AWS News Blog
AWS HowTo: Using Amazon Elastic MapReduce with DynamoDB (Guest Post)
Today’s guest blogger is Adam Gray. Adam is a Product Manager on the Elastic MapReduce Team.
— Jeff;
Apache Hadoop and NoSQL databases are complementary technologies that together provide a powerful toolbox for managing, analyzing, and monetizing Big Data. Thats why we were so excited to provide out-of-the-box Amazon Elastic MapReduce (Amazon EMR) integration with Amazon DynamoDB, providing customers an integrated solution that eliminates the often prohibitive costs of administration, maintenance, and upfront hardware. Customers can now move vast amounts of data into and out of DynamoDB, as well as perform sophisticated analytics on that data, using EMRs highly parallelized environment to distribute the work across the number of servers of their choice. Further, as EMR uses a SQL-based engine for Hadoop called Hive, you need only know basic SQL while we handle distributed application complexities such as estimating ideal data splits based on hash keys, pushing appropriate filters down to DynamoDB, and distributing tasks across all the instances in your EMR cluster.
In this article, Ill demonstrate how EMR can be used to efficiently export DynamoDB tables to S3, import S3 data into DynamoDB, and perform sophisticated queries across tables stored in both DynamoDB and other storage services such as S3.
We will also use sample product order data stored in S3 to demonstrate how you can keep current data in DynamoDB while storing older, less frequently accessed data, in S3. By exporting your rarely used data to Amazon S3 you can reduce your storage costs while preserving low latency access required for high velocity data. Further, exported data in S3 is still directly queryable via EMR (and you can even join your exported tables with current DynamoDB tables).
The sample order data uses the schema below. This includes Order ID as its primary key, a Customer ID field, an Order Date stored as the number of seconds since epoch, and Total representing the total amount spent by the customer on that order. The data also has folder-based partitioning by both year and month, and youll see why in a bit.

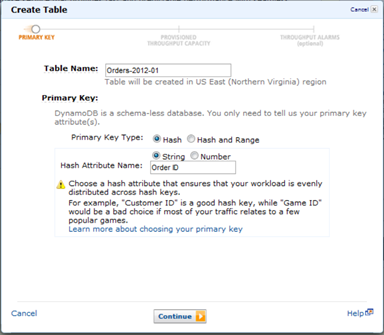
Creating a DynamoDB Table
Lets create a DynamoDB table for the month of January, 2012 named Orders-2012-01. We will specify Order ID as the Primary Key. By using a table for each month, it is much easier to export data and delete tables over time when they no longer require low latency access.
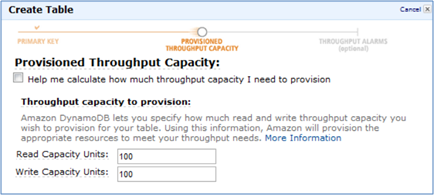
For this sample, a read capacity and a write capacity of 100 units should be more than sufficient. When setting these values you should keep in mind that the larger the EMR cluster the more capacity it will be able to take advantage of. Further, you will be sharing this capacity with any other applications utilizing your DynamoDB table.
Launching an EMR Cluster
Please follow Steps 1-3 in the EMR for DynamoDB section of the Elastic MapReduce Developer Guide to launch an interactive EMR cluster and SSH to its Master Node to begin submitting SQL-based queries. Note that we recommend you use at least three instances of m1.large size for this sample.
At the hadoop command prompt for the current master node, type hive. You should see a hive prompt: hive>
As no other applications will be using our DynamoDB table, lets tell EMR to use 100% of the available read throughput (by default it will use 50%). Note that this can adversely affect the performance of other applications simultaneously using your DynamoDB table and should be set cautiously.
Creating Hive Tables
Outside data sources are referenced in your Hive cluster by creating an EXTERNAL TABLE. First lets create an EXTERNAL TABLE for the exported order data in S3. Note that this simply creates a reference to the data, no data is yet moved.
PARTITIONED BY (year string, month string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\t’
LOCATION ‘s3://elastic-mapreduce/samples/ddb-orders’ ;
You can see that we specified the data location, the ordered data fields, and the folder-based partitioning scheme.
Now lets create an EXTERNAL TABLE for our DynamoDB table.
STORED BY ‘org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler’ TBLPROPERTIES (
“dynamodb.table.name” = “Orders-2012-01”,
“dynamodb.column.mapping” = “order_id:Order ID,customer_id:Customer ID,order_date:Order Date,total:Total”
);
This is a bit more complex. We need to specify the DynamoDB table name, the DynamoDB storage handler, the ordered fields, and a mapping between the EXTERNAL TABLE fields (which cant include spaces) and the actual DynamoDB fields.
Now were ready to start moving some data!
Importing Data into DynamoDB
In order to access the data in our S3 EXTERNAL TABLE, we first need to specify which partitions we want in our working set via the ADD PARTITION command. Lets start with the data for January 2012.
Now if we query our S3 EXTERNAL TABLE, only this partition will be included in the results. Lets load all of the January 2012 order data into our external DynamoDB Table. Note that this may take several minutes.
SELECT order_id, customer_id, order_date, total
FROM orders_s3_export ;
Looks a lot like standard SQL, doesnt it?
Querying Data in DynamoDB Using SQL
Now lets find the top 5 customers by spend over the first week of January. Note the use of unix-timestamp as order_date is stored as the number of seconds since epoch.
FROM orders_ddb_2012_01
WHERE order_date >= unix_timestamp(‘2012-01-01’, ‘yyyy-MM-dd’)
AND order_date < unix_timestamp(‘2012-01-08’, ‘yyyy-MM-dd’)
GROUP BY customer_id
ORDER BY spend desc
LIMIT 5 ;
Querying Exported Data in S3
It looks like customer: c-2cC5fF1bB was the biggest spender for that week. Now lets query our historical data in S3 to see what that customer spent in each of the final 6 months of 2011. Though first we will have to include the additional data into our working set. The RECOVER PARTITIONS command makes it easy to
We will now query the 2011 exported data for customer c-2cC5fF1bB from S3. Note that the partition fields, both month and year, can be used in your Hive query.
FROM orders_s3_export
WHERE customer_id = ‘c-2cC5fF1bB’
AND month >= 6
AND year = 2011
GROUP BY customer_id, year, month
ORDER by month desc;
Exporting Data to S3
Now lets export the January 2012 DynamoDB table data to a different S3 bucket owned by you (denoted by YOUR BUCKET in the command). Well first need to create an EXTERNAL TABLE for that S3 bucket. Note that we again partition the data by year and month.
PARTITIONED BY (year string, month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,’
LOCATION ‘s3:// YOUR BUCKET‘;
Now export the data from DynamoDB to S3, specifying the appropriate partition values for that tables month and year.
PARTITION (year=’2012′, month=’01’)
SELECT * from orders_ddb_2012_01;
Note that if this was the end of a month and you no longer needed low latency access to that tables data, you could also delete the table in DynamoDB. You may also now want to terminate your job flow from the EMR console to ensure you do not continue being charged.
Thats it for now. Please visit our documentation for more examples, including how to specify the format and compression scheme for your exported files.
— Adam Gray, Product Manager, Amazon Elastic MapReduce.