AWS Big Data Blog
Category: Amazon Bedrock

Multi-cloud lakehouse architecture on AWS for Agentic AI, Part 1: Architecture and best practices
This post focuses on explaining the architecture approach to build the open lakehouse architecture on AWS, unifying the metadata catalog across providers for the AI agents to access. In addition, it highlights the architecture trade-offs and best practices.

Deploy modern data platforms in minutes with MDAA
In this post, we explore how MDAA transforms data architecture development from months of manual coding to production-ready deployment through configuration-driven infrastructure and embedded governance, examine a real customer transformation, and provide a clear implementation pathway for your own data modernization journey.

AI-powered performance recommendations for Amazon Redshift
In this post, you learn how to build an AI-powered solution that collects the telemetry, pre-computes performance signals, correlates them with CloudWatch, and uses Amazon Bedrock to generate prioritized recommendations.

Automating IT support with AI: How Nexthink uses OpenSearch Service to power self-service issue resolution
In this post, we explore how Nexthink combined Amazon OpenSearch Service vector search, Amazon Bedrock, and infrastructure as code to power the Spark agent’s retrieval layer.

Building AI shopping agent using Amazon Bedrock AgentCore Runtime and Amazon OpenSearch Service
In this post, we explore how to build an online shopping AI agent. We focus on its architecture and implementation with Amazon OpenSearch Service, Amazon Bedrock AgentCore, and Strands Agents. Amazon Bedrock AgentCore is an agentic platform for deploying and operating those agents and tools securely at scale without managing infrastructure.

Agentic AI for observability and troubleshooting with Amazon OpenSearch Service
Now, Amazon OpenSearch Service brings three new agentic AI features to OpenSearch UI. In this post, we show how these capabilities work together to help engineers go from alert to root cause in minutes. We also walk through a sample scenario where the Investigation Agent automatically correlates data across multiple indices to surface a root cause hypothesis.
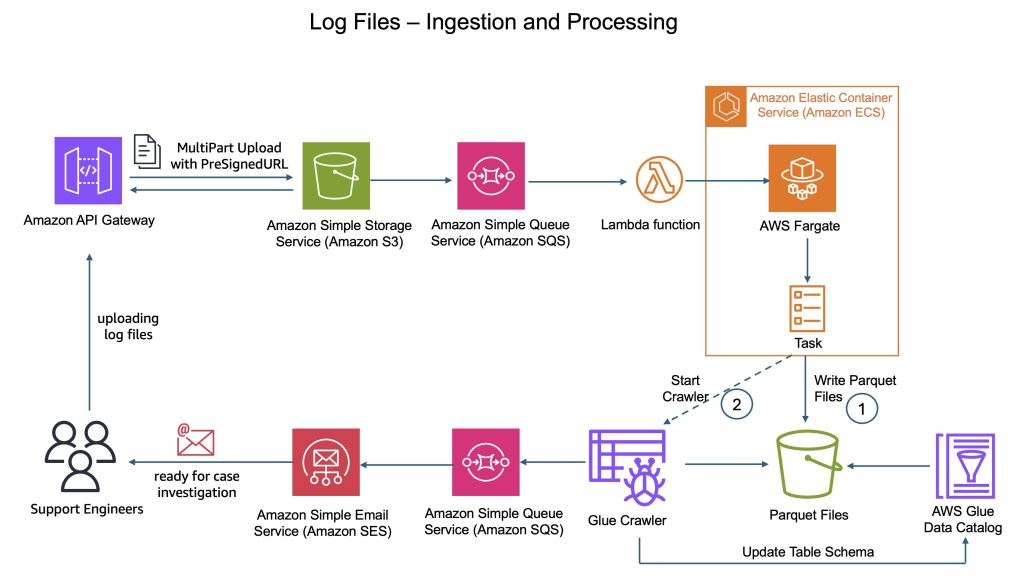
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.
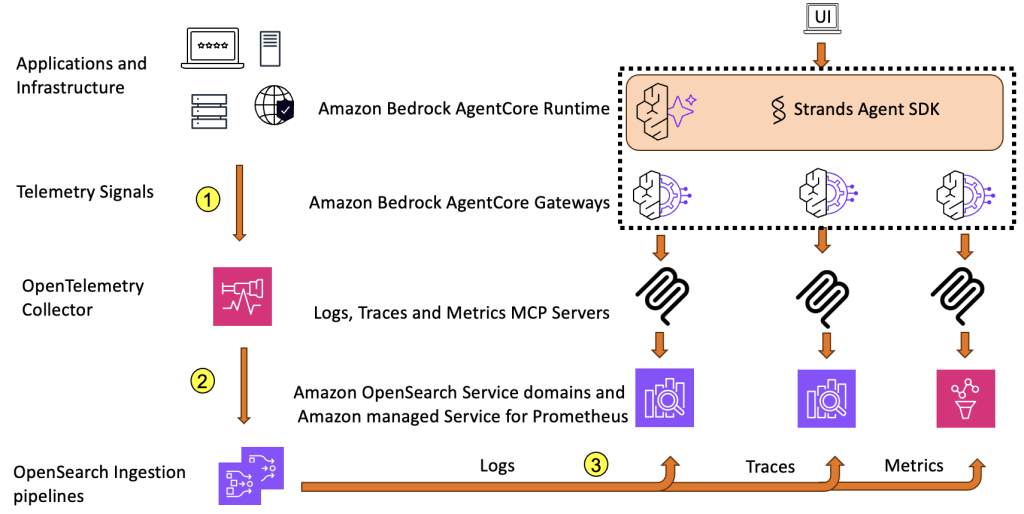
Reduce Mean Time to Resolution with an observability agent
In this post, we present an observability agent using OpenSearch Service and Amazon Bedrock AgentCore that can help surface root cause and get insights faster, handle multiple query-correlation cycles, and ultimately reduce MTTR even further.

