AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)

Automate creating AWS Glue Data Catalog views with AWS SDK for data mesh use case
This post shows you how to use the Catalog objects API CreateTable() to programmatically create ATHENA and SPARK dialects using cross-account IAM definer roles, and how to add the ATHENA dialect programmatically for the views that were created earlier with only SPARK dialect.

Zero Copy access to Apache Iceberg tables in Amazon S3 from Salesforce Data 360 using the Iceberg REST endpoint from AWS Glue Data Catalog
In this post, we demonstrate how AWS and Salesforce customers can access their enterprise data lakes on AWS from Salesforce Data 360 using zero-copy file federation.

Patch perfect: Automating Amazon Redshift patch testing
In this post, we demonstrate an automated test suite that validates your Amazon Redshift cluster automatically after any patch, reboot, or modification. It uses standard drivers against real workload patterns to provide a verified gate between a patch landing and that patch reaching production.

Cut costs and simplify operations with writable warm storage in Amazon OpenSearch Service
In this post, I show you how writable warm storage removes the costly migration cycle. You can reduce your infrastructure costs by up to 48 percent and update historical data in seconds instead of hours. I walk through a real-world cost comparison and performance benchmarks, and help you decide when to use writable warm versus UltraWarm.
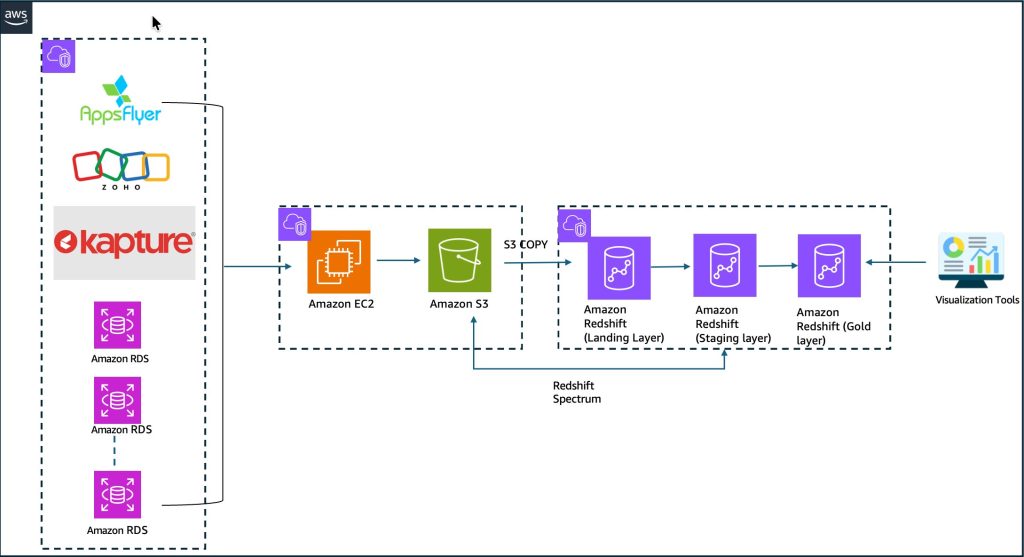
How BigBasket uses the Iceberg based lakehouse architecture on AWS to power lightning-fast grocery delivery across India
In this post, we demonstrate how BigBasket implemented the lakehouse architecture on AWS, including their architecture decisions, implementation approach, and the measurable business results you can expect from a similar modernization. Whether you’re facing scalability challenges or planning your own lakehouse implementation, this blueprint provides actionable insights you can adapt for your organization.

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

Why tombola chose Graviton-powered RG instances for Amazon Redshift
In this post, you learn how tombola followed a strict engineering principle: no changes to production without evidence. That meant a head-to-head comparison of RA3 versus RG on their actual workload. You also see benchmark results on Amazon S3 Tables and the migration from RA3 to RG instances.

Access Amazon S3 data files directly using AWS Lake Formation permissions
In this post, we demonstrate reading from and writing to Lake Formation-managed S3 locations using Apache Spark jobs from EMR. Lake Formation credential vending for S3 location access is available in EMR release label 7.13 and later, Boto3 1.42.29 and later, AWS Java SDK 2.41.32 and later, and AWS Command Line Interface (AWS CLI) version 2.33.1 and later.

Securing client confidentiality at scale: Automated data discovery and governed analytics for legal workloads
In this post, we show you a reference architecture that automates sensitive data discovery across legal document repositories on Amazon Web Services (AWS), demonstrate how to capture structured findings as a compliance dataset, and guide you through building a governed analytics workspace that maintains your security boundaries. You walk away with a practical model for building security and analytics into the same lifecycle, without moving documents outside their system of record.

How to use streamlined permissions for Amazon S3 Tables and Iceberg materialized views
In this post, we walk through how to set up and manage S3 Tables in the AWS Glue Data Catalog, create and query Iceberg materialized views, and configure access controls that work across your analytics stack with IAM-based authorization.