AWS Big Data Blog
Category: Amazon DynamoDB

Accelerate HiveQL with Oozie to Spark SQL migration on Amazon EMR
Many customers run big data workloads such as extract, transform, and load (ETL) on Apache Hive to create a data warehouse on Hadoop. Apache Hive has performed pretty well for a long time. But with advancements in infrastructure such as cloud computing and multicore machines with large RAM, Apache Spark started to gain visibility by […]

Query cross-account Amazon DynamoDB tables using Amazon Athena Federated Query
Amazon DynamoDB is ideal for applications that need a flexible NoSQL database with low read and write latencies and the ability to scale storage and throughput up or down as needed without code changes or downtime. You can use DynamoDB for use cases including mobile apps, gaming, digital ad serving, live voting, audience interaction for live […]

How SOCAR built a streaming data pipeline to process IoT data for real-time analytics and control
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. SOCAR is the leading Korean mobility company with strong competitiveness in car-sharing. SOCAR has become a comprehensive mobility platform in collaboration with Nine2One, an e-bike sharing service, […]

How a blockchain startup built a prototype solution to solve the need of analytics for decentralized applications with AWS Data Lab
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post is co-written with Dr. Quan Hoang Nguyen, CTO at Fantom Foundation. Here at Fantom Foundation (Fantom), we have developed a high performance, highly scalable, and secure smart contract platform. It’s […]
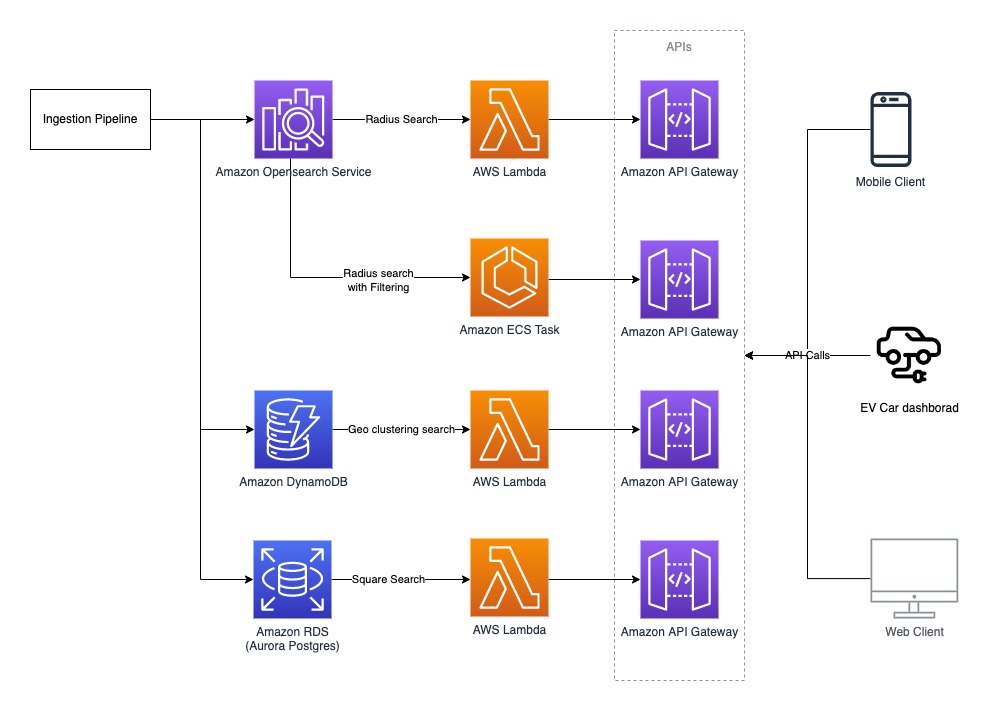
How Plugsurfing doubled performance and reduced cost by 70% with purpose-built databases and AWS Graviton
Plugsurfing aligns the entire car charging ecosystem—drivers, charging point operators, and carmakers—within a single platform. The over 1 million drivers connected to the Plugsurfing Power Platform benefit from a network of over 300,000 charging points across Europe. Plugsurfing serves charging point operators with a backend cloud software for managing everything from country-specific regulations to providing […]