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.
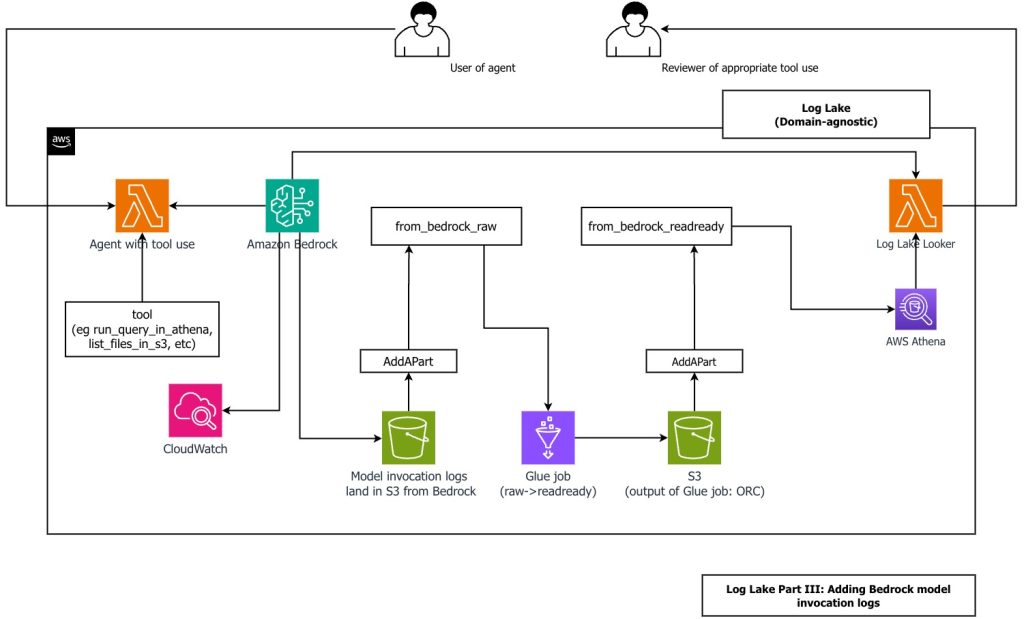
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.