AWS News Blog
New serverless customization in Amazon SageMaker AI accelerates model fine-tuning

|
Today, I’m happy to announce new serverless customization in Amazon SageMaker AI for popular AI models, such as Amazon Nova, DeepSeek, GPT-OSS, Llama, and Qwen. The new customization capability provides an easy-to-use interface for the latest fine-tuning techniques like reinforcement learning, so you can accelerate the AI model customization process from months to days.
With a few clicks, you can seamlessly select a model and customization technique, and handle model evaluation and deployment—all entirely serverless so you can focus on model tuning rather than managing infrastructure. When you choose serverless customization, SageMaker AI automatically selects and provisions the appropriate compute resources based on the model and data size.
Getting started with serverless model customization
You can get started customizing models in Amazon SageMaker Studio. Choose Models in the left navigation pane and check out your favorite AI models to be customized.
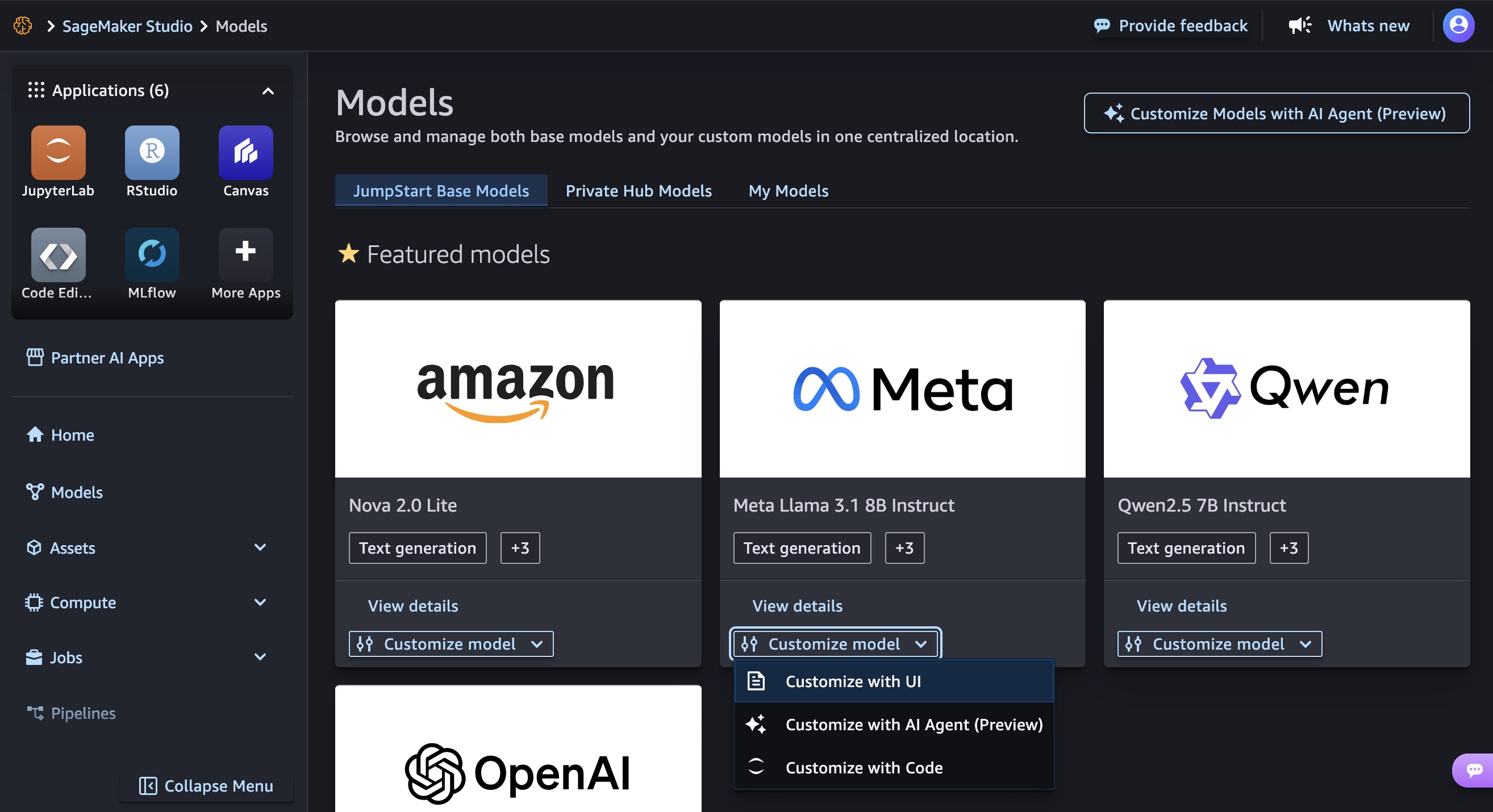
Customize with UI
You can customize AI models in a only few clicks. In the Customize model dropdown list for a specific model such as Meta Llama 3.1 8B Instruct, choose Customize with UI.
