AWS Big Data Blog
How to build a cross-Region resilience for Amazon OpenSearch Service with Amazon MSK
Cross-Region resilience for Amazon OpenSearch Service has historically been a complex challenge, relying on S3-based snapshots or cross-cluster replication that demand intricate manual failover procedures often resulting in hours of downtime, data inconsistencies, and significant lag during outages, or other operational disruptions. To overcome these limitations and help businesses stay focused on their core objectives, we’ve developed a solution that automatically maintains synchronized data across AWS Regions while supporting active-active operations in both AWS Regions.
AWS offers two OpenSearch offerings, namely Amazon OpenSearch Service, a managed cluster-based service where you provision and manage OpenSearch domains (nodes, storage, scaling), and Amazon OpenSearch Serverless, a serverless option where AWS automatically manages infrastructure and scaling and you create collections for your search or analytics workloads. OpenSearch Service provides high availability (HA) within an AWS Region through its Multi-AZ deployment model and provides Regional resiliency with cross-cluster replication. Amazon Managed Streaming for Apache Kafka (Amazon MSK) Replicator is an Amazon MSK feature that you can use to reliably replicate data across Amazon MSK clusters in different or the same AWS Region.
In this post, we outline the solution that provides cross-Region resiliency without needing to reestablish relationships during a fail-back, using an active-active replication model with Amazon OpenSearch Ingestion (OSI) and Amazon Managed Streaming for Apache Kafka (Amazon MSK). This solution applies to both OpenSearch Service managed clusters and Amazon OpenSearch Serverless collections. We use Amazon OpenSearch Serverless as an example for the configurations in this post.
Solution overview
In this solution we use Amazon MSK Replicator for bidirectional cross-Region data replication, with OSI pipelines to index data into Amazon OpenSearch Serverless collections in each AWS Region. While the S3 based approach serves the purpose, Amazon MSK Replicator provides near real-time replication with identical topic naming, which supports active-active operations. Amazon MSK Replicator provides automatic loop prevention and consumer group offset synchronization, enabling seamless cross-Region failover. You can find the code for the entire solution in the GitHub repo.
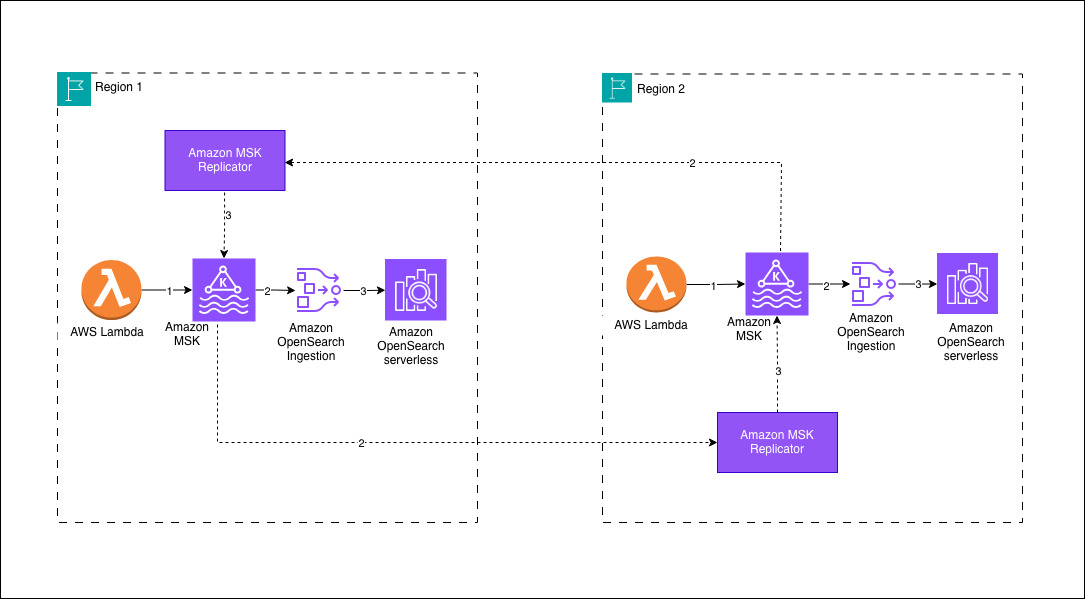 Your architecture will follow a Regional-first approach where data sources write to a local Amazon MSK cluster within their AWS Region. In this sample deployment, an AWS Lambda function serves as the producer, streaming data into the MSK cluster. OSI pipelines consume the incoming data from the local MSK cluster and persist it to an Amazon OpenSearch Serverless collection within the same AWS Region. To achieve cross-Region data synchronization, Amazon MSK Replicator facilitates bidirectional replication between the Amazon MSK clusters, preserving the same topic names across both environments. This design validates that Amazon OpenSearch Serverless collections in each AWS Region maintain identical datasets, provides low-latency search capabilities and high availability for globally distributed workloads.
Your architecture will follow a Regional-first approach where data sources write to a local Amazon MSK cluster within their AWS Region. In this sample deployment, an AWS Lambda function serves as the producer, streaming data into the MSK cluster. OSI pipelines consume the incoming data from the local MSK cluster and persist it to an Amazon OpenSearch Serverless collection within the same AWS Region. To achieve cross-Region data synchronization, Amazon MSK Replicator facilitates bidirectional replication between the Amazon MSK clusters, preserving the same topic names across both environments. This design validates that Amazon OpenSearch Serverless collections in each AWS Region maintain identical datasets, provides low-latency search capabilities and high availability for globally distributed workloads.
