AWS Big Data Blog
Category: Amazon DynamoDB
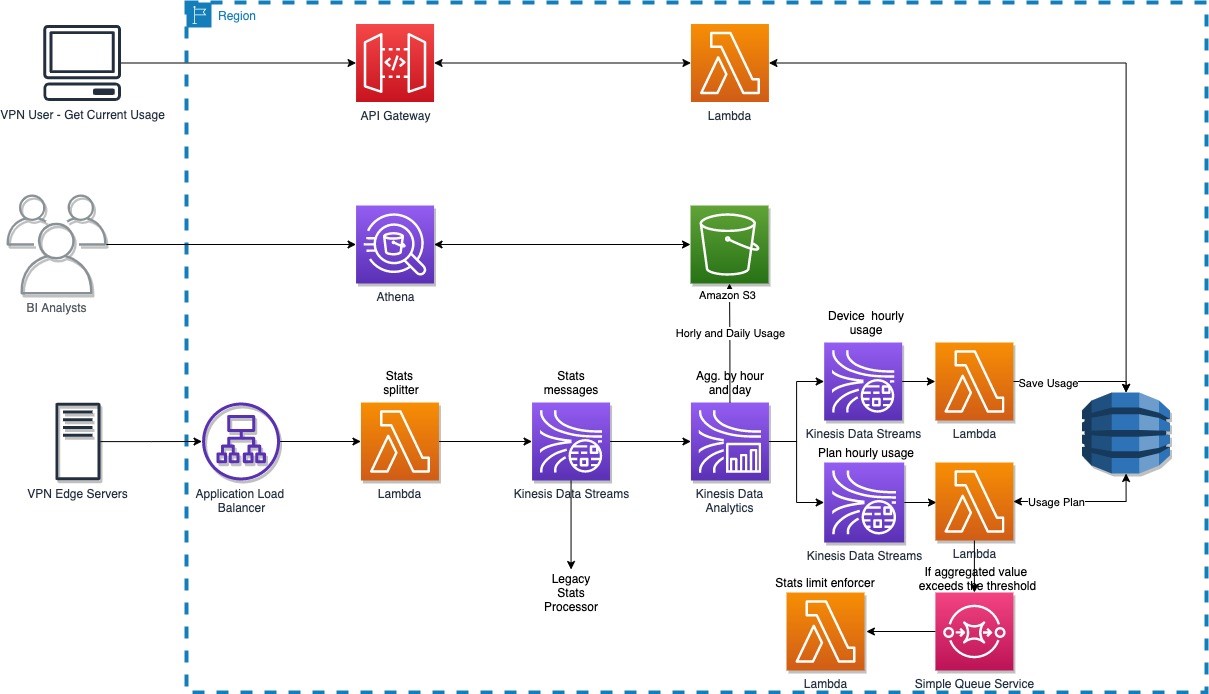
How NortonLifelock built a serverless architecture for real-time analysis of their VPN usage metrics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post presents a reference architecture and optimization strategies for building serverless data analytics solutions on AWS using Amazon Kinesis Data Analytics. In addition, this post shows […]
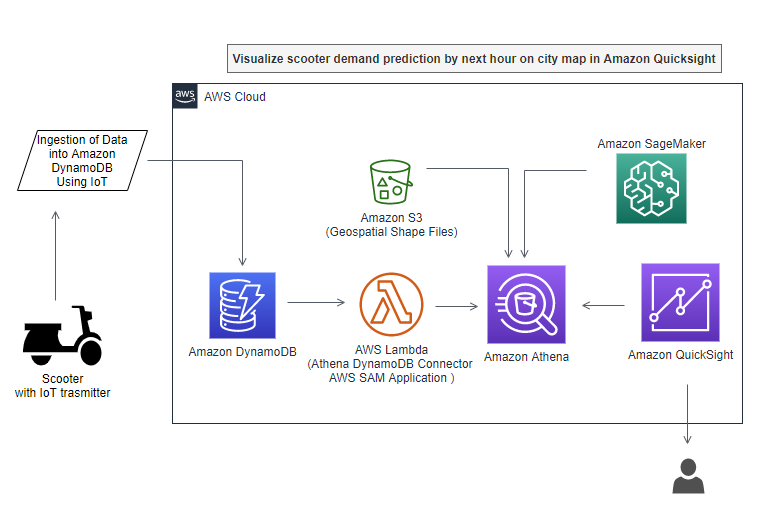
Use ML predictions over Amazon DynamoDB data with Amazon Athena ML
Today’s modern applications use multiple purpose-built database engines, including relational, key-value, document, and in-memory databases. This purpose-built approach improves the way applications use data by providing better performance and reducing cost. However, the approach raises some challenges for data teams that need to provide a holistic view on top of these database engines, and especially […]

