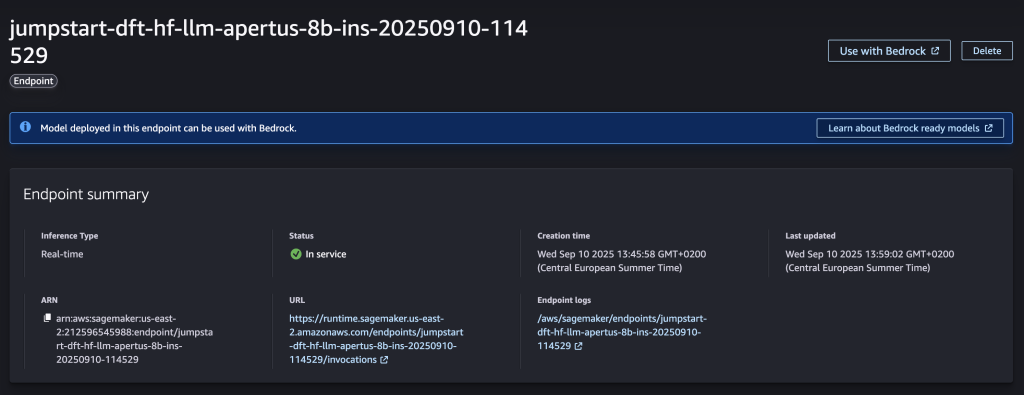
- After some time, the endpoint status will show as In service and you will be able to run inference requests against it.
Deploying Apertus using the SageMaker Python SDK and a Jupyter Notebook
This method provides an alternative to the SageMaker JumpStart web UI. Instead of using the web interface, you will create an inference endpoint directly through the SageMaker API, allowing for advanced customization. The GitHub repository Generative AI Inference Examples on Amazon SageMaker contains example notebooks showing how to deploy popular LLMs to Amazon SageMaker AI inference endpoints. We provide the Swiss-ai-apertus-LMI-V15.ipynb notebook in the 01-models/Swiss-AI/Apertus directory inside the repository for a step-by-step guide on how to configure and deploy the Apertus models to an SageMaker AI inference endpoint.
Begin by setting up an environment to run the notebook in:
- Create a JupyterLab space in Amazon SageMaker Studio: Amazon SageMaker AI Developer Guide
- Use the JupyterLab IDE in Amazon SageMaker Unified Studio: Amazon SageMaker Unified Studio User Guide
- Execute the notebook in a local Python environment with Jupyter installed
To get started with the notebook, clone the GitHub repository into your environment:
git clone https://github.com/aws-samples/sagemaker-genai-hosting-examples.git
cd sagemaker-genai-hosting-examples/01-models/Swiss-AI/Apertus/
# e.g. with Visual Studio Code, open the notebook via
code Swiss-ai-apertus-LMI-V15.ipynbThen follow the instructions in the Notebook Swiss-AI/Apertus/Swiss-ai-apertus-LMI-V15.ipynb. It contains all the code to deploy to a SageMaker AI inference endpoint and sample code to invoke the endpoint with or without response streaming.
Consuming Apertus
Successful deployment can be tested via the AWS CLI as well as via the AWS SDK for Python (boto3). We will walk through both methods in this section.
Invoke through AWS CLI
You can invoke your endpoint via the AWS CLI as follows. Please replace <endpoint-region> and <endpoint-name> with applicable values for your endpoint.
aws sagemaker-runtime invoke-endpoint \
--endpoint-name <endpoint-name> \
--content-type "application/json" \
--region <endpoint-region> \
--body '{
"messages": [
{
"role": "system",
"content": "You are a helpful and friendly assistant."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "I am traveling to Zurich. How can I say hello in Swiss German?"
}
]
}
]
}' \
/dev/stdout
# Example Output:
{
...
"choices": [
{
"message": {
"role": "assistant",
"content": "You can say \"Grüezi\" to say hello in Swiss German..."
}
}
],
...
}
Invoke through boto3 Python SDK
You can invoke your endpoint via the SDK as follows. Please replace <endpoint-region> and <endpoint-name> with applicable values for your endpoint.
import boto3
import json
# Create SageMaker runtime client
client = boto3.client('sagemaker-runtime', region_name='<endpoint-region>')
# Invoke the endpoint
response = client.invoke_endpoint(
EndpointName='<endpoint-name>',
ContentType='application/json',
Body=json.dumps({
"messages": [
{
"role": "system",
"content": "You are a helpful and friendly assistant."