Prerequisites
Deploy the AWS Cloudformation template to install the prerequisites. The solution has the following prerequisite steps:
- Set up Amazon Virtual Private Cloud (Amazon VPC) infrastructure in both Regions
- Create Amazon VPCs with private subnets in at least two or three Availability Zones for high availability at the AWS Region level
- Configure Network Address Translation (NAT) Gateways for outbound internet access from private subnets
- Use non-overlapping CIDR blocks
- Establish Amazon OpenSearch Serverless collections in both AWS Regions
- Create Amazon OpenSearch Serverless Collections for log analytics
- Configure encryption, network, and data access policies
- Create Amazon VPC endpoints for private access
- Configure MSK clusters in both AWS Regions
- Enable AWS Identity and Access Management (IAM) authentication (SASL/IAM)
- Enable Multi-VPC connectivity (required for Amazon MSK Replicator and OSI)
- Configure MSK cluster policies to allow kafka.amazonaws.com and osis-pipelines.amazonaws.com service principals
- Configure IAM permissions for pipeline and replication access
- Create IAM roles for the OSI pipelines with permissions to access Amazon Managed Streaming for Apache Kafka and Amazon OpenSearch Serverless.
- Create IAM roles for the Amazon MSK Replicator with permissions for cross-Region access to Amazon Managed Streaming for Apache Kafka clusters.
This AWS CloudFormation template helps you in deploying all of the required configurations with primary AWS Region as us-east-1 and secondary AWS Region as us-west-2.
The following snippets shows the configuration for the OSI pipeline, which writes data from Amazon MSK to Amazon OpenSearch Serverless. The OSI pipeline uses MSK as a source with IAM authentication.
The OSI pipeline IAM Role has the required permission for Amazon MSK and Amazon OpenSearch Serverless to consume message data from the source and write data to the destination. For true active-active replication, sample deploys two Amazon MSK Replicators in each AWS Region. Each Amazon MSK cluster requires cluster policy to allow Amazon MSK Replicator and OSI to connect. To validate the bidirectional replication, the solution uses AWS Lambda functions to produce test messages to both Amazon MSK clusters.
When an application generates an event, it first publishes the message to an Apache Kafka topic in the Regional streaming cluster powered by Amazon Managed Streaming for Apache Kafka. In this sample deployment, an AWS Lambda function simulates application activity by producing events into the topic. These events are durably stored in the Apache Kafka partitions, providing a reliable buffer between producers and downstream consumers. An ingestion pipeline built using Amazon OpenSearch Ingestion continuously reads the event stream from the Apache Kafka topic and prepares the data for indexing. The pipeline then indexes the processed events into a collection in Amazon OpenSearch Serverless, making the data searchable in near real time.
At the same time, Amazon MSK Replicator replicates the Apache Kafka topic to a peer Amazon MSK cluster in a secondary AWS Region while preserving the topic structure. This makes the same event stream available in the secondary AWS Region without requiring changes to downstream consumers. An OpenSearch Ingestion pipeline in the secondary AWS Region consumes the replicated topic and indexes the events into its local OpenSearch Serverless collection. As events continue to flow through the system, both AWS Regions maintain synchronized datasets that can be queried independently. This architecture enables low-latency Regional search while maintaining a resilient, cross-Region copy of the indexed data.
Failover scenario and considerations
You can failover your application to the Amazon OpenSearch Serverless collection in the other AWS Region and continue operations without interruption. The data present before the impairment is available in both collections. Upon recovery, Amazon MSK Replicator and OSI pipelines automatically resume operations without manual intervention. Data that you write to the healthy AWS Region during the impairment is automatically backfilled to the recovered AWS Region. For detailed step-by-step guidance, see disaster recovery section in GitHub repo.
When using Amazon MSK Replicator, be aware that cross-Region data transfer incurs additional costs. To help verify reliability, configure Dead Letter Queues (DLQ) for OSI pipelines to capture failed document ingestion. Additionally, monitor essential Amazon CloudWatch metrics including ReplicationLatency for tracking lag between clusters, DocumentsFailed for identifying ingestion issues, and MessagesInPerSec for observing message throughput.
Persistent buffering in OSI provides a built-in safety net that prevents data loss when data producers send information faster than your OpenSearch cluster can process it, removing the need to provision and manage separate buffering infrastructure. By using managed storage across multiple Availability Zones, this feature enhances data durability while dynamically allocating OpenSearch Compute Units (OCUs) for both buffering and data processing, which incurs additional costs. Persistent buffering isn’t enabled by default. Without it, the OSI pipeline relies on an in-memory buffer, which is volatile and has limited capacity for storing incoming data before processing.
Conclusion
In this post, we showed you how to achieve cross-Regional resiliency for Amazon OpenSearch Serverless and OpenSearch Service managed clusters. In our experiments, most writes of a few KBs of data completed within one to a few seconds between the two chosen AWS Regions. Replication lag between the AWS Regions depends on network delay between chosen Regions and the settings configured on Amazon Opensearch Ingestion (OSI) pipeline.
Refer to AWS Service Level Agreements (SLAs) and Amazon Opensearch Ingestion (OSI) for more details. You can also achieve active-passive replication for OpenSearch using OSI and Amazon Simple Storage Service (Amazon S3) as mentioned in another post Achieve cross-Region resilience with Amazon OpenSearch Ingestion.