AWS Big Data Blog
Category: Amazon DynamoDB

Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Toyota Motor Corporation (TMC), a global automotive manufacturer, has made “connected cars” a core priority as part of its broader transformation from an auto company to a mobility company. In recent years, […]

How Siemens built a fully managed scheduling mechanism for updates on Amazon S3 data lakes
Siemens is a global technology leader with more than 370,000 employees and 170 years of experience. To protect Siemens from cybercrime, the Siemens Cyber Defense Center (CDC) continuously monitors Siemens’ networks and assets. To handle the resulting enormous data load, the CDC built a next-generation threat detection and analysis platform called ARGOS. ARGOS is a […]
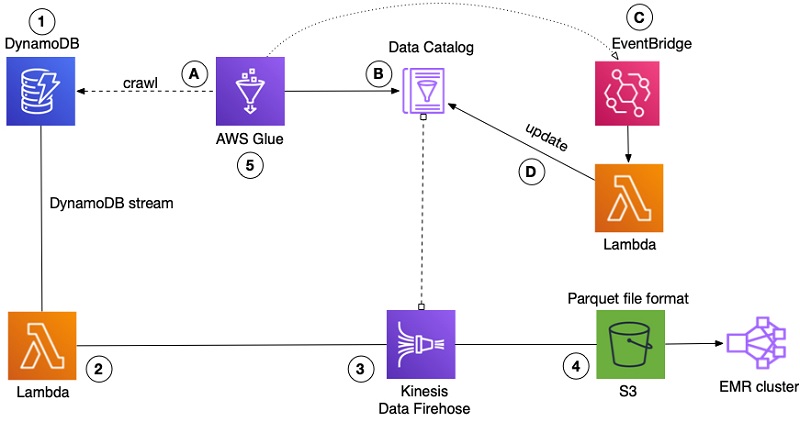
How FactSet automated exporting data from Amazon DynamoDB to Amazon S3 Parquet to build a data analytics platform
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest post by Arvind Godbole, Lead Software Engineer with FactSet and Tarik Makota, AWS Principal Solutions Architect. In their own words “FactSet creates flexible, open data and software solutions […]
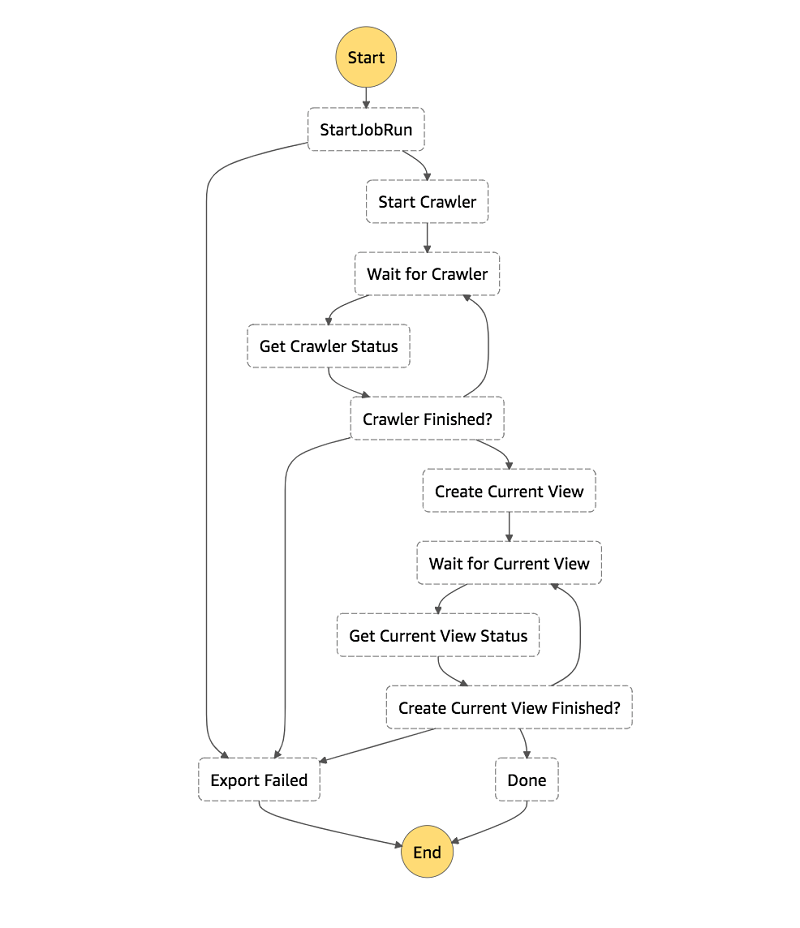
How to export an Amazon DynamoDB table to Amazon S3 using AWS Step Functions and AWS Glue
In this post, I show you how to use AWS Glue’s DynamoDB integration and AWS Step Functions to create a workflow to export your DynamoDB tables to S3 in Parquet. I also show how to create an Athena view for each table’s latest snapshot, giving you a consistent view of your DynamoDB table exports.

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.

How Goodreads offloads Amazon DynamoDB tables to Amazon S3 and queries them using Amazon Athena
In this post, we show you how to export data from a DynamoDB table, convert it into a more efficient format with AWS Glue, and query the data with Athena. This approach gives you a way to pull insights from your data stored in DynamoDB.

Analyze data in Amazon DynamoDB using Amazon SageMaker for real-time prediction
I’ll describe how to read the DynamoDB backup file format in Data Pipeline, how to convert the objects in S3 to a CSV format that Amazon ML can read, and I’ll show you how to schedule regular exports and transformations using Data Pipeline.
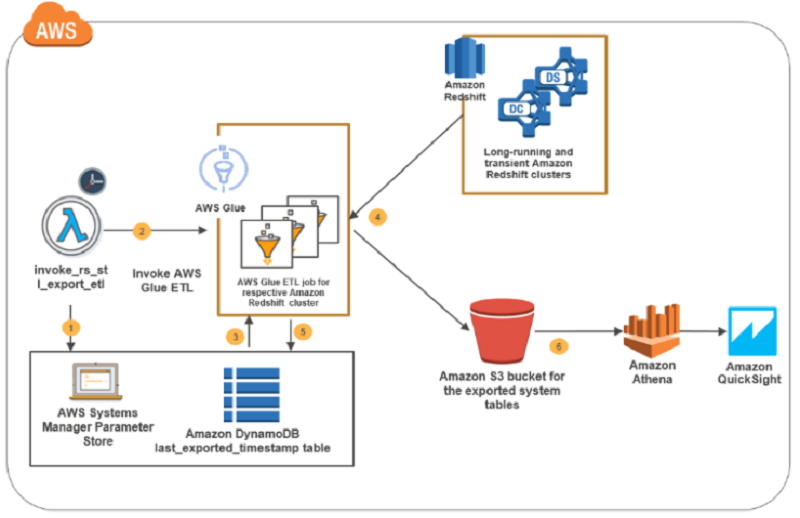
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.
Best Practices for Running Apache Cassandra on Amazon EC2
In this post, we outline three Cassandra deployment options, as well as provide guidance about determining the best practices for your use case.