AWS Big Data Blog
Benchmark the performance of the new Auto WLM with adaptive concurrency in Amazon Redshift
With Amazon Redshift, you can run a complex mix of workloads on your data warehouse clusters. For example, frequent data loads run alongside business-critical dashboard queries and complex transformation jobs. We also see more and more data science and machine learning (ML) workloads. Each workload type has different resource needs and different service level agreements. How does Amazon Redshift give you a consistent experience for each of your workloads? Amazon Redshift workload management (WLM) helps you maximize query throughput and get consistent performance for the most demanding analytics workloads, all while optimally using the resources of your existing cluster.
Amazon Redshift has recently made significant improvements to automatic WLM (Auto WLM) to optimize performance for the most demanding analytics workloads. With the release of Amazon Redshift Auto WLM with adaptive concurrency, Amazon Redshift can now dynamically predict and allocate the amount of memory to queries needed to run optimally. Amazon Redshift dynamically schedules queries for best performance based on their run characteristics to maximize cluster resource utilization.
In this post, we discuss what’s new with WLM and the benefits of adaptive concurrency in a typical environment. We synthesized a mixed read/write workload based on TPC-H to show the performance characteristics of a workload with a highly tuned manual WLM configuration versus one with Auto WLM. In this experiment, Auto WLM configuration outperformed manual configuration by a great margin. From a throughput standpoint (queries per hour), Auto WLM was 15% better than the manual workload configuration. Overall, we observed 26% lower average response times (runtime + queue wait) with Auto WLM.
What’s new with Amazon Redshift WLM?
Workload management allows you to route queries to a set of defined queues to manage the concurrency and resource utilization of the cluster. Today, Amazon Redshift has both automatic and manual configuration types. With manual WLM configurations, you’re responsible for defining the amount of memory allocated to each queue and the maximum number of queries, each of which gets a fraction of that memory, which can run in each of their queues. Manual WLM configurations don’t adapt to changes in your workload and require an intimate knowledge of your queries’ resource utilization to get right. Amazon Redshift Auto WLM doesn’t require you to define the memory utilization or concurrency for queues. Auto WLM adjusts the concurrency dynamically to optimize for throughput. Optionally, you can define queue priorities in order to provide queries preferential resource allocation based on your business priority.
Auto WLM also provides powerful tools to let you manage your workload. Query priorities lets you define priorities for workloads so they can get preferential treatment in Amazon Redshift, including more resources during busy times for consistent query performance, and query monitoring rules offer ways to manage unexpected situations like detecting and preventing runaway or expensive queries from consuming system resources.
Our initial release of Auto WLM in 2019 greatly improved the out-of-the-box experience and throughput for the majority of customers. However, in a small number of situations, some customers with highly demanding workloads had developed highly tuned manual WLM configurations for which Auto WLM didn’t demonstrate a significant improvement. Over the past 12 months, we worked closely with those customers to enhance Auto WLM technology with the goal of improving performance beyond the highly tuned manual configuration. One of our main innovations is adaptive concurrency. With adaptive concurrency, Amazon Redshift uses ML to predict and assign memory to the queries on demand, which improves the overall throughput of the system by maximizing resource utilization and reducing waste.
Electronic Arts, Inc. is a global leader in digital interactive entertainment. EA develops and delivers games, content, and online services for internet-connected consoles, mobile devices, and personal computers. EA has more than 300 million registered players around the world. Electronic Arts uses Amazon Redshift to gather player insights and has immediately benefited from the new Amazon Redshift Auto WLM.
“By adopting Auto WLM, our Amazon Redshift cluster throughput increased by at least 15% on the same hardware footprint. Our average concurrency increased by 20%, allowing approximately 15,000 more queries per week now. All this with marginal impact to the rest of the query buckets or customers. Because Auto WLM removed hard walled resource partitions, we realized higher throughput during peak periods, delivering data sooner to our game studios.”
– Alex Ignatius, Director of Analytics Engineering and Architecture for the EA Digital Platform.
