AWS News Blog
Amazon S3 – Support for Website Redirects
Our friends at Boostability have been using Amazon S3 to help their clients build websites hosted on Amazon S3. Boostability provides search engine optimization technology and fulfillment services to agencies, media companies and phone book providers.
I recently chatted with Jared Turner, CTO for Boostability. He told me that they needed a solution that was scalable, cost efficient, had a high degree of up-time, API-based, and easy to maintain. By using an AWS SDK, they were able to get to market very quickly, and they have been happy with the very fast response/load times for their S3 hosted websites.
As you may know, you can easily host a static website on Amazon S3. Last year, we introduced a website site hosting feature to give you control over the root, index, and error documents. Since then, hosting static websites has been one of the fastest growing features in the history of Amazon S3.
Today we are extending S3’s website hosting capabilities by giving you control over redirects. If you publish some content at a particular URL (let’s say http://www.example.com/oldpage) and later decide to move it elsewhere (http://www.example.com/newpage) you can now tell S3 to ensure that requests for the old page are sent to the new one. If you move content around or redesign the entire structure of your S3-hosted website, you can use redirects to so that existing references to the old content will remain valid.
Setting Up Redirection
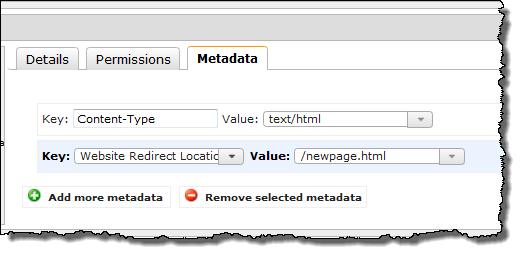
You specify a redirect by adding some metadata to an existing S3 object. You can do this through the AWS Management Console or through the S3 APIs. Here’s how to set up a redirection using the console (the “/” prefix is used to specify a redirect to another object in the same S3 bucket):
Let’s Be Direct
Now that I’ve talked about the basics, I’d like to dive a little deeper. Let’s start by reviewing what happens when your browser makes a request for an object hosted on S3:
- The browser sends an HTTP GET request such as “GET /oldpage”.
- S3 responds with an HTTP status code of 200 (“OK”) and the content of the object.
- The browser parses and displays the object (generally HTML).
Now, what happens if you decide to move oldpage to newpage by setting up a redirect in S3? Here’s the flow:
- The browser sends the “GET /oldpage” request.
- S3 responds with an HTTP status code of 301 (“moved permanently”) and the URL of the new object. This can point to an external web page or to another S3 object.
- The browser sends a GET request for the URL it received in step 2. This request could return the 200 and the new object (the most common case), or another 301 if further redirection is required.
As you can see from reading step 2, you can use an S3 redirect to point to another S3 object or to a URL that’s external to S3. Currently, search engines treat a redirect in a transparent fashion and will maintain the rank of a page even if it has been moved.
Read more about hosting a website on S3 and setting up redirection.
— Jeff;