AWS Big Data Blog
Category: Security, Identity, & Compliance

Securing client confidentiality at scale: Automated data discovery and governed analytics for legal workloads
In this post, we show you a reference architecture that automates sensitive data discovery across legal document repositories on Amazon Web Services (AWS), demonstrate how to capture structured findings as a compliance dataset, and guide you through building a governed analytics workspace that maintains your security boundaries. You walk away with a practical model for building security and analytics into the same lifecycle, without moving documents outside their system of record.

Securely connecting on-premises data systems to Amazon Redshift with IAM Roles Anywhere
In this post, you will learn how to use AWS IAM Roles Anywhere with Amazon Redshift for secure, private connections. This removes the need to expose traffic to the public internet or manage long-lived access keys.
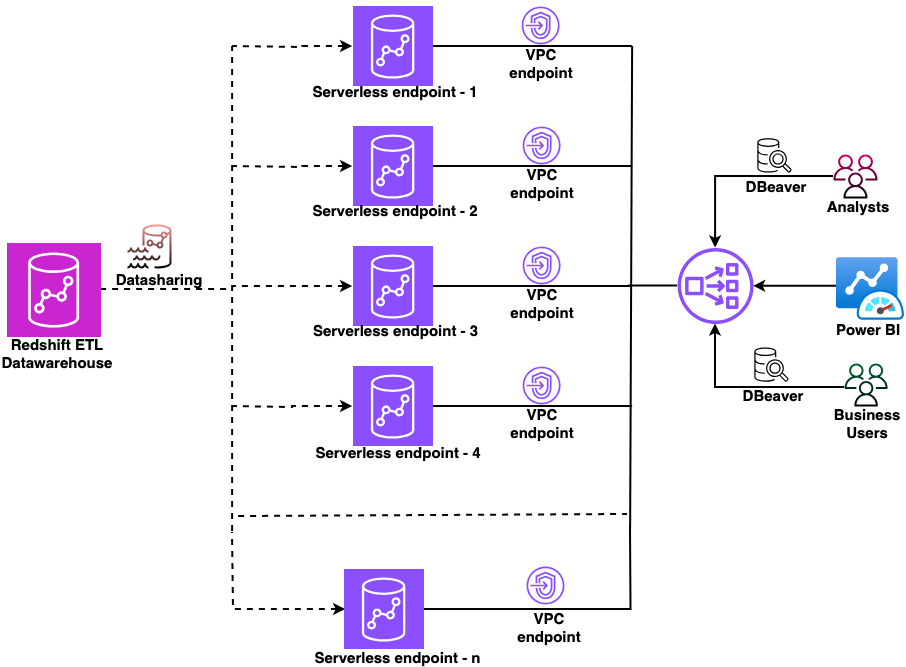
Secure multi-warehouse Amazon Redshift access behind a Network Load Balancer using Microsoft Entra ID
In this post, we show you how to configure a native identity provider (IdP) federation for Amazon Redshift Serverless using Network Load Balancer. You will learn how to enable secure connections from tools like DBeaver and Power BI while maintaining your enterprise security standards.

Scale fine-grained permissions across warehouses with Amazon Redshift and AWS IAM Identity Center
This post provides a comprehensive technical walkthrough for implementing Amazon Redshift federated permissions with AWS IAM Identity Center to help achieve scalable data governance across multiple data warehouses. It demonstrates a practical architecture where an Enterprise Data Warehouse (EDW) serves as the producer data warehouse with centralized policy definitions, helping automatically enforce security policies to consuming Sales and Marketing data warehouses without manual reconfiguration.
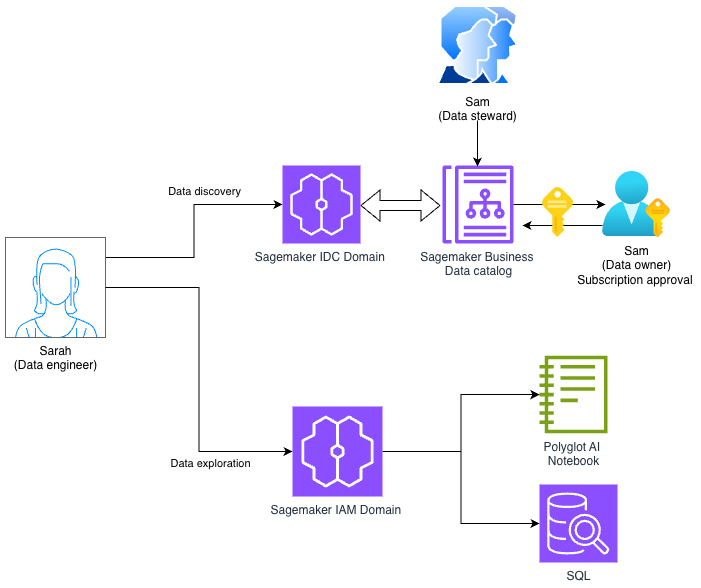
Using Amazon SageMaker Unified Studio Identity center (IDC) and IAM-based domains together
In this post, we demonstrate how to access an Amazon SageMaker Unified Studio IDC-based domain with a new IAM-based domain using role reuse and attribute-based access control.