Benefits of Amazon Redshift Auto WLM with adaptive concurrency
Amazon Redshift has implemented an advanced ML predictor to predict the resource utilization and runtime for each query. The model continuously receives feedback about prediction accuracy and adapts for future runs. Higher prediction accuracy means resources are allocated based on query needs. This allows for higher concurrency of light queries and more resources for intensive queries. The latter leads to improved query and cluster performance because less temporary data is written to storage during a complex query’s processing. A unit of concurrency (slot) is created on the fly by the predictor with the estimated amount of memory required, and the query is scheduled to run. If you have a backlog of queued queries, you can reorder them across queues to minimize the queue time of short, less resource-intensive queries while also ensuring that long-running queries aren’t being starved. We also make sure that queries across WLM queues are scheduled to run both fairly and based on their priorities.
The following are key areas of Auto WLM with adaptive concurrency performance improvements:
- Proper allocation of memory – Reduction of over-allocation of memory creates more room for other queries to run and increases concurrency. Additionally, reduction of under-allocation reduces spill to disk and therefore improves query performance.
- Elimination of static partitioning of memory between queues – This frees up the entire available memory, which is then available for queries.
- Improved throughput – You can pack more queries into the system due to more efficient memory utilization.
The following diagram shows how a query moves through the Amazon Redshift query run path to take advantage of the improvements of Auto WLM with adaptive concurrency.

Benchmark test
To assess the efficiency of Auto WLM, we designed the following benchmark test. It’s a synthetic read/write mixed workload using TPC-H 3T and TPC-H 100 GB datasets to mimic real-world workloads like ad hoc queries for business analysis.
In this modified benchmark test, the set of 22 TPC-H queries was broken down into three categories based on the run timings. The shortest queries were categorized as DASHBOARD, medium ones as REPORT, and longest-running queries were marked as the DATASCIENCE group. The DASHBOARD queries were pointed to a smaller TPC-H 100 GB dataset to mimic a datamart set of tables. The COPY jobs were to load a TPC-H 100 GB dataset on top of the existing TPC-H 3 T dataset tables. The REPORT and DATASCIENCE queries were ran against the larger TPC-H 3 T dataset as if those were ad hoc and analyst-generated workloads against a larger dataset. Also, the TPC-H 3 T dataset was constantly getting larger through the hourly COPY jobs as if extract, transform, and load (ETL) was running against this dataset.
The following table summarizes the synthesized workload components.
| Schema: tpch100g | Schema: tpch3t | ||
| Data Set -TPC-H 100 GB | Data Set – TPC-H 3T | ||
| Workload Types | DASH | 16 dashboard queries running every 2 seconds | |
| REPORT | 6 report queries running every 15 minutes | ||
| DATASCIENCE | 4 data science queries running every 30 minutes | ||
| COPY | 3 COPY jobs every hour loading TPC-H 100 GB data on to TPC-H 3 T |
The following table summarizes the manual and Auto WLM configurations we used.
| Manual Configuration | Auto Configuration | ||||||||
| Queues/Query Groups | Memory % | Max Concurrency | Concurrency Scaling | Priority | Memory % | Max Concurrency | Concurrency Scaling | Priority | |
| Dashboard | 24 | 5 | Off | NA | Auto | Auto | Off | Normal | |
| Report | 25 | 6 | Off | NA | Auto | Auto | Off | Normal | |
| DataScience | 25 | 4 | Off | NA | Auto | Auto | Off | Normal | |
| COPY | 25 | 3 | Off | NA | Auto | Auto | Off | Normal | |
| Default | 1 | 1 | Off | NA | Auto | Auto | Off | Normal | |
We ran the benchmark test using two 8-node ra3.4xlarge instances, one for each configuration. The same exact workload ran on both clusters for 12 hours.