Create a secure data lake by masking, encrypting data, and enabling fine-grained access with AWS Lake Formation
You can build data lakes with millions of objects on Amazon Simple Storage Service (Amazon S3) and use AWS native analytics and machine learning (ML) services to process, analyze, and extract business insights. You can use a combination of our purpose-built databases and analytics services like Amazon EMR, Amazon OpenSearch Service, and Amazon Redshift as […]

Streaming Amazon DynamoDB data into a centralized data lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. For organizations moving towards […]

Build seamless data streaming pipelines with Amazon Kinesis Data Streams and Amazon Data Firehose for Amazon DynamoDB tables
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. The global wearables market […]

Build a data lake using Amazon Kinesis Data Streams for Amazon DynamoDB and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. July 2023: This post was reviewed for accuracy. Amazon DynamoDB helps you capture high-velocity data such as clickstream data to form customized user profiles and online order […]
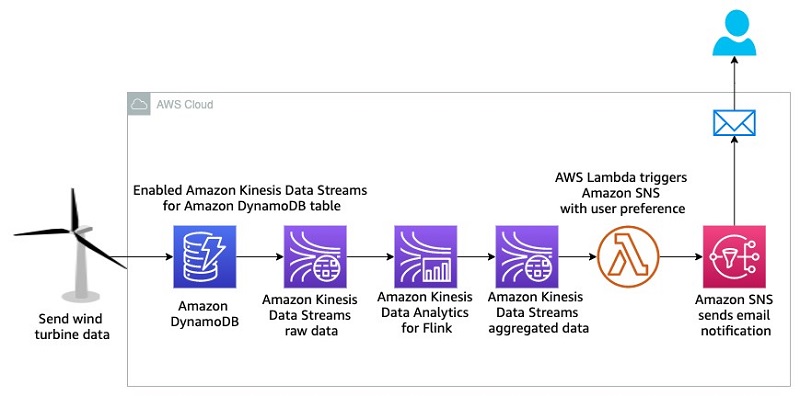
Building a real-time notification system with Amazon Kinesis Data Streams for Amazon DynamoDB and Amazon Kinesis Data Analytics for Apache Flink
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Amazon DynamoDB helps you capture high-velocity data such as clickstream data to form customized user profiles and Internet of Things (IoT) data so that you can develop […]

Detect change points in your event data stream using Amazon Kinesis Data Streams, Amazon DynamoDB and AWS Lambda
The success of many modern streaming applications depends on the ability to sequentially detect each change as soon as possible after it occurs, while continuing to monitor the data stream as it evolves. Applications of change point detection range across genomics, marketing, and finance, to name a few. In genomics, change point detection can help […]
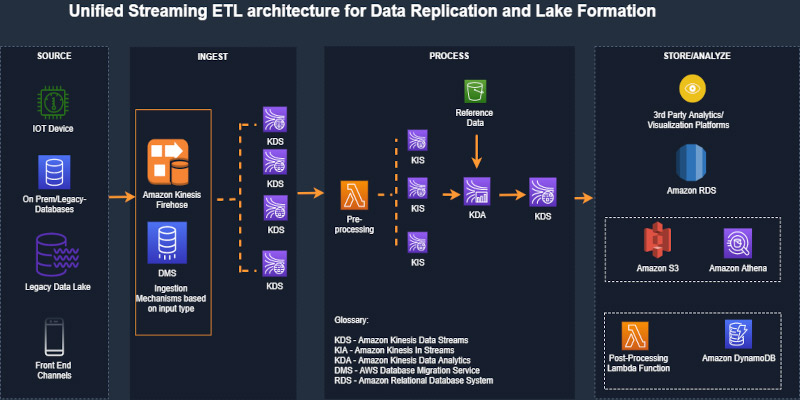
Unified serverless streaming ETL architecture with Amazon Kinesis Data Analytics
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Businesses across the world […]
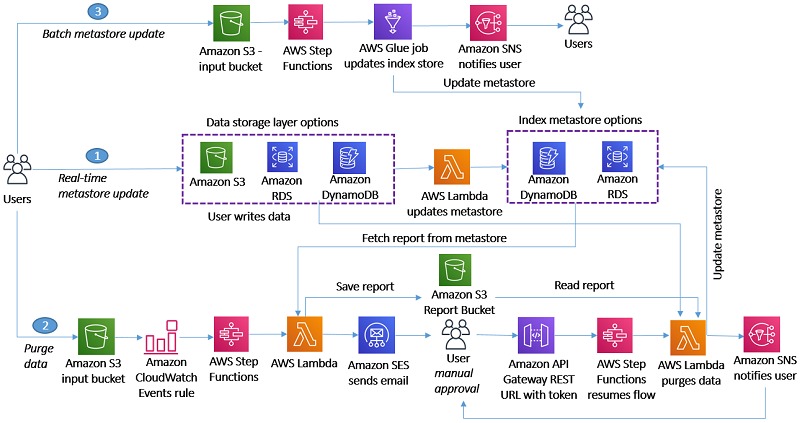
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]