Federate access to Amazon SageMaker Unified Studio with AWS IAM Identity Center and Ping Identity
In this post, we show how to set up workforce access with SageMaker Unified Studio using Ping Identity as an external IdP with IAM Identity Center.
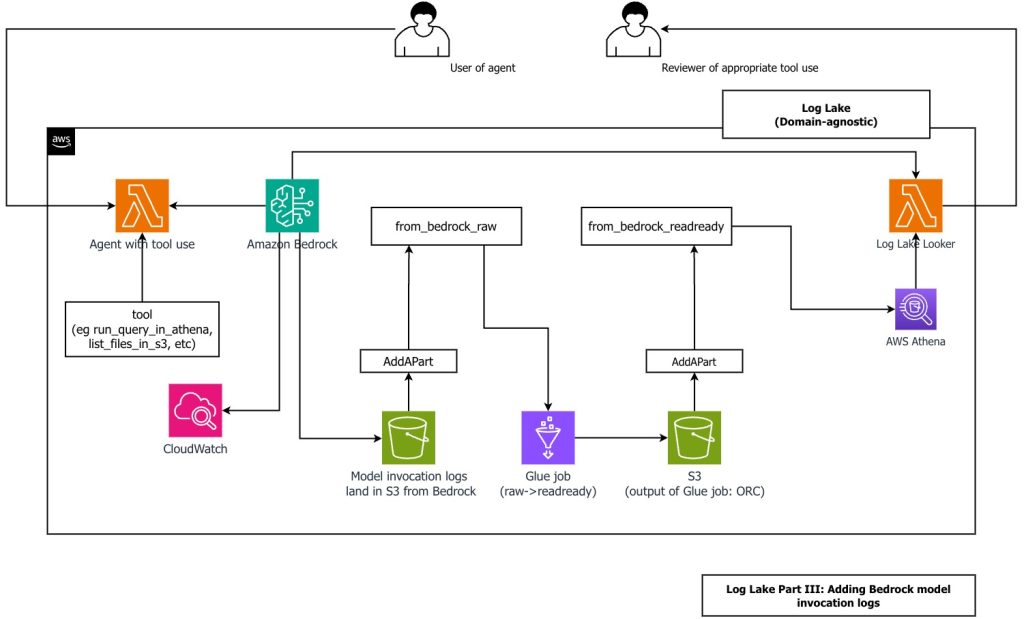
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.

Secure Apache Spark writes to Amazon S3 on Amazon EMR with dynamic AWS KMS encryption
When processing data at scale, many organizations use Apache Spark on Amazon EMR to run shared clusters that handle workloads across tenants, business units, or classification levels. In such multi-tenant environments, different datasets often require distinct AWS Key Management Service (AWS KMS) keys to enforce strict access controls and meet compliance requirements. At the same […]
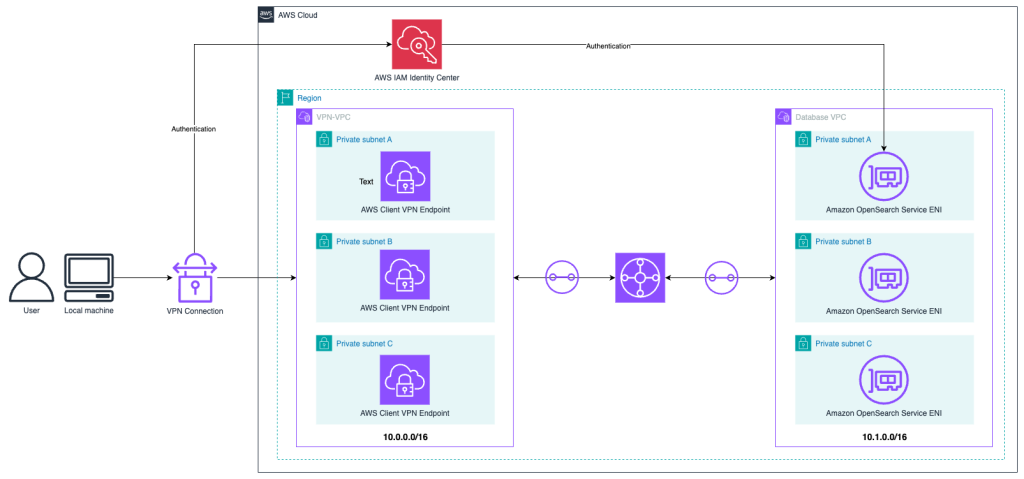
Access a VPC-hosted Amazon OpenSearch Service domain with SAML authentication using AWS Client VPN
In this post, we explore different OpenSearch Service authentication methods and network topology considerations. Then we show how to build an architecture to access an OpenSearch Service domain hosted in a VPC using AWS Client VPN, AWS Transit Gateway, and AWS IAM Identity Center.

Federate access to SageMaker Unified Studio with AWS IAM Identity Center and Okta
This post shows step-by-step guidance to setup workforce access to Amazon SageMaker Unified Studio using Okta as an external Identity provider with AWS IAM Identity Center.