Summary of results
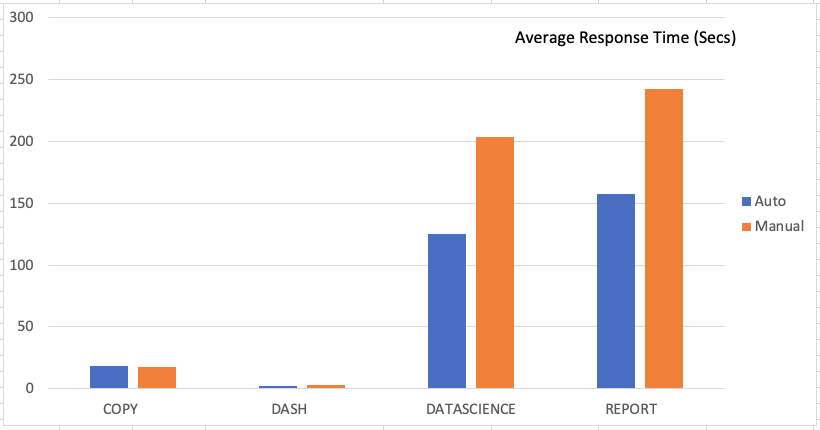
We noted that manual and Auto WLM had similar response times for COPY, but Auto WLM made a significant boost to the DATASCIENCE, REPORT, and DASHBOARD query response times, which resulted in a high throughput for DASHBOARD queries (frequent short queries).
Given the same controlled environment (cluster, dataset, queries, concurrency), Auto WLM with adaptive concurrency managed the workload more efficiently and provided higher throughput than the manual WLM configuration. Better and efficient memory management enabled Auto WLM with adaptive concurrency to improve the overall throughput. Elimination of the static memory partition created an opportunity for higher parallelism. More short queries were processed though Auto WLM, whereas longer-running queries had similar throughput. To optimize the overall throughput, adaptive concurrency control kept the number of longer-running queries at the same level but allowed more short-running queries to run in parallel.
Detailed results
In this section, we review the results in more detail.
Throughput and average response times
The following table summarizes the throughput and average response times, over a runtime of 12 hours. Response time is runtime + queue wait time.
| WLM Configuration | Query Type | Count of Queries | Total Response Time (Secs) | Average Response Time (Secs) |
| Auto | COPY | 72 | 1329 | 18.46 |
| Manual | COPY | 72 | 1271 | 17.65 |
| Auto | DASH | 126102 | 271691 | 2.15 |
| Manual | DASH | 109774 | 304551 | 2.77 |
| Auto | DATASCIENCE | 166 | 20768 | 125.11 |
| Manual | DATASCIENCE | 160 | 32603 | 203.77 |
| Auto | REPORT | 247 | 38986 | 157.84 |
| Manual | REPORT | 230 | 55693 | 242.14 |
| Auto Total | 126587 | 332774 | 2.63 | |
| Manual Total | 110236 | 394118 | 3.58 | |
| Auto Over Manual (%) | 14.83% | -26.47% |
The following chart shows the throughput (queries per hour) gain (automatic throughput) over manual (higher is better).

The following chart shows the average response time of each query (lower is better).
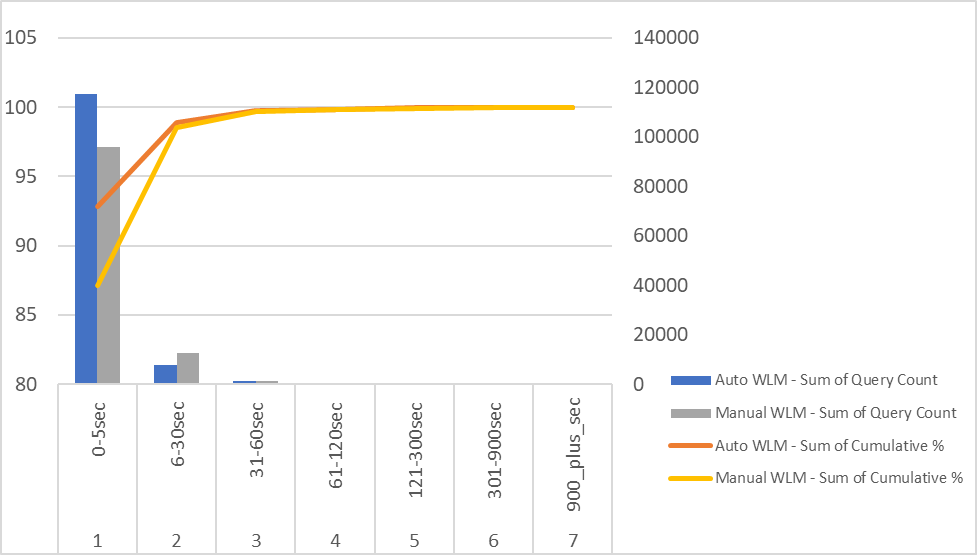
Bucket by query completion times
The following results data shows a clear shift towards left for Auto WLM. More and more queries completed in a shorter amount of time with Auto WLM.
