AWS Big Data Blog
Category: AWS Data Pipeline

Migrate workloads from AWS Data Pipeline
After careful consideration, we have made the decision to close new customer access to AWS Data Pipeline, effective July 25, 2024. AWS Data Pipeline existing customers can continue to use the service as normal. AWS continues to invest in security, availability, and performance improvements for AWS Data Pipeline, but we do not plan to introduce […]

Analyze data in Amazon DynamoDB using Amazon SageMaker for real-time prediction
I’ll describe how to read the DynamoDB backup file format in Data Pipeline, how to convert the objects in S3 to a CSV format that Amazon ML can read, and I’ll show you how to schedule regular exports and transformations using Data Pipeline.
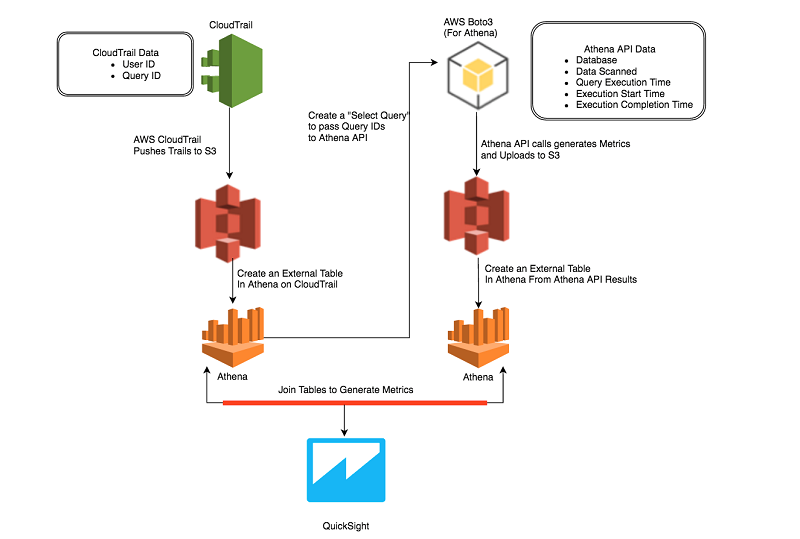
How Realtor.com Monitors Amazon Athena Usage with AWS CloudTrail and Amazon QuickSight
In this post, I discuss how to build a solution for monitoring Athena usage. To build this solution, you rely on AWS CloudTrail. CloudTrail is a web service that records AWS API calls for your AWS account and delivers log files to an S3 bucket.

Introducing On-Demand Pipeline Execution in AWS Data Pipeline
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]
Using AWS Lambda for Event-driven Data Processing Pipelines
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]
Automating Analytic Workflows on AWS
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]
How Coursera Manages Large-Scale ETL using AWS Data Pipeline and Dataduct
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]
Using AWS Data Pipeline’s Parameterized Templates to Build Your Own Library of ETL Use-case Definitions
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]
ETL Processing Using AWS Data Pipeline and Amazon Elastic MapReduce
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]