AWS Big Data Blog
Category: Amazon Athena

Automate creating AWS Glue Data Catalog views with AWS SDK for data mesh use case
This post shows you how to use the Catalog objects API CreateTable() to programmatically create ATHENA and SPARK dialects using cross-account IAM definer roles, and how to add the ATHENA dialect programmatically for the views that were created earlier with only SPARK dialect.

Zero Copy access to Apache Iceberg tables in Amazon S3 from Salesforce Data 360 using the Iceberg REST endpoint from AWS Glue Data Catalog
In this post, we demonstrate how AWS and Salesforce customers can access their enterprise data lakes on AWS from Salesforce Data 360 using zero-copy file federation.

Multi-cloud lakehouse architecture on AWS for Agentic AI, Part 1: Architecture and best practices
This post focuses on explaining the architecture approach to build the open lakehouse architecture on AWS, unifying the metadata catalog across providers for the AI agents to access. In addition, it highlights the architecture trade-offs and best practices.
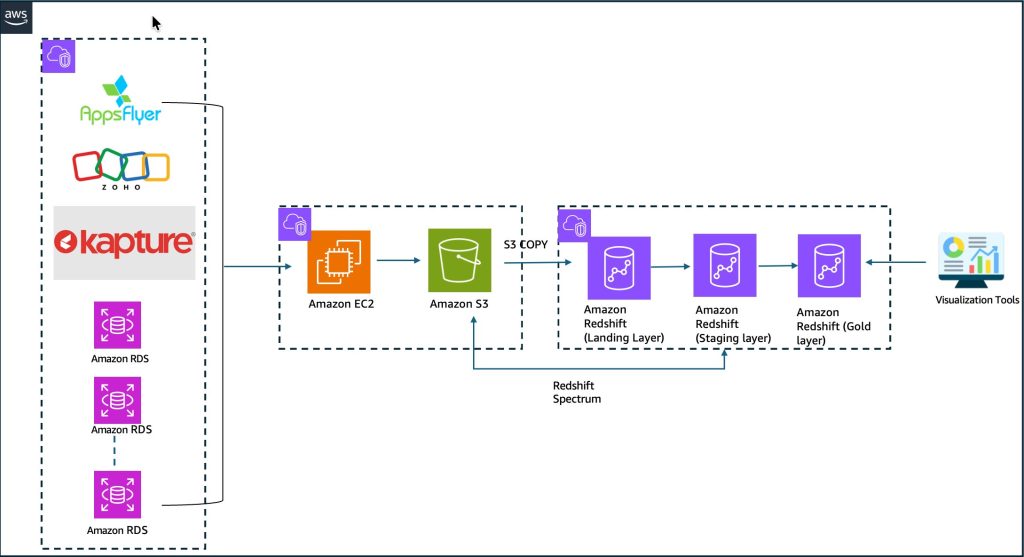
How BigBasket uses the Iceberg based lakehouse architecture on AWS to power lightning-fast grocery delivery across India
In this post, we demonstrate how BigBasket implemented the lakehouse architecture on AWS, including their architecture decisions, implementation approach, and the measurable business results you can expect from a similar modernization. Whether you’re facing scalability challenges or planning your own lakehouse implementation, this blueprint provides actionable insights you can adapt for your organization.

Serverless analytics pipelines using the Apache Spark engine in Amazon Athena
This post shows how developers, data engineers, and analysts can connect to a secure Spark Connect endpoint in Athena with Apache Spark. You can use your preferred tools, such as Jupyter notebooks, VS Code, or dbt with Apache Airflow, without managing cluster lifecycle or scaling.

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

A systematic approach to benchmarking SQL processing engines on AWS
Selecting the right SQL processing solution for large-scale data analytics is a critical decision for organizations. As data volumes grow exponentially, the technology landscape has evolved to offer diverse options for processing and analyzing this information efficiently. This post presents a systematic framework for evaluating and benchmarking SQL processing engines on AWS, using Apache JMeter to conduct practical performance testing at scale.

How to use streamlined permissions for Amazon S3 Tables and Iceberg materialized views
In this post, we walk through how to set up and manage S3 Tables in the AWS Glue Data Catalog, create and query Iceberg materialized views, and configure access controls that work across your analytics stack with IAM-based authorization.

How to use Parquet Column Indexes with Amazon Athena
In this blog post, we use Athena and Amazon SageMaker Unified Studio to explore Parquet Column Indexes and demonstrate how they can improve Iceberg query performance. We explain what Parquet Column Indexes are, demonstrate their performance benefits, and show you how to use them in your applications.

Modernize business intelligence workloads using Amazon Quick
In this post, we provide implementation guidance for building integrated analytics solutions that combine the generative BI features of Amazon Quick with Amazon Redshift and Amazon Athena SQL analytics capabilities.