Accelerate Amazon DynamoDB data access in AWS Glue jobs using the new AWS Glue DynamoDB Export connector
Jan 2024: This post was reviewed and updated for accuracy. Modern data architectures encourage the integration of data lakes, data warehouses, and purpose-built data stores, enabling unified governance and easy data movement. With a modern data architecture on AWS, you can store data in a data lake and use a ring of purpose-built data services […]

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]

Doing more with less: Moving from transactional to stateful batch processing
Amazon processes hundreds of millions of financial transactions each day, including accounts receivable, accounts payable, royalties, amortizations, and remittances, from over a hundred different business entities. All of this data is sent to the eCommerce Financial Integration (eCFI) systems, where they are recorded in the subledger. Ensuring complete financial reconciliation at this scale is critical […]

How ENGIE scales their data ingestion pipelines using Amazon MWAA
ENGIE—one of the largest utility providers in France and a global player in the zero-carbon energy transition—produces, transports, and deals electricity, gas, and energy services. With 160,000 employees worldwide, ENGIE is a decentralized organization and operates 25 business units with a high level of delegation and empowerment. ENGIE’s decentralized global customer base had accumulated lots […]
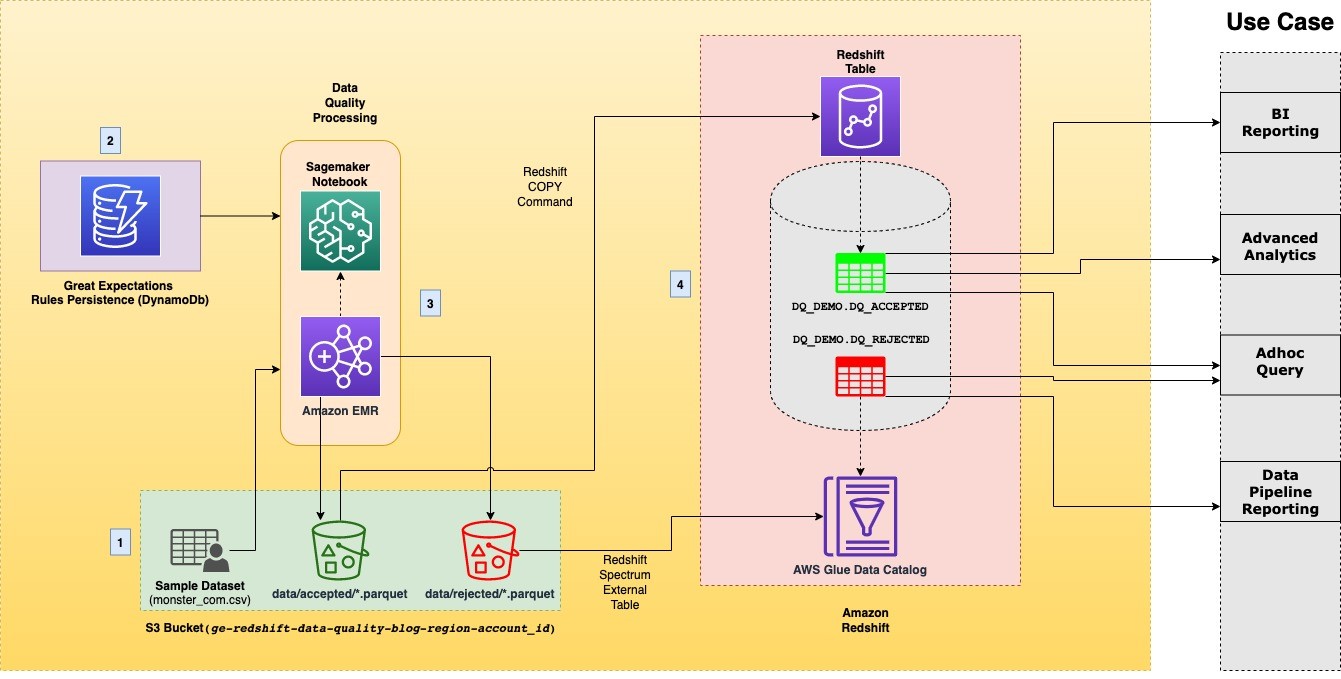
Provide data reliability in Amazon Redshift at scale using Great Expectations library
Ensuring data reliability is one of the key objectives of maintaining data integrity and is crucial for building data trust across an organization. Data reliability means that the data is complete and accurate. It’s the catalyst for delivering trusted data analytics and insights. Incomplete or inaccurate data leads business leaders and data analysts to make […]