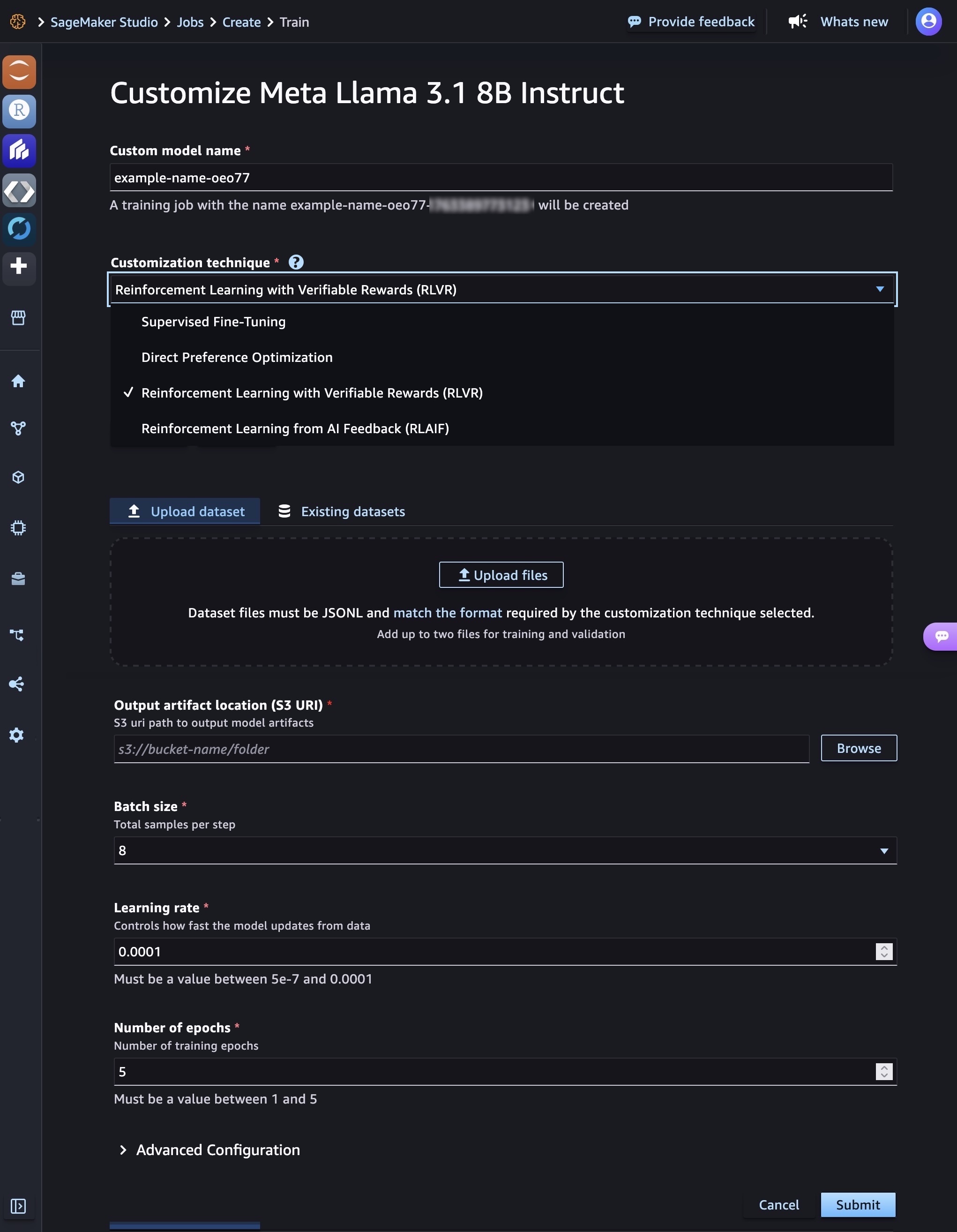
You can select a customization technique used to adapt the base model to your use case. SageMaker AI supports Supervised Fine-Tuning and the latest model customization techniques including Direct Preference Optimization, Reinforcement Learning from Verifiable Rewards (RLVR), and Reinforcement Learning from AI Feedback (RLAIF). Each technique optimizes models in different ways, with selection influenced by factors such as dataset size and