AWS Big Data Blog
Category: Amazon EMR

High-performance Remote Shuffle Service on Amazon EMR with Apache Celeborn
In this post, we show how Apache Celeborn resolves this trade-off for Amazon EMR on EKS and Amazon EMR on EC2, improving job reliability while unlocking additional cost savings.

Multi-cloud lakehouse architecture on AWS for Agentic AI, Part 1: Architecture and best practices
This post focuses on explaining the architecture approach to build the open lakehouse architecture on AWS, unifying the metadata catalog across providers for the AI agents to access. In addition, it highlights the architecture trade-offs and best practices.
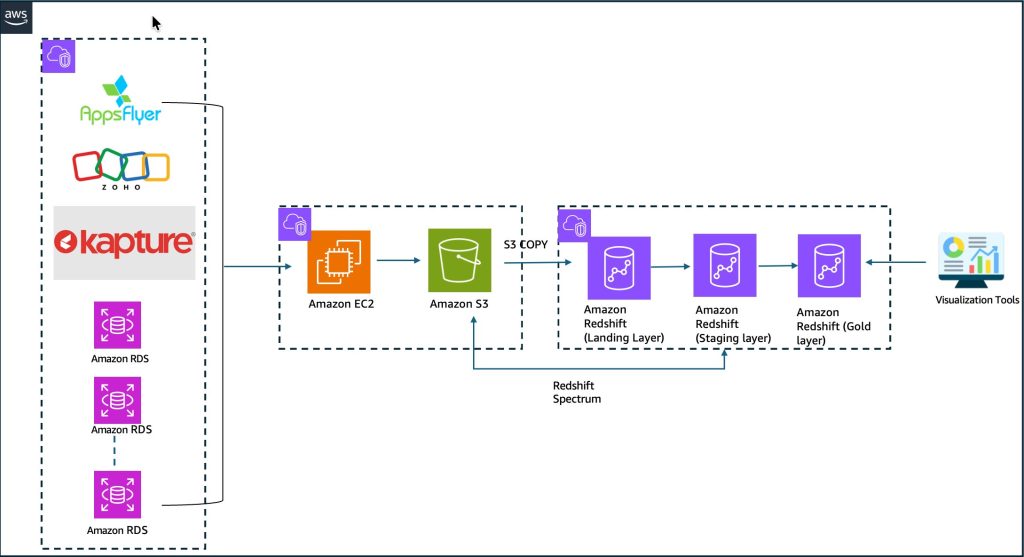
How BigBasket uses the Iceberg based lakehouse architecture on AWS to power lightning-fast grocery delivery across India
In this post, we demonstrate how BigBasket implemented the lakehouse architecture on AWS, including their architecture decisions, implementation approach, and the measurable business results you can expect from a similar modernization. Whether you’re facing scalability challenges or planning your own lakehouse implementation, this blueprint provides actionable insights you can adapt for your organization.

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

Upgrade PySpark from Spark 3.5 to Spark 4.0 with AWS Spark Upgrade Agent
In this post, we walk through a hands-on PySpark migration from Spark 3.5 to Spark 4.0 on Amazon EMR Serverless, using the AWS Spark Upgrade Agent. You’ll see how the agent iteratively validates your application on a live Amazon EMR Serverless application, automatically diagnosing and resolving failures from Amazon CloudWatch logs until the job succeeds.

Announcing Spark Connect on Amazon EMR Serverless: Interactive PySpark development, anywhere
Today, AWS is announcing support for Spark Connect on Amazon EMR Serverless with EMR release 7.13 (Apache Spark 3.5.6) and later versions. You can now build and debug Spark applications from your preferred local environment while running full-scale Spark operations on EMR Serverless.

Build stateful streaming applications with Apache Spark 4.0 on Amazon EMR Serverless
In this post, we demonstrate how to build a production-ready IoT device monitoring system using Spark 4.0’s transformWithState API on Amazon EMR Serverless. This example showcases the key capabilities of stateful streaming and provides a template you can adapt for your own use cases.

Announcing general availability of Apache Spark 4.0 on Amazon EMR
With this general availability announcement, Spark 4.0 is now supported across Amazon EMR Serverless, Amazon EMR on EC2, and Amazon EMR on EKS deployment options. In this post, you’ll learn about key Spark 4.0 capabilities now available on Amazon EMR including Spark Connect, the Variant data type, SQL scripting, Python API improvements, and streaming enhancements, along with infrastructure changes in the new emr-spark-8.0 release.

Capture data lineage of Amazon EMR spark jobs into Amazon SageMaker Unified Studio
In this post, you’ll walk through a practical, step-by-step example that shows how to capture and track data lineage from Spark jobs running on Amazon EMR directly into Amazon SageMaker Catalog using OpenLineage. You’ll see how lineage metadata flows automatically and explore data relationships and dependencies across your workflows in Amazon SageMaker Unified Studio.

A systematic approach to benchmarking SQL processing engines on AWS
Selecting the right SQL processing solution for large-scale data analytics is a critical decision for organizations. As data volumes grow exponentially, the technology landscape has evolved to offer diverse options for processing and analyzing this information efficiently. This post presents a systematic framework for evaluating and benchmarking SQL processing engines on AWS, using Apache JMeter to conduct practical performance testing at scale.