AWS Big Data Blog
Category: Best Practices

Implement multi-tenant search with Amazon OpenSearch Serverless next generation
In this post, we show how the next-generation OpenSearch Serverless architecture makes the collection-per-tenant model practical for multi-tenant search.

Why tombola chose Graviton-powered RG instances for Amazon Redshift
In this post, you learn how tombola followed a strict engineering principle: no changes to production without evidence. That meant a head-to-head comparison of RA3 versus RG on their actual workload. You also see benchmark results on Amazon S3 Tables and the migration from RA3 to RG instances.

Streamlined monitoring and debugging for Amazon EMR on EC2
In this post, we walk you through five key enhancements: Amazon CloudWatch Logs integration, step-level Amazon Simple Storage Service (Amazon S3) logging controls, expanded console UIs for YARN and Tez, Amazon EMR step to YARN application ID mapping, and enhanced custom metrics with updated documentation.

Improve DynamoDB analytics with AWS Glue zero-ETL schema and partition controls
In this post, you learn how to replicate Amazon DynamoDB data to Apache Iceberg tables in Amazon S3 through a zero-ETL integration. We walk through the challenges that the DynamoDB nested, schema-flexible data model introduces for analytics workloads, and show you how to configure schema unnesting and data partitioning for a sample product catalog table. We also cover how to query the replicated data in Amazon Athena using standard SQL.

A guide to capacity planning for Airflow worker pool in Amazon MWAA
In our previous post, A guide to Airflow worker pool optimization in Amazon MWAA, we explored when adding workers to your Amazon Managed Workflows for Apache Airflow (Amazon MWAA) environment actually solves performance issues, and when it doesn’t. We walked through patterns like high CPU utilization and long queue times where scaling may be appropriate, […]
A guide to Airflow worker pool optimization in Amazon MWAA
Optimizing the Airflow worker pool configuration in Amazon Managed Workflows for Apache Airflow (Amazon MWAA), the AWS fully managed Apache Airflow service, is an important yet often overlooked strategy for scaling workflow operations. Tasks queued for longer periods can create the illusion that additional workers are the solution, when in reality the root cause might […]

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 2
(Continued from Part 1) In this post, we show how you can give on-premises clients and spoke account resources private access to OpenSearch Serverless collections distributed across multiple business unit accounts.

Designing centralized and distributed network connectivity patterns for Amazon OpenSearch Serverless – Part 1
In this post, we show how organizations can provide secure, private access to multiple Amazon OpenSearch Serverless collections from both on-premises environments and distributed AWS accounts using a single centralized interface VPC endpoint and Route 53 Profiles.

Simplifying Kafka operations with Amazon MSK Express brokers
In this post, we show you how Amazon Managed Streaming for Apache Kafka (Amazon MSK) Express brokers brokers streamline the end-to-end activities for Kafka administration.
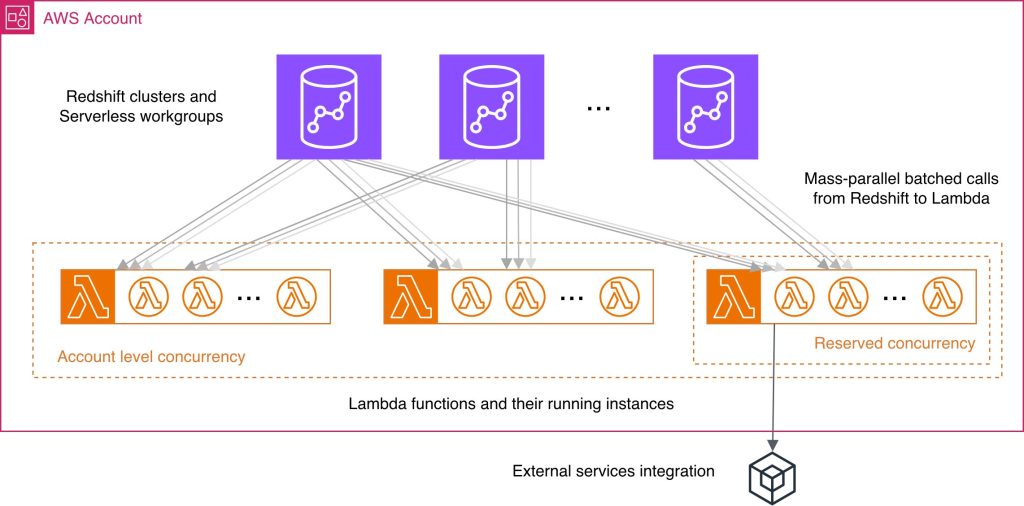
Best practices for Amazon Redshift Lambda User-Defined Functions
While working with Lambda User-Defined Functions (UDFs) in Amazon Redshift, knowing best practices may help you streamline the respective feature development and reduce common performance bottlenecks and unnecessary costs. You wonder what programming language could improve your UDF performance, how else can you use batch processing benefits, what concurrency management considerations might be applicable in your case? In this post, we answer these and other questions by providing a consolidated view of practices to improve your Lambda UDF efficiency. We explain how to choose a programming language, use existing libraries effectively, minimize payload sizes, manage return data, and batch processing. We discuss scalability and concurrency considerations at both the account and per-function levels. Finally, we examine the benefits and nuances of using external services with your Lambda UDFs.