quality, available computational resources, task at hand, desired accuracy levels, and deployment constraints.
Upload or select a training dataset to match the format required by the customization technique selected. Use the values of batch size, learning rate, and number of epochs recommended by the technique selected. You can configure advanced settings such as hyperparameters, a newly introduced serverless MLflow application for experiment tracking, and network and storage volume encryption. Choose Submit to get started on your model training job.
After your training job is complete, you can see the models you created in the My Models tab. Choose View details in one of your models.
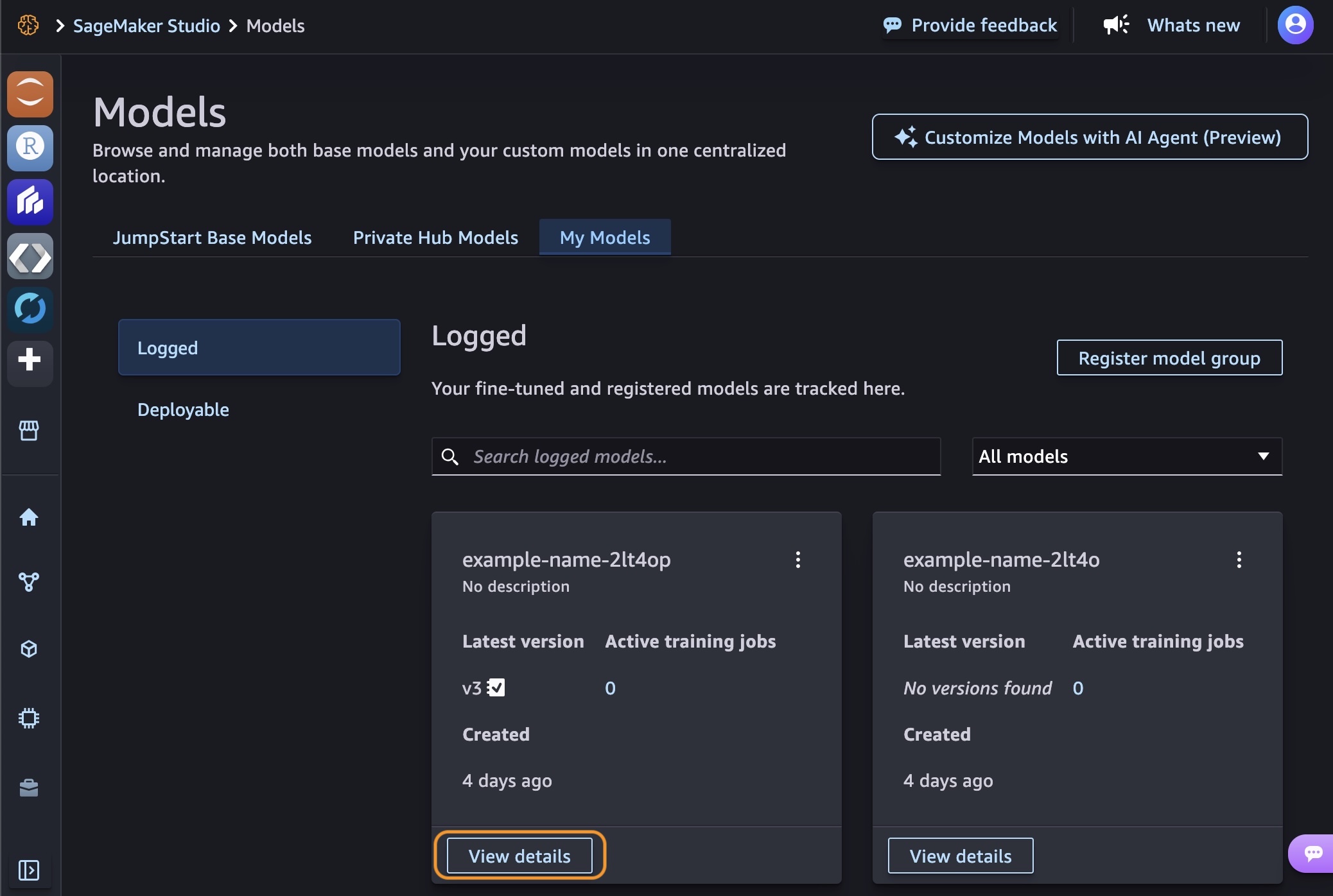
By choosing Continue customization, you can continue to customize your model by adjusting hyperparameters or training with different techniques. By choosing Evaluate, you can evaluate your customized model to see how it performs compared to the base model.
