AWS News Blog
Amazon Aurora PostgreSQL Serverless – Now Generally Available

|
The database is usually the most critical part of a software architecture and managing databases, especially relational ones, has never been easy. For this reason, we created Amazon Aurora Serverless, an auto-scaling version of Amazon Aurora that automatically starts up, shuts down and scales up or down based on your application workload.
The MySQL-compatible edition of Aurora Serverless has been available for some time now. I am pleased to announce that the PostgreSQL-compatible edition of Aurora Serverless is generally available today.
Before moving on with details, I take the opportunity to congratulate the Amazon Aurora development team that has just won the 2019 Association for Computing Machinery’s (ACM) Special Interest Group on Management of Data (SIGMOD) Systems Award!
When you create a database with Aurora Serverless, you set the minimum and maximum capacity. Your client applications transparently connect to a proxy fleet that routes the workload to a pool of resources that are automatically scaled. Scaling is very fast because resources are “warm” and ready to be added to serve your requests.

There is no change with Aurora Serverless on how storage is managed by Aurora. The storage layer is independent from the compute resources used by the database. There is no need to provision storage in advance. The minimum storage is 10GB and, based on the database usage, the Amazon Aurora storage will automatically grow, up to 64 TB, in 10GB increments with no impact to database performance.
Creating an Aurora Serverless PostgreSQL Database
Let’s start an Aurora Serverless PostgreSQL database and see the automatic scalability at work. From the Amazon RDS console, I select to create a database using Amazon Aurora as engine. Currently, Aurora Serverless is compatible with PostgreSQL version 10.7. Selecting that version, the serverless option becomes available.
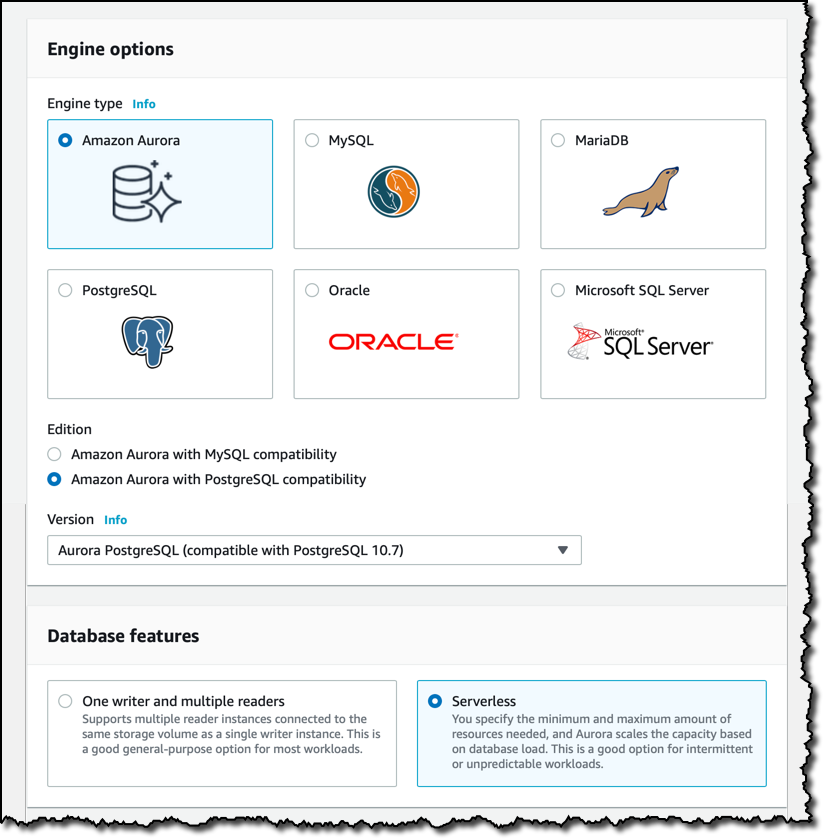
I give the new DB cluster an identifier, choose my master username, and let Amazon RDS generate a password for me. I will be able to retrieve my credentials during database creation.

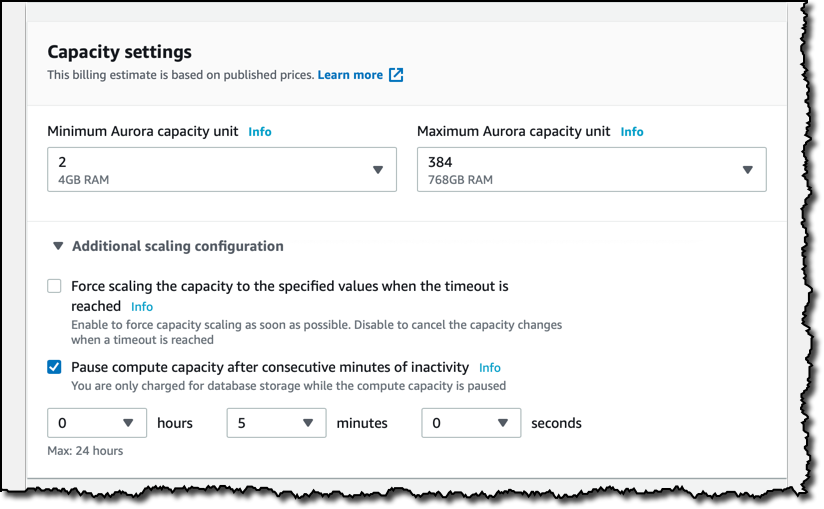
I can now select the minimum and maximum capacity for my database, in terms of Aurora Capacity Units (ACUs), and in the additional scaling configuration I choose to pause compute capacity after 5 minutes of inactivity. Based on my settings, Aurora Serverless automatically creates scaling rules for thresholds for CPU utilization, connections, and available memory.
Testing Some Load on the Database
To generate some load on the database I am using sysbench on an EC2 instance. There are a couple of Lua scripts bundled with sysbench that can help generate an online transaction processing (OLTP) workload:
- The first script,
parallel_prepare.lua, generates 100,000 rows per table for 24 tables. - The second script,
oltp.lua, generates workload against those data using 128 worker threads.
By using those scripts, I start generating load on my database. As you can see from the graph below, taken from the RDS console monitoring tab, the serverless database capacity grows and shrinks to follow my requirements. The metric shown on this graph is the number of ACUs used by the database cluster:
- First it scales up to accommodate the sysbench workload.
- When I stop the load generator, it pauses after a few minutes of inactivity.
- If I restart the load generator again, the database resumes at the same capacity it left.
- If I disable the pause for inactivity option, or if I just leave a very small amount of workload, it scales down to the configured minimum capacity.
The pause option is great for database with a batch workload that need to start at full speed, do what they need to do, and then pause.

Available Now
Aurora Serverless PostgreSQL is available now in US East (N. Virginia), US East (Ohio), US West (Oregon), EU (Ireland), and Asia Pacific (Tokyo). With Aurora Serverless, you pay on a per-second basis for the database capacity you use when the database is active, plus the usual Aurora storage costs.
For more information on Amazon Aurora, I recommend this great post explaining why and how it was created:
Amazon Aurora ascendant: How we designed a cloud-native relational database
It’s never been so easy to use a relational database in production. I am so excited to see what you are going to use it for!
— Danilo