| % of queries completed in | ||||||||
| WLM Configuration | Total Queries | 0-5 seconds | 6-30 seconds | 31-60 seconds | 61-120 seconds | 121-300 seconds | 301-900 seconds | Over 900 seconds |
| Manual | 110155 | 87.14 | 11.37 | 1.2 | 0.09 | 0.1 | 0.09 | 0.01 |
| Auto | 126477 | 92.82 | 6.06 | 0.85 | 0.13 | 0.09 | 0.03 | 0.01 |
The following chart visualizes these results.
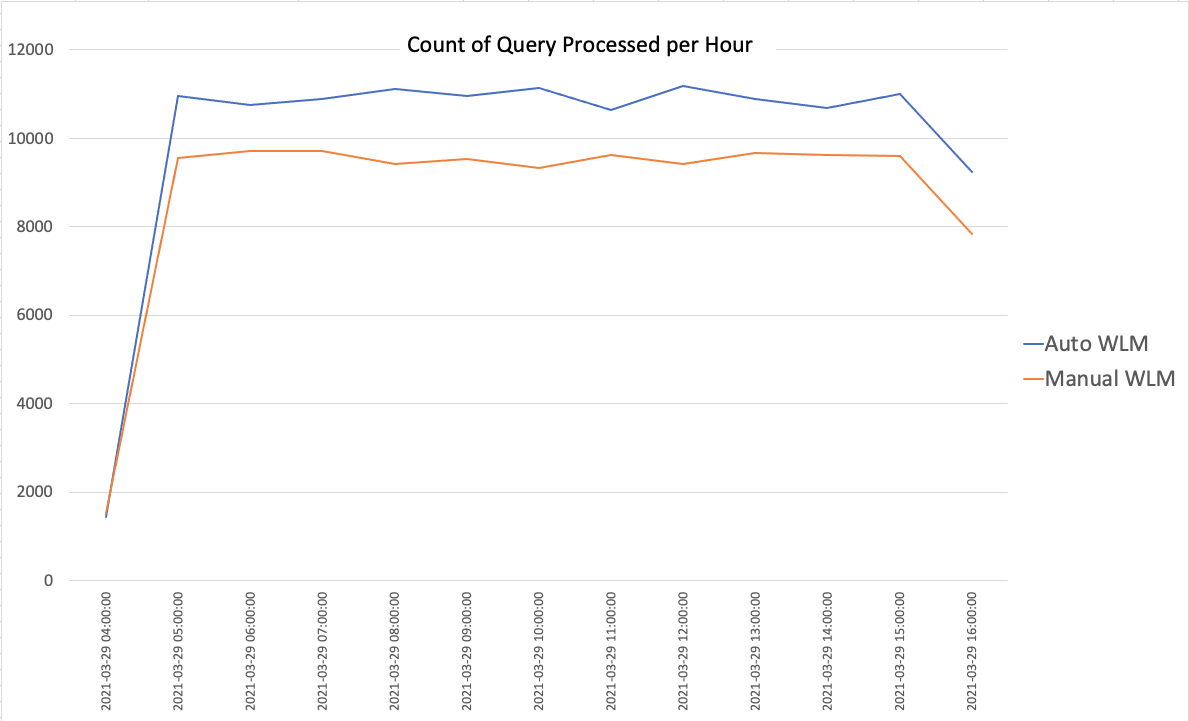
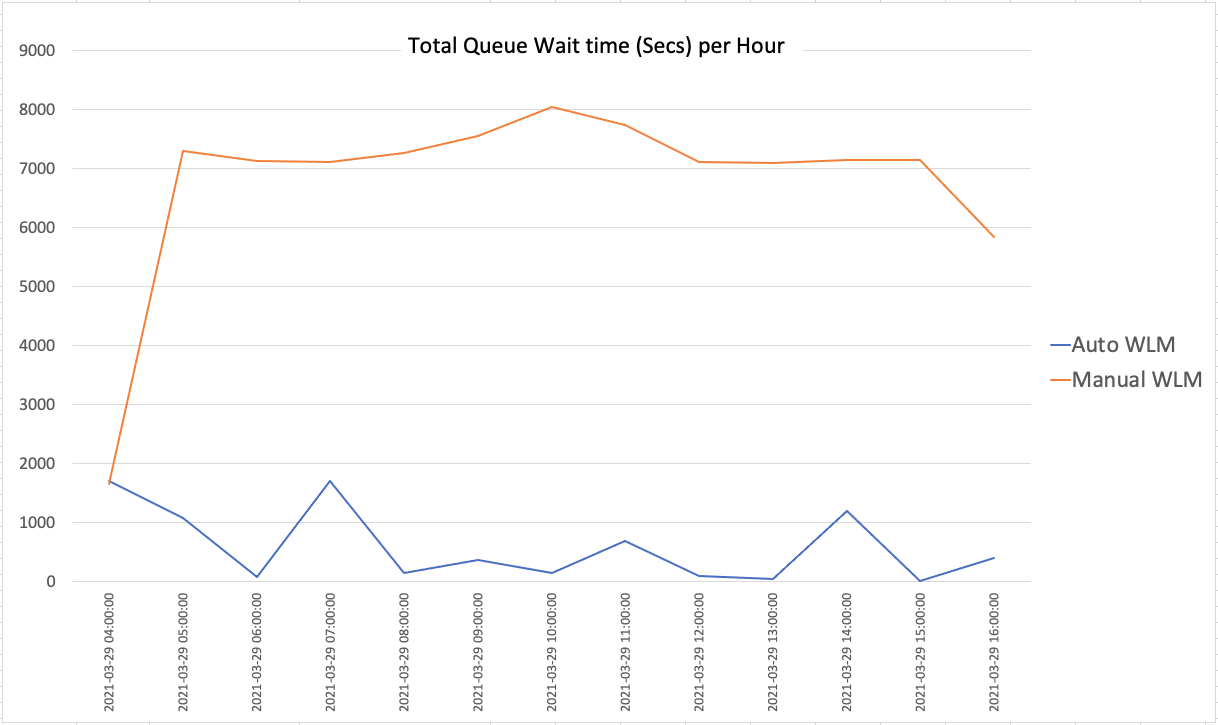
Query latency and count over time
As we can see from the following charts, Auto WLM significantly reduces the queue wait times on the cluster.
The following chart shows the count of queries processed per hour (higher is better).
The following chart shows the count of queued queries (lower is better).

The following chart shows the total queue wait time per hour (lower is better).
Temporary data spill to disk
Because it correctly estimated the query runtime memory requirements, Auto WLM configuration was able to reduce the runtime spill of temporary blocks to disk. Basically, a larger portion of the queries had enough memory while running that those queries didn’t have to write temporary blocks to disk, which is good thing. This in turn improves query performance.
The following chart shows that DASHBOARD queries had no spill, and COPY queries had a little spill.