When you complete both jobs, you can choose either the SageMaker or Bedrock in the Deploy dropdown list to deploy your model.
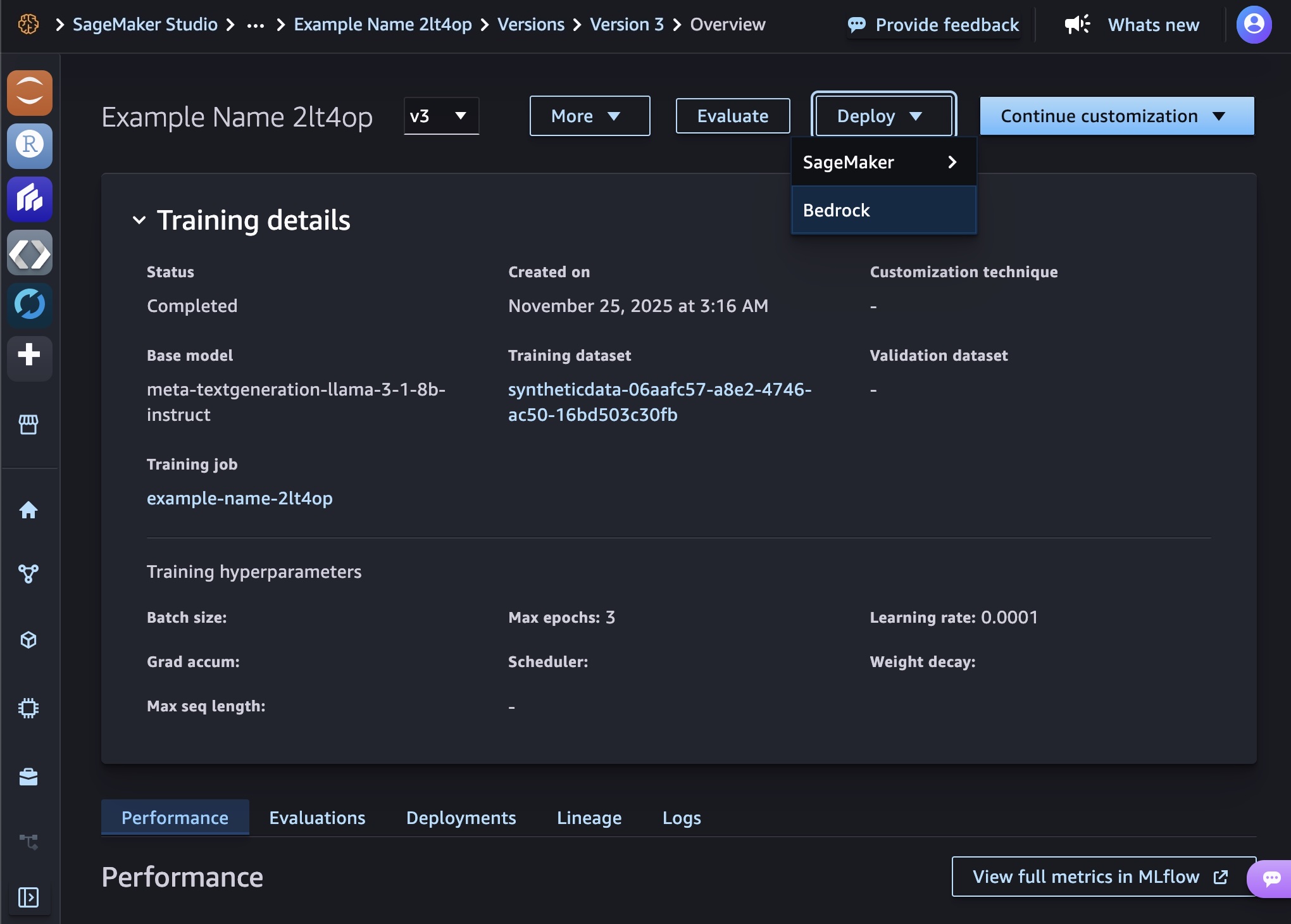
You can choose Amazon Bedrock for serverless inference. Choose Bedrock and the model name to deploy the model into Amazon Bedrock. To find your deployed models, choose Imported models in the Bedrock console.
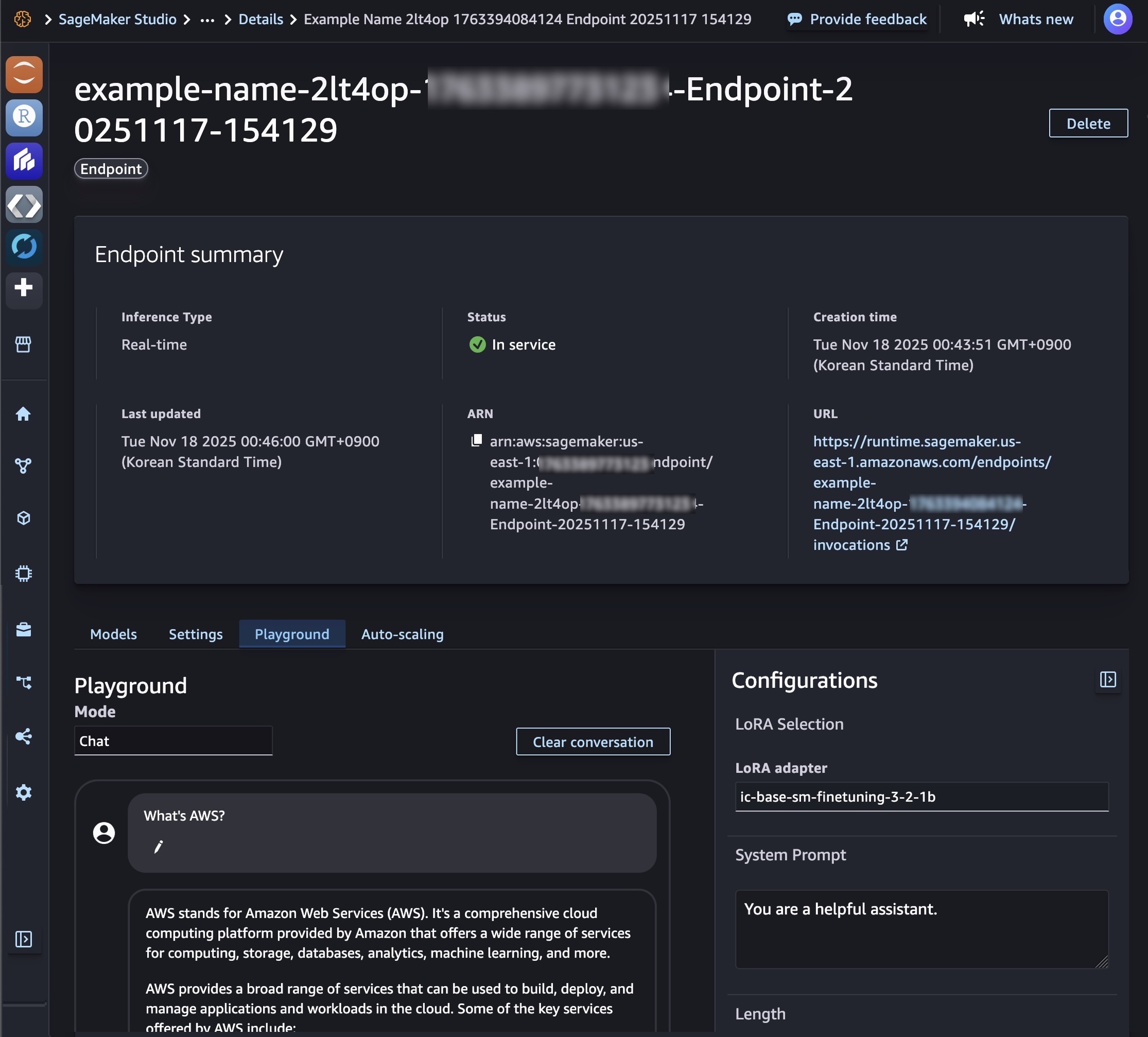
You can also deploy your model to a SageMaker AI inference endpoint if you want to control your deployment resources such as an instance type and instance count. After the SageMaker AI deployment is In service, you can use this endpoint to perform inference. In the Playground tab, you can test your customized model with a single prompt or chat mode.
With the serverless MLflow capability, you can automatically log all critical experiment metrics without modifying code and access rich visualizations for further analysis.
