AWS Big Data Blog
Category: AWS Lambda

Patch perfect: Automating Amazon Redshift patch testing
In this post, we demonstrate an automated test suite that validates your Amazon Redshift cluster automatically after any patch, reboot, or modification. It uses standard drivers against real workload patterns to provide a verified gate between a patch landing and that patch reaching production.

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

AI-powered performance recommendations for Amazon Redshift
In this post, you learn how to build an AI-powered solution that collects the telemetry, pre-computes performance signals, correlates them with CloudWatch, and uses Amazon Bedrock to generate prioritized recommendations.

Real-time CDC from Aurora PostgreSQL to Amazon S3 Tables using Debezium and Firehose
In this post, we show you how to build a CDC pipeline that delivers query-ready Iceberg tables directly. The pipeline captures inserts, updates, and deletes from Aurora PostgreSQL and applies them as row-level operations in Amazon S3 Tables, a capability of Amazon Simple Storage Service (Amazon S3).
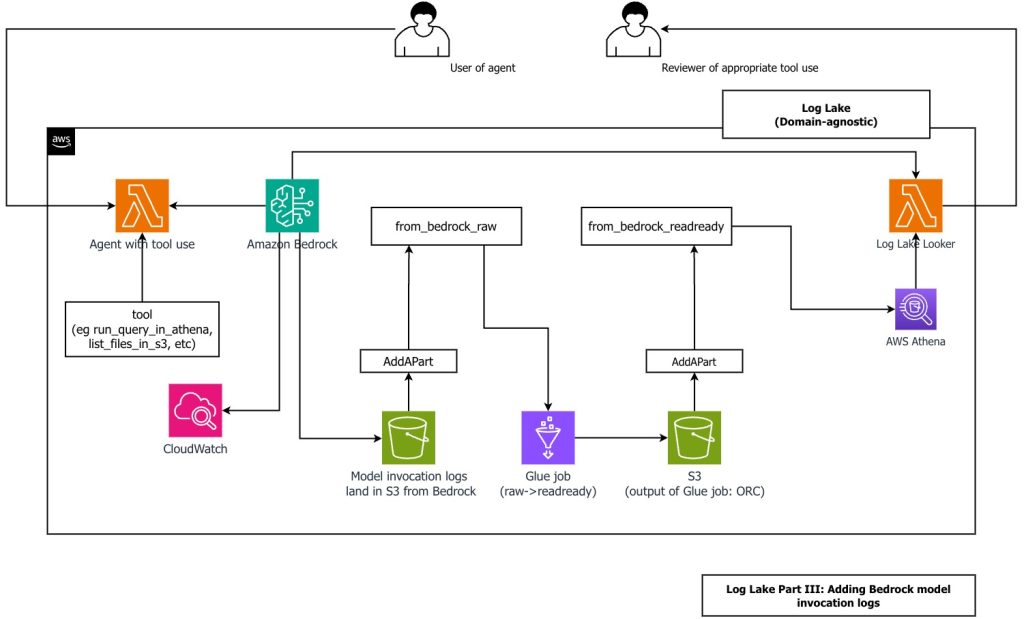
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.

Building a real-time ICU patient analytics pipeline with AWS Lambda event source mapping
In this post, we demonstrate how to build a serverless architecture that processes real-time ICU patient monitoring data using Lambda event source mapping for immediate alert generation and data aggregation, followed by persistent storage in Amazon S3 with an Iceberg catalog for comprehensive healthcare analytics.

Enhance Amazon EMR observability with automated incident mitigation using Amazon Bedrock and Amazon Managed Grafana
In this post, we demonstrate how to integrate real-time monitoring with AI-powered remediation suggestions, combining Amazon Managed Grafana for visualization, Amazon Bedrock for intelligent response recommendations, and AWS Systems Manager for automated remediation actions on Amazon Web Services (AWS).

Near real-time streaming analytics on protobuf with Amazon Redshift
In this post, we explore an end-to-end analytics workload for streaming protobuf data, by showcasing how to handle these data streams with Amazon Redshift Streaming Ingestion, deserializing and processing them using AWS Lambda functions, so that the incoming streams are immediately available for querying and analytical processing on Amazon Redshift.

Building serverless event streaming applications with Amazon MSK and AWS Lambda
In this post, we describe how you can simplify your event-driven application architecture using AWS Lambda with Amazon MSK. We demonstrate how to configure Lambda as a consumer for Kafka topics, including a cross-account setup and how to optimize price and performance for these applications.

PackScan: Building real-time sort center analytics with AWS Services
In this post, we explore how PackScan uses Amazon cloud-based services to drive real-time visibility, improve logistics efficiency, and support the seamless movement of packages across Amazon’s Middle Mile network.