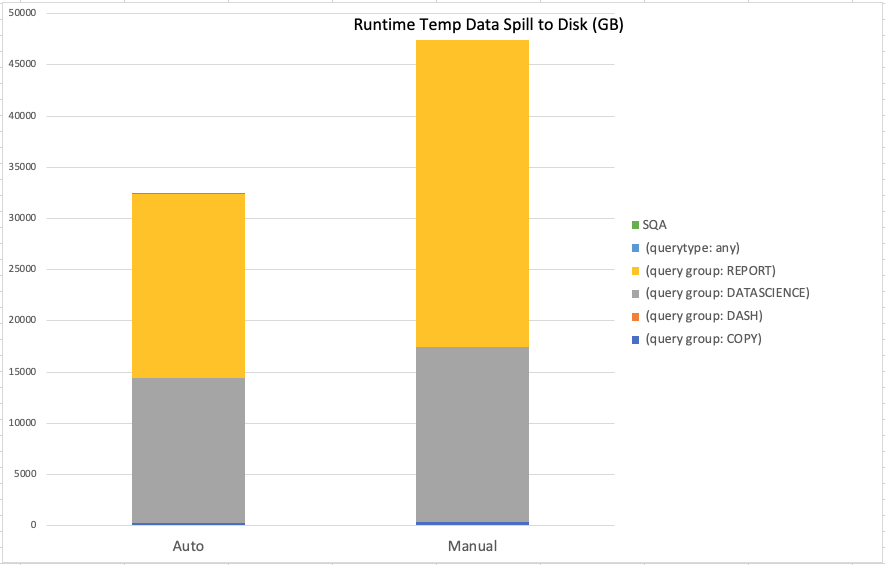
Auto WLM outperforms the manual configuration
Based on these tests, Auto WLM was a better choice than manual configuration. If we look at the three main aspects where Auto WLM provides greater benefits, a mixed workload (manual WLM with multiple queues) reaps the most benefits using Auto WLM. The majority of the large data warehouse workloads consists of a well-defined mixture of short, medium, and long queries, with some ETL process on top of it. So large data warehouse systems have multiple queues to streamline the resources for those specific workloads. Also, overlap of these workloads can occur throughout a typical day. If the Amazon Redshift cluster has a good mixture of workloads and they don’t overlap with each other 100% of the time, Auto WLM can use those underutilized resources and provide better performance for other queues.
Conclusion
Our test demonstrated that Auto WLM with adaptive concurrency outperforms well-tuned manual WLM for mixed workloads. If you’re using manual WLM with your Amazon Redshift clusters, we recommend using Auto WLM to take advantage of its benefits. Moreover, Auto WLM provides the query priorities feature, which aligns the workload schedule with your business-critical needs.
For more information about Auto WLM, see Implementing automatic WLM and the definition and workload scripts for the benchmark.
About the Authors
 Raj Sett is a Database Engineer at Amazon Redshift. He is passionate about optimizing workload and collaborating with customers to get the best out of Redshift. Outside of work, he loves to drive and explore new places.
Raj Sett is a Database Engineer at Amazon Redshift. He is passionate about optimizing workload and collaborating with customers to get the best out of Redshift. Outside of work, he loves to drive and explore new places.

Paul Lappas is a Principal Product Manager at Amazon Redshift. Paul is passionate about helping customers leverage their data to gain insights and make critical business decisions. In his spare time Paul enjoys playing tennis, cooking, and spending time with his wife and two boys.
 Gaurav Saxena is a software engineer on the Amazon Redshift query processing team. He works on several aspects of workload management and performance improvements for Amazon Redshift. In his spare time, he loves to play games on his PlayStation.
Gaurav Saxena is a software engineer on the Amazon Redshift query processing team. He works on several aspects of workload management and performance improvements for Amazon Redshift. In his spare time, he loves to play games on his PlayStation.
 Mohammad Rezaur Rahman is a software engineer on the Amazon Redshift query processing team. He focuses on workload management and query scheduling. In his spare time, he loves to spend time outdoor with family.
Mohammad Rezaur Rahman is a software engineer on the Amazon Redshift query processing team. He focuses on workload management and query scheduling. In his spare time, he loves to spend time outdoor with family.