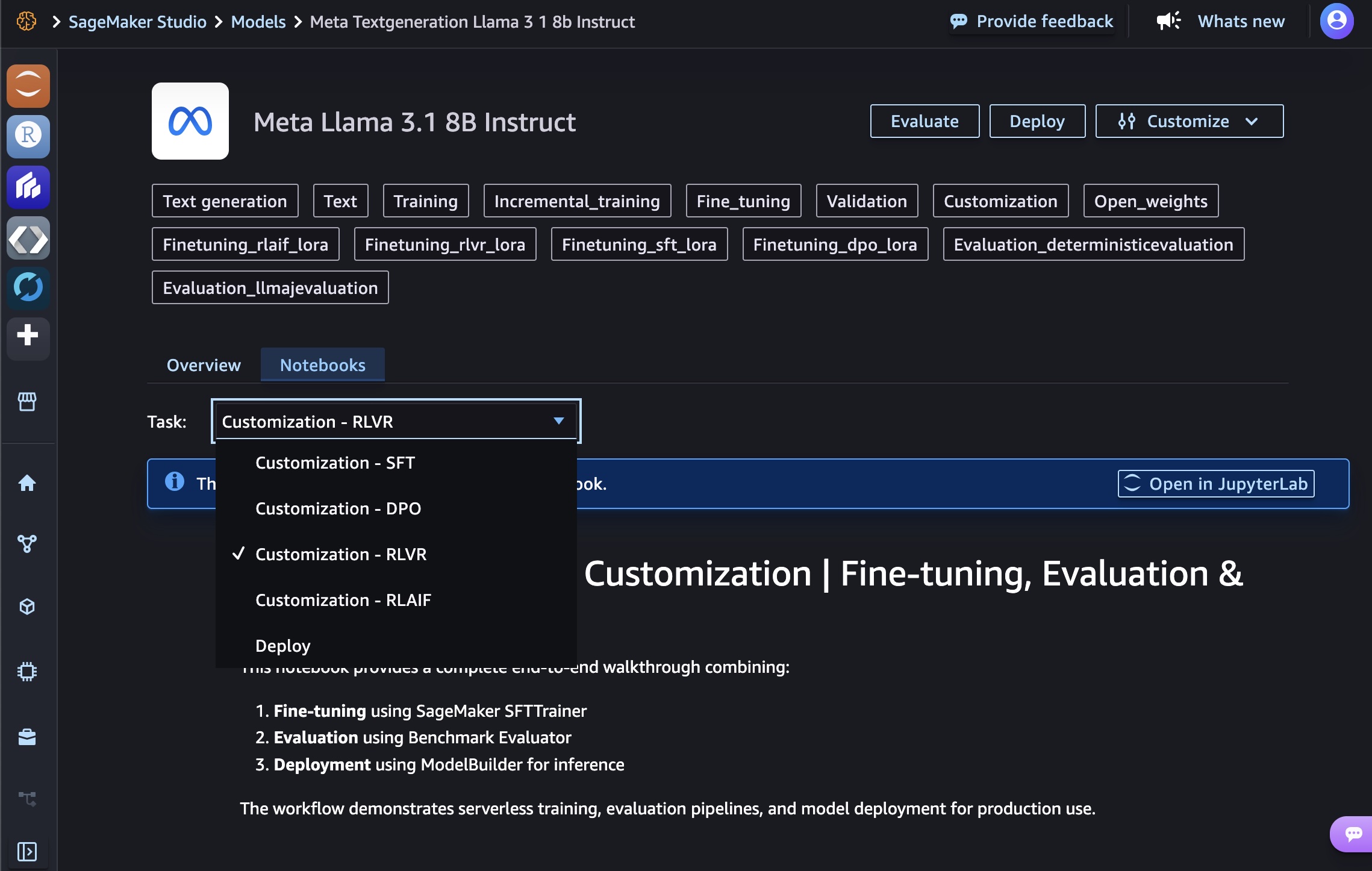
Customize with code
When you choose customizing with code, you can see a sample notebook to fine-tune or deploy AI models. If you want to edit the sample notebook, open it in JupyterLab. Alternatively, you can deploy the model immediately by choosing Deploy.
You can choose the Amazon Bedrock or SageMaker AI endpoint by selecting the deployment resources either from Amazon SageMaker Inference or Amazon SageMaker Hyperpod.