},
{
"role": "user",
"content": [
{
"type": "text",
"text": "I am traveling to Zurich. How can I say hello in Swiss German?"
}
]
}
],
"parameters": {
"max_new_tokens": 256,
"do_sample": True,
"temperature": 0.2
}
})
)
# Read and decode the response
result = json.loads(response['Body'].read().decode())
print(result)A more advanced example for consuming the model via the SDK is included in the aforementioned Swiss-ai-apertus-LMI-V15.ipynb notebook.
Clean up
To clean up the model and endpoint, use the following code in Python or the AWS CLI, respectively:
# Clean up using the Python SDK
client.delete_endpoint()
client.delete_model()# Clean up using the AWS CLI
aws sagemaker delete-endpoint \
--endpoint-name <endpoint-name> \
--region <endpoint-region>
aws sagemaker delete-model \
--model-name <model-name> \
--region <endpoint-region>Alternatively, you can delete the endpoint in the SageMaker Studio web UI under Deployments → Endpoints.
Throughput Performance
We benchmarked the throughput performance of both model sizes with multiple instance types to give general performance guidance for production deployments.
The benchmark setup uses the open source Deep Java Library (DJL) Large Model Inference (LMI) container with vLLM. The LMI container image bundles the model server with optimized inference libraries for high-performance LLM deployment. This setup is equivalent to an Apertus model deployed with Amazon SageMaker JumpStart. We use the vLLM provided benchmark suite and the ShareGPT dataset for the experiments.
Apertus 70B benchmark results:
| Instance Type | Request Throughput (req/s) | Output Token Throughput (tok/s) | Total Token Throughput (tok/s) |
| g5.48xlarge | 0.44 | 88 | 188.7 |
| g6.48xlarge | 1.09 | 227.12 | 476.05 |
| g6e.48xlarge | 3.08 | 640.23 | 1359.62 |
| p4d.24xlarge | 10.87 | 2193.92 | 4704.7 |
| p5.48xlarge | 27.72 | 5597.77 | 12002.46 |
Apertus 8B benchmark results:
| Instance Type | Request Throughput (req/s) | Output Token Throughput (tok/s) | Total Token Throughput (tok/s) |
| g5.xlarge | 4.91 | 884.02 | 2005.07 |
| g6.xlarge | 3.57 | 648.29 | 1462.92 |
| g6e.xlarge | 14.61 | 2732.00 | 6081.87 |
| p4d.24xlarge | 56.77 | 10629.85 | 23647.35 |
The benchmark results indicate that for production workloads, p5.48xlarge or p4d.24xlarge instances are recommended. From a cost / performance perspective the smaller g5.xlarge instance type is advisable for Apertus 8B.
We observed that g6e.48xlarge instances achieve a 3× improvement in request throughput for Apertus 70B when deploying two model copies on the same instance, each using four of the eight GPUs (tensor_parallel_degree = 4). This configuration places each model copy within one of the two GPU affinity groups, reducing cross-group communication and minimizing overhead.
Our tests prioritized throughput. Production setups should fine-tune inference settings for the specific use case, for example to optimize for low latency.
Conclusion
Developed by ETH Zurich and EPFL, the Apertus model family highlights how open-source LLMs can advance transparency in AI research and align with evolving standards for governance, privacy, and regulatory compliance. AWS provides hosting options through SageMaker AI, ensuring immediate accessibility to organizations across Switzerland and beyond. Organizations across both public and private sectors can now leverage Swiss-built AI while maintaining their preferred data residency requirements. If you’re interested in exploring or implementing Apertus for your organization, here are the recommended next steps:
-
- Explore deployment options: Whether you prefer the simplicity of SageMaker JumpStart or the customization possibilities of a Jupyter notebook implementation, both paths provide straightforward ways to get started with Apertus on AWS.
- Contact your AWS account team: If your organization has a specific use case we recommend reaching out to your AWS account team. They can help you get your use case into production https://aws.amazon.com/contact-us/sales-support/.
- View the model cards for Apertus on HuggingFace.