AWS Big Data Blog
Category: Amazon DynamoDB

Improve DynamoDB analytics with AWS Glue zero-ETL schema and partition controls
In this post, you learn how to replicate Amazon DynamoDB data to Apache Iceberg tables in Amazon S3 through a zero-ETL integration. We walk through the challenges that the DynamoDB nested, schema-flexible data model introduces for analytics workloads, and show you how to configure schema unnesting and data partitioning for a sample product catalog table. We also cover how to query the replicated data in Amazon Athena using standard SQL.

Get started with Amazon DynamoDB zero-ETL integration with Amazon Redshift
We’re excited to announce the general availability (GA) of Amazon DynamoDB zero-ETL integration with Amazon Redshift, which enables you to run high-performance analytics on your DynamoDB data in Amazon Redshift with little to no impact on production workloads running on DynamoDB. As data is written into a DynamoDB table, it’s seamlessly made available in Amazon Redshift, eliminating the need to build and maintain complex data pipelines.

Differentiate generative AI applications with your data using AWS analytics and managed databases
While the potential of generative artificial intelligence (AI) is increasingly under evaluation, organizations are at different stages in defining their generative AI vision. In many organizations, the focus is on large language models (LLMs), and foundation models (FMs) more broadly. This is just the tip of the iceberg, because what enables you to obtain differential […]
Reference guide to analyze transactional data in near-real time on AWS
Business leaders and data analysts use near-real-time transaction data to understand buyer behavior to help evolve products. The primary challenge businesses face with near-real-time analytics is getting the data prepared for analytics in a timely manner, which can often take days. Companies commonly maintain entire teams to facilitate the flow of data from ingestion to […]

Visualize Amazon DynamoDB insights in Amazon QuickSight using the Amazon Athena DynamoDB connector and AWS Glue
May 2025: This post was reviewed for accuracy. Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data import and export tools. The scalability and flexible data schema of DynamoDB make it well-suited for […]

Automate legacy ETL conversion to AWS Glue using Cognizant Data and Intelligence Toolkit (CDIT) – ETL Conversion Tool
In this post, we describe how Cognizant’s Data & Intelligence Toolkit (CDIT)- ETL Conversion Tool can help you automatically convert legacy ETL code to AWS Glue quickly and effectively. We also describe the main steps involved, the supported features, and their benefits.

Near-real-time analytics using Amazon Redshift streaming ingestion with Amazon Kinesis Data Streams and Amazon DynamoDB
Amazon Redshift is a fully managed, scalable cloud data warehouse that accelerates your time to insights with fast, easy, and secure analytics at scale. Tens of thousands of customers rely on Amazon Redshift to analyze exabytes of data and run complex analytical queries, making it the widely used cloud data warehouse. You can run and […]

Build an Amazon Redshift data warehouse using an Amazon DynamoDB single-table design
DynamoDB zero-ETL integration with Amazon Redshift is now generally available and provides fully-managed replication of DynamoDB tables into an Amazon Redshift database. Learn more at DynamoDB zero-ETL integration with Amazon Redshift. Amazon DynamoDB is a fully managed NoSQL service that delivers single-digit millisecond performance at any scale. It’s used by thousands of customers for mission-critical […]

Join a streaming data source with CDC data for real-time serverless data analytics using AWS Glue, AWS DMS, and Amazon DynamoDB
Customers have been using data warehousing solutions to perform their traditional analytics tasks. Recently, data lakes have gained lot of traction to become the foundation for analytical solutions, because they come with benefits such as scalability, fault tolerance, and support for structured, semi-structured, and unstructured datasets. Data lakes are not transactional by default; however, there […]
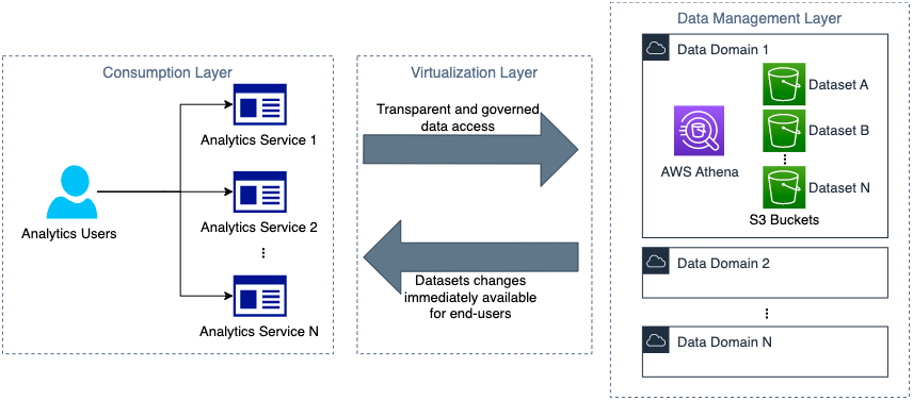
How Novo Nordisk built distributed data governance and control at scale
This is a guest post co-written with Jonatan Selsing and Moses Arthur from Novo Nordisk. This is the second post of a three-part series detailing how Novo Nordisk, a large pharmaceutical enterprise, partnered with AWS Professional Services to build a scalable and secure data and analytics platform. The first post of this series describes the […]