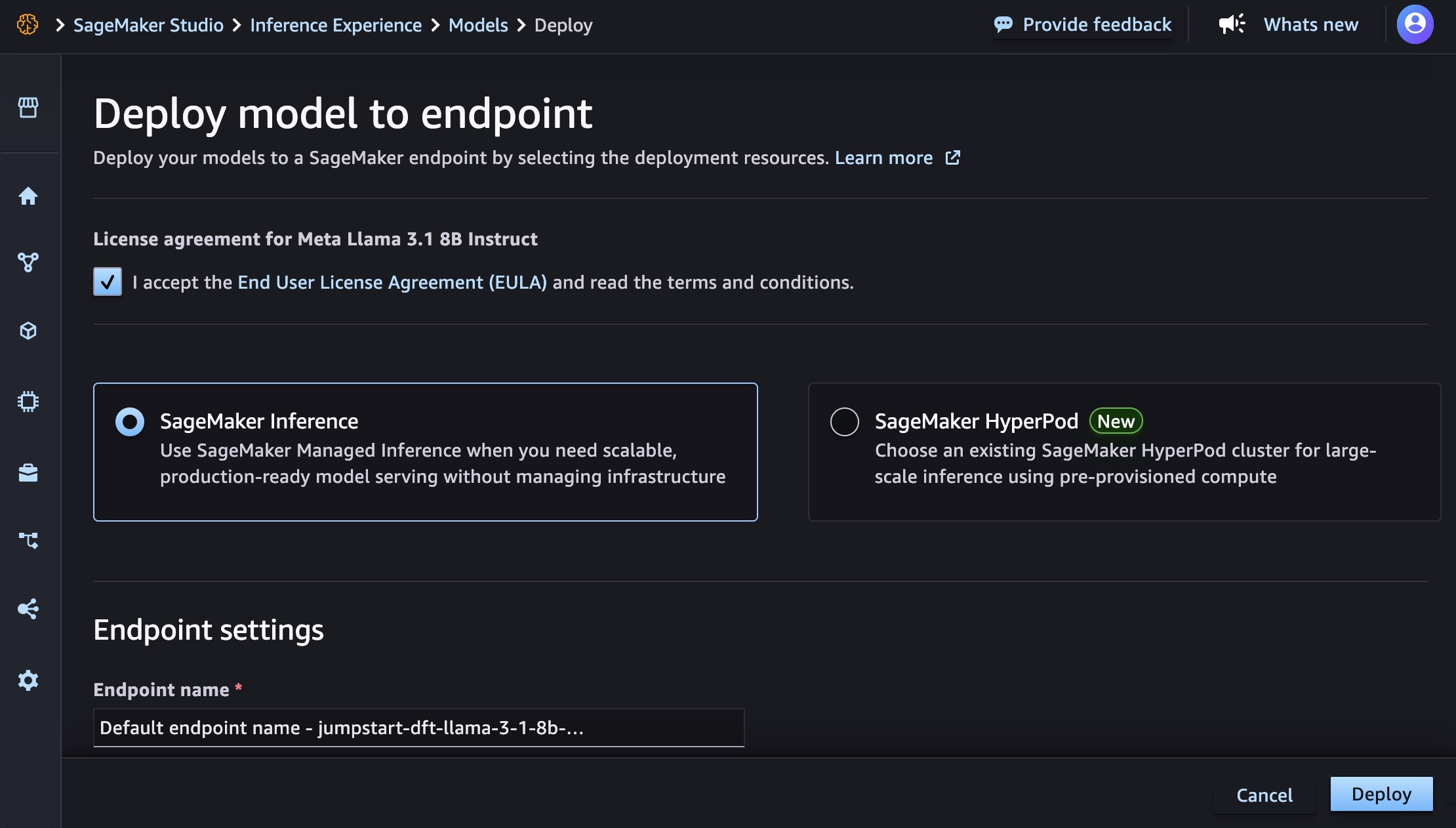
When you choose Deploy on the bottom right of the page, it will be redirected back to the model detail page. After the SageMaker AI deployment is in service, you can use this endpoint to perform inference.
Okay, you’ve seen how to streamline the model customization in the SageMaker AI. You can now choose your favorite way. To learn more, visit the Amazon SageMaker AI Developer Guide.
Now available
New serverless AI model customization in Amazon SageMaker AI is now available in US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) Regions. You only pay for the tokens processed during training and inference. To learn more details, visit Amazon SageMaker AI pricing page.
Give it a try in Amazon SageMaker Studio and send feedback to AWS re:Post for SageMaker or through your usual AWS Support contacts.
— Channy