AWS Big Data Blog
Category: Industries

How Zynga scaled multi-warehouse data governance with Amazon Redshift federated permissions
In this post, we walk through how Zynga adopted Amazon Redshift federated permissions and AWS IAM Identity Center to enforce consistent, tiered data access across provisioned and serverless Amazon Redshift environments without building custom synchronization pipelines.

How to build a cross-Region resilience for Amazon OpenSearch Service with Amazon MSK
In this post, we outline the solution that provides cross-Region resiliency without needing to reestablish relationships during a fail-back, using an active-active replication model with Amazon OpenSearch Ingestion (OSI) and Amazon Managed Streaming for Apache Kafka (Amazon MSK). This solution applies to both OpenSearch Service managed clusters and Amazon OpenSearch Serverless collections. We use Amazon OpenSearch Serverless as an example for the configurations in this post.

Building unified data pipelines with Apache Iceberg and Apache Flink
In this post, you build a unified pipeline using Apache Iceberg and Amazon Managed Service for Apache Flink that replaces the dual-pipeline approach. This walkthrough is for intermediate AWS users who are comfortable with Amazon Simple Storage Service (Amazon S3) and AWS Glue Data Catalog but new to streaming from Apache Iceberg tables.

How Razorpay achieved 11% performance improvement and 21% cost reduction with Amazon EMR
In this post, we explore how Razorpay, India’s leading FinTech company, transformed their data platform by migrating from a third-party solution to Amazon EMR, unlocking improved performance and significant cost savings. We’ll walk through the architectural decisions that guided this migration, the implementation strategy, and the measurable benefits Razorpay achieved.
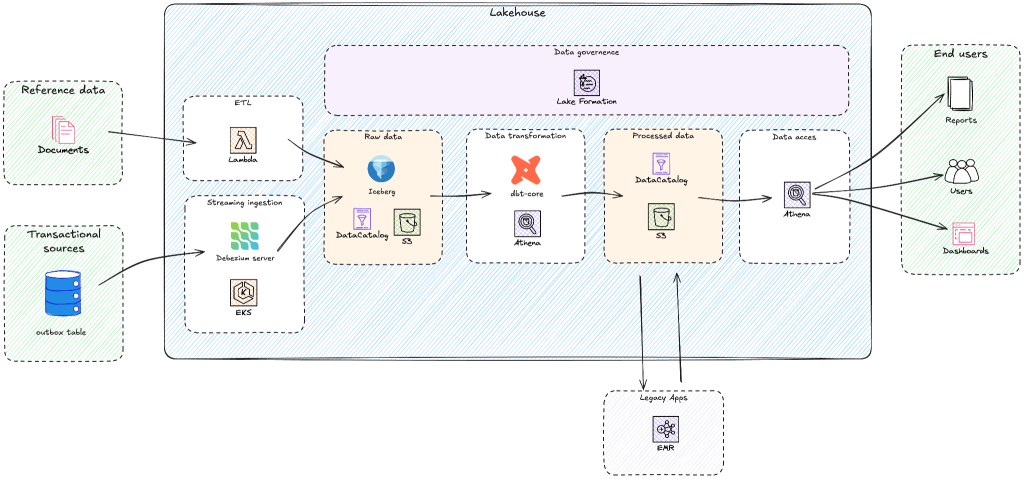
Building a modern lakehouse architecture: Yggdrasil Gaming’s journey from BigQuery to AWS
Yggdrasil Gaming develops and publishes casino games globally, processing massive amounts of real-time gaming data for game performance analytics, player behavior insights, and industry intelligence. Yggdrasil Gaming reduced multi-cloud complexity and built a scalable analytics foundation by migrating from Google BigQuery to AWS analytics services. In this post, you’ll discover how Yggdrasil Gaming transformed their data architecture to meet growing business demands. You will learn practical strategies for migrating from proprietary systems to open table formats such as Apache Iceberg while maintaining business continuity. Yggdrasil worked with GOStack, an AWS Partner, to migrate to an Apache Iceberg-based lakehouse architecture. The migration helped reduce operational complexity and enabled real-time gaming analytics and machine learning.
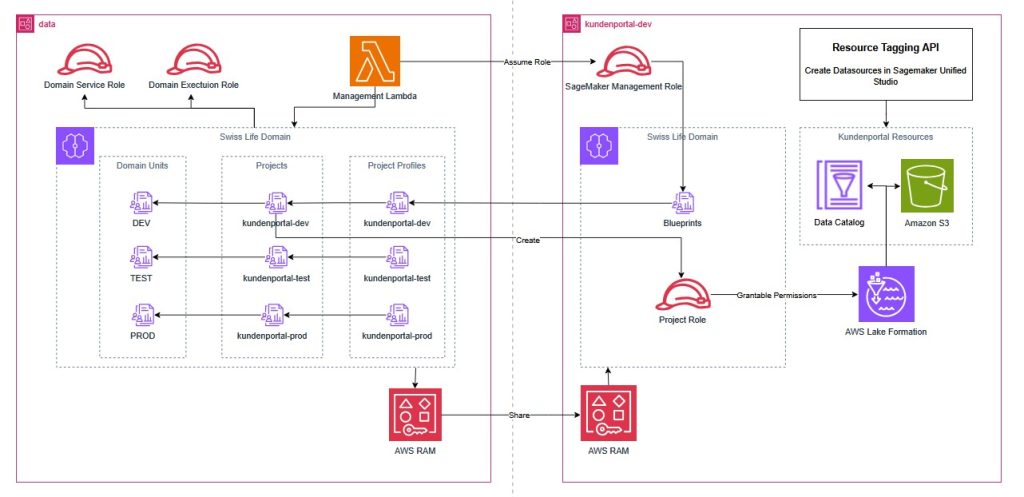
How Swiss Life Germany automated data governance and collaboration with Amazon SageMaker
Swiss Life Germany, a leading provider of customized pension products with over 100 years of experience, recently transitioned from legacy on-premises infrastructure to a modern cloud architecture. To enable secure data sharing and cross-departmental collaboration in this regulated environment, they implemented Amazon SageMaker with a custom Terraform pattern. This post demonstrates how Swiss Life Germany aligned SageMaker’s agility with their rigorous infrastructure as code standards, providing a blueprint for platform engineers and data architects in highly regulated enterprises.

Verisk cuts processing time and storage costs with Amazon Redshift and lakehouse
Verisk, a catastrophe modeling SaaS provider serving insurance and reinsurance companies worldwide, cut processing time from hours to minutes-level aggregations while reducing storage costs by implementing a lakehouse architecture with Amazon Redshift and Apache Iceberg. If you’re managing billions of catastrophe modeling records across hurricanes, earthquakes, and wildfires, this approach eliminates the traditional compute-versus-cost trade-off by separating storage from processing power. In this post, we examine Verisk’s lakehouse implementation, focusing on four architectural decisions that delivered measurable improvements.

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.

Breaking down data silos: Volkswagen’s approach with Amazon DataZone
In this post, we introduce Amazon DataZone and explore how Volkswagen used Amazon DataZone to build their data mesh, tackle the challenges encountered, and break the data silos.

Announcing SageMaker Unified Studio Workshops for Financial Services
In this post, we’re excited to announce the release of four Amazon SageMaker Unified Studio publicly available workshops that are specific to each FSI segment: insurance, banking, capital markets, and payments. These workshops can help you learn how to deploy Amazon SageMaker Unified Studio effectively for business use cases.