AWS Big Data Blog
Category: Amazon Redshift

Patch perfect: Automating Amazon Redshift patch testing
In this post, we demonstrate an automated test suite that validates your Amazon Redshift cluster automatically after any patch, reboot, or modification. It uses standard drivers against real workload patterns to provide a verified gate between a patch landing and that patch reaching production.
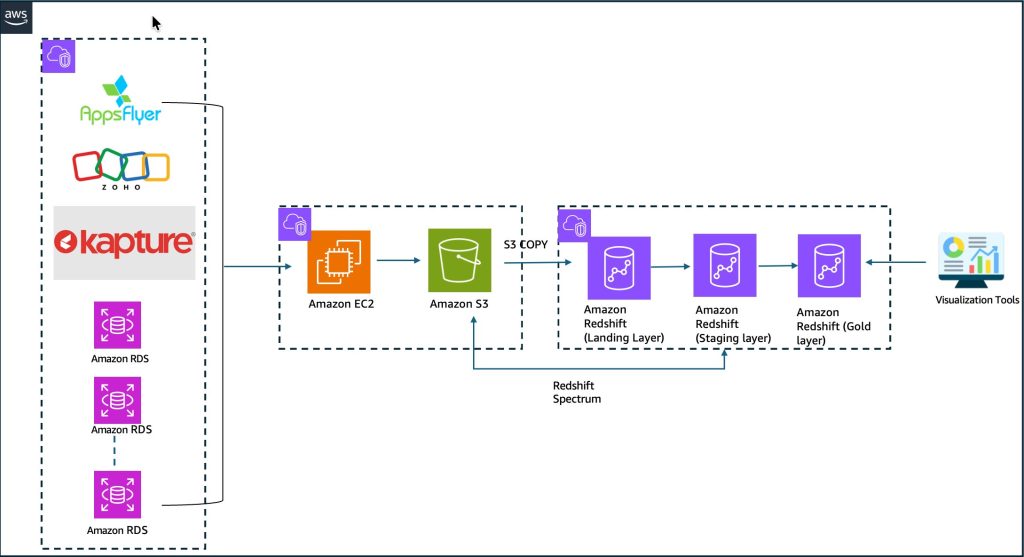
How BigBasket uses the Iceberg based lakehouse architecture on AWS to power lightning-fast grocery delivery across India
In this post, we demonstrate how BigBasket implemented the lakehouse architecture on AWS, including their architecture decisions, implementation approach, and the measurable business results you can expect from a similar modernization. Whether you’re facing scalability challenges or planning your own lakehouse implementation, this blueprint provides actionable insights you can adapt for your organization.

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

Amazon Redshift RG: Faster and lower cost, Graviton-powered
In this post, we describe the innovations that make RG instances so much faster. We also share benchmark results showing that RG delivers up to 4.2x better price-performance than other leading data warehouses.

AI-powered performance recommendations for Amazon Redshift
In this post, you learn how to build an AI-powered solution that collects the telemetry, pre-computes performance signals, correlates them with CloudWatch, and uses Amazon Bedrock to generate prioritized recommendations.

Amazon Redshift delivers faster performance for BI dashboards and real-time analytics
Today, we’re excited to announce a new performance optimization in Amazon Redshift that improves the response times of low-latency SQL queries, such as those used in real-time analytics applications or generated by BI dashboards. With this enhancement, you can experience improved query latencies because of a reduction in the time Amazon Redshift spends preparing SQL queries for execution. SQL queries start faster, so they return results quicker.

Multi-Region identity-based access to Amazon Redshift and S3 Tables
In Part 1 of this series, we showed how to simplify enterprise data access using the Amazon Redshift integration with Amazon S3 Access Grants. In this post, we extend that solution across AWS Regions. We introduce a fictional company, AnyCompany Global, to illustrate how organizations with global operations can use AWS IAM Identity Center Multi-Region to set up consistent, identity-based access to Amazon Redshift and Amazon S3 Tables across Regions.

Unlock cost savings with incremental snapshot billing for Amazon Redshift Serverless and Amazon Redshift RG
Starting June 8, 2026, Amazon Redshift is introducing an incremental snapshot billing model for Amazon Redshift Serverless and Amazon Redshift RG (provisioned instances powered by AWS Graviton). With this enhancement, you pay only for the unique data blocks across your active manual snapshots within your account. This delivers significant cost savings for customers who have multiple snapshots that contain largely identical data blocks. In this post, you will learn how the new incremental snapshot billing model works, the customer use cases it addresses, and how it helps you optimize costs while improving your Recovery Point Objective (RPO).

Query Amazon Redshift using natural language with Kiro
In this post, you learn how to set up Kiro with the Amazon Redshift MCP server to query your data warehouse using natural language. You explore cluster discovery, schema browsing, analytical queries, cross-cluster comparisons, and data quality checks, all without writing SQL from scratch or switching between tools.

How Zynga scaled multi-warehouse data governance with Amazon Redshift federated permissions
In this post, we walk through how Zynga adopted Amazon Redshift federated permissions and AWS IAM Identity Center to enforce consistent, tiered data access across provisioned and serverless Amazon Redshift environments without building custom synchronization pipelines.