AWS Big Data Blog
Category: AWS Big Data

Streamlined monitoring and debugging for Amazon EMR on EC2
In this post, we walk you through five key enhancements: Amazon CloudWatch Logs integration, step-level Amazon Simple Storage Service (Amazon S3) logging controls, expanded console UIs for YARN and Tez, Amazon EMR step to YARN application ID mapping, and enhanced custom metrics with updated documentation.

How to use streamlined permissions for Amazon S3 Tables and Iceberg materialized views
In this post, we walk through how to set up and manage S3 Tables in the AWS Glue Data Catalog, create and query Iceberg materialized views, and configure access controls that work across your analytics stack with IAM-based authorization.

Building unified data pipelines with Apache Iceberg and Apache Flink
In this post, you build a unified pipeline using Apache Iceberg and Amazon Managed Service for Apache Flink that replaces the dual-pipeline approach. This walkthrough is for intermediate AWS users who are comfortable with Amazon Simple Storage Service (Amazon S3) and AWS Glue Data Catalog but new to streaming from Apache Iceberg tables.

Proactive monitoring for Amazon Redshift Serverless using AWS Lambda and Slack alerts
In this post, we show you how to build a serverless, low-cost monitoring solution for Amazon Redshift Serverless that proactively detects performance anomalies and sends actionable alerts directly to your selected Slack channels.

Amazon EMR HBase on Amazon S3 transitioning to EMR S3A with comparable EMRFS performance
Starting with version 7.10, Amazon EMR is transitioning from EMR File System (EMRFS) to EMR S3A as the default file system connector for Amazon S3 access. This transition brings HBase on Amazon S3 to a new level, offering performance parity with EMRFS while delivering substantial improvements, including better standardization, improved portability, stronger community support, improved performance through non-blocking I/O, asynchronous clients, and better credential management with AWS SDK V2 integration. In this post, we discuss this transition and its benefits.
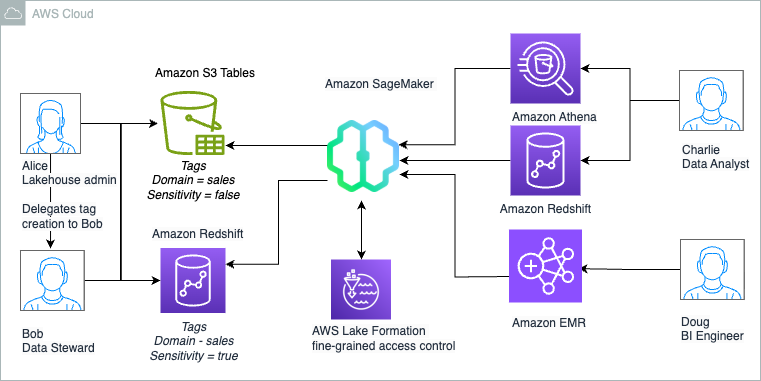
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Improve Amazon EMR HBase availability and tail latency using generational ZGC
Large-scale HBase deployments on Amazon EMR suffer from unpredictable garbage collection behavior that creates performance bottlenecks for business-critical applications. To solve this problem, Amazon EMR leverages Oracle’s generational ZGC technology from JDK 21 to deliver predictable, sub-millisecond pause times. This post shows you how to configure generational ZGC in Amazon EMR 7.10.0, apply performance tuning methods, and optimize HBase RegionServer garbage collection settings.

Enhance Amazon EMR observability with automated incident mitigation using Amazon Bedrock and Amazon Managed Grafana
In this post, we demonstrate how to integrate real-time monitoring with AI-powered remediation suggestions, combining Amazon Managed Grafana for visualization, Amazon Bedrock for intelligent response recommendations, and AWS Systems Manager for automated remediation actions on Amazon Web Services (AWS).

Stream data from Amazon MSK to Apache Iceberg tables in Amazon S3 and Amazon S3 Tables using Amazon Data Firehose
In this post, we walk through two solutions that demonstrate how to stream data from your Amazon MSK provisioned cluster to Iceberg-based data lakes in Amazon S3 using Amazon Data Firehose.

Build a secure serverless streaming pipeline with Amazon MSK Serverless, Amazon EMR Serverless and IAM
The post demonstrates a comprehensive, end-to-end solution for processing data from MSK Serverless using an EMR Serverless Spark Streaming job, secured with IAM authentication. Additionally, it demonstrates how to query the processed data using Amazon Athena, providing a seamless and integrated workflow for data processing and analysis. This solution enables near real-time querying of the latest data processed from MSK Serverless and EMR Serverless using Athena, providing instant insights and analytics.