AWS Big Data Blog
Category: Generative AI

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.

Manage access controls in generative AI-powered search applications using Amazon OpenSearch Service and Amazon Cognito
In this post, we show you how to manage user access to enterprise documents in generative AI-powered tools according to the access you assign to each persona. This post illustrates how to build a document search RAG solution that makes sure only authorized users can access and interact with specific documents based on their roles, departments, and other relevant attributes. It combines OpenSearch Service and Amazon Cognito custom attributes to make a tag-based access control mechanism that makes it straightforward to manage at scale.

Enriching metadata for accurate text-to-SQL generation for Amazon Athena
In this post, we demonstrate the critical role of metadata in text-to-SQL generation through an example implemented for Amazon Athena using Amazon Bedrock. We discuss the challenges in maintaining the metadata as well as ways to overcome those challenges and enrich the metadata.

Differentiate generative AI applications with your data using AWS analytics and managed databases
While the potential of generative artificial intelligence (AI) is increasingly under evaluation, organizations are at different stages in defining their generative AI vision. In many organizations, the focus is on large language models (LLMs), and foundation models (FMs) more broadly. This is just the tip of the iceberg, because what enables you to obtain differential […]

Protein similarity search using ProtT5-XL-UniRef50 and Amazon OpenSearch Service
A protein is a sequence of amino acids that, when chained together, creates a 3D structure. This 3D structure allows the protein to bind to other structures within the body and initiate changes. This binding is core to the working of many drugs. A common workflow within drug discovery is searching for similar proteins, because […]

Data governance in the age of generative AI
Data is your generative AI differentiator, and a successful generative AI implementation depends on a robust data strategy incorporating a comprehensive data governance approach. Working with large language models (LLMs) for enterprise use cases requires the implementation of quality and privacy considerations to drive responsible AI. However, enterprise data generated from siloed sources combined with […]

Build scalable and serverless RAG workflows with a vector engine for Amazon OpenSearch Serverless and Amazon Bedrock Claude models
In pursuit of a more efficient and customer-centric support system, organizations are deploying cutting-edge generative AI applications. These applications are designed to excel in four critical areas: multi-lingual support, sentiment analysis, personally identifiable information (PII) detection, and conversational search capabilities. Customers worldwide can now engage with the applications in their preferred language, and the applications […]
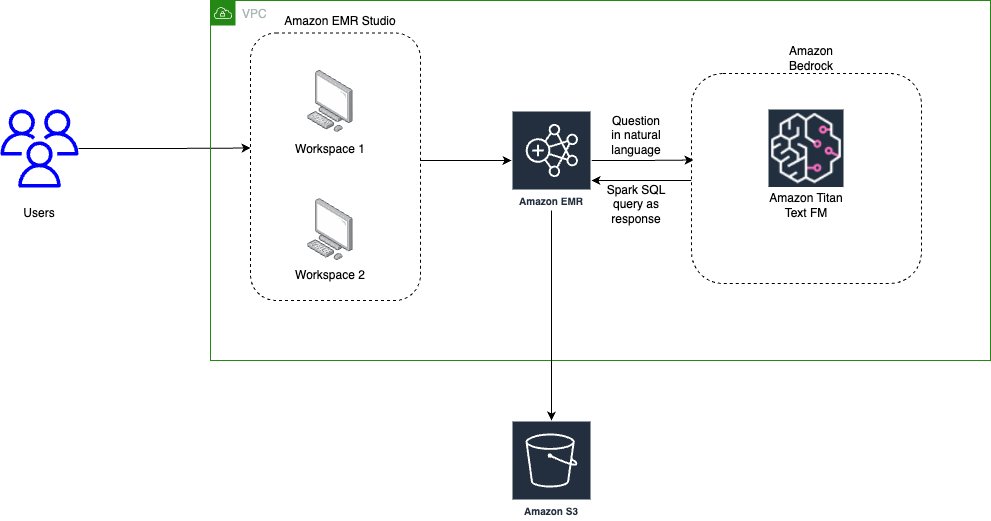
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]