AWS News Blog
New – Auto Scaling for EMR Clusters
The Amazon EMR team is cranking out new features at an impressive pace (guess they have lots of worker nodes)! So far this quarter they have added all of these features:
- September – Data Encryption for Apache Spark, Tez, and Hadoop MapReduce.
- September – Open-sourced EMR-DynamoDB Connector for Apache Hive.
- November – Stream Processing at Scale with Apache Flink.
- November – Fine-grained Access Control Using Cluster Tags.
Today we are adding to this list with the addition of automatic scaling for EMR clusters. You can now use scale out and scale in policies to adjust the number of core and task nodes in your clusters in response to changing workloads and to optimize your resource usage:
Scale out Policies add additional capacity and allow you to tackle bigger problems. Applications like Apache Spark and Apache Hive will automatically take advantage of the increased processing power as it comes online.
Scale in Policies remove capacity, either at the end of an instance billing hour or as tasks complete. If a node is removed while it is running a YARN container, YARN will rerun that container on another node (read Configure Cluster Scale-Down Behavior for more info).
Using Auto Scaling
In order to make use of Auto Scaling, an IAM role that give Auto Scaling permission to launch and terminate EC2 instances must be associated with your cluster. If you create a cluster from the EMR Console, it will create the EMR_AutoScaling_DefaultRole for you. You can use it as-is or customize it as needed. If you create a cluster programmatically or via the command-line, you will need to create it yourself. You can also create the default roles from the command line like this:
$ aws emr create-default-rolesFrom the console, you can edit the Auto Scaling policies by clicking on the Advanced Options when you create your cluster:
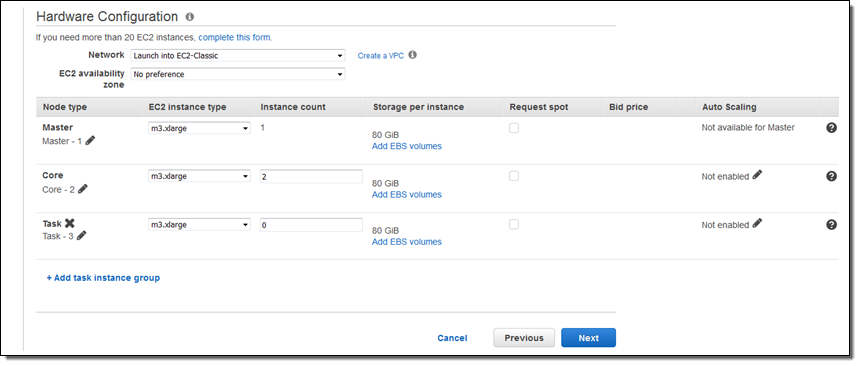
Simply click on the pencil icon to begin editing your policy. Here’s my Scale out policy:
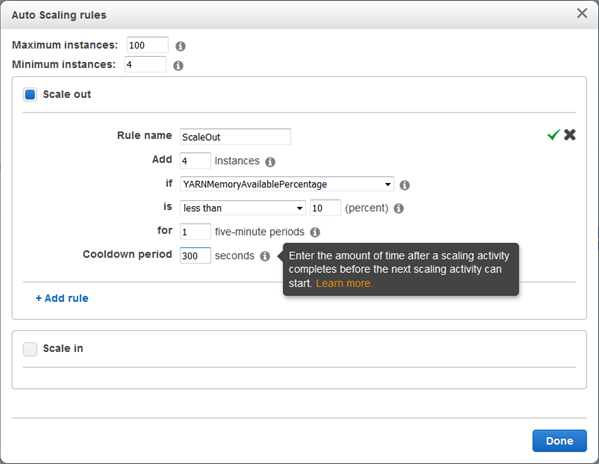
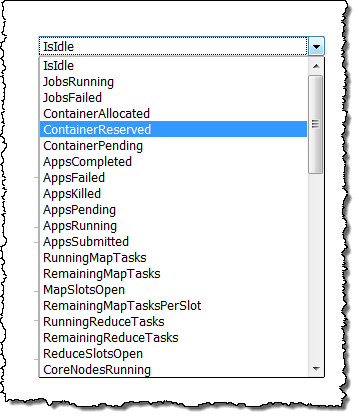
Because this policy is driven by YARNMemoryAvailablePercentage, it will be activated under low-memory conditions when I am running a YARN-based framework such as Spark, Tez, or Hadoop MapReduce. I can choose many other metrics as well; here are some of my options:
And here’s my Scale in policy:
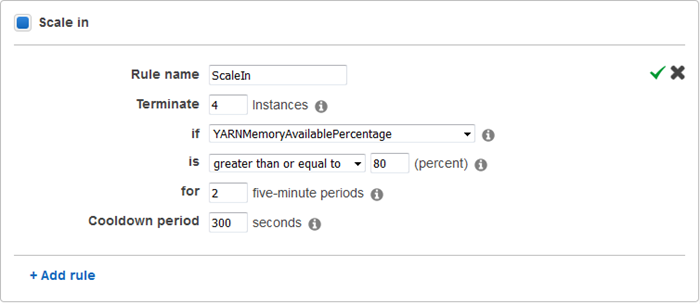
I can choose from the same set of metrics, and I can set a Cooldown period for each policy. This value sets the minimum amount of time between scaling activities, and allows the metrics to stabilize as the changes take effect.
Default policies (driven by YARNMemoryAvailablePercentage and ContainerPendingRatio) are also available in the console.
Available Now
To learn more about Auto Scaling, read about Scaling Cluster Resources in the EMR Management Guide.
This feature is available now and you start using it today. Simply select emr-5.1.0 from the Release menu to get started!
— Jeff;