AWS Big Data Blog
How FactSet automated exporting data from Amazon DynamoDB to Amazon S3 Parquet to build a data analytics platform
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more.
This is a guest post by Arvind Godbole, Lead Software Engineer with FactSet and Tarik Makota, AWS Principal Solutions Architect. In their own words “FactSet creates flexible, open data and software solutions for tens of thousands of investment professionals around the world, which provides instant access to financial data and analytics that investors use to make crucial decisions. At FactSet, we are always working to improve the value that our products provide.”
One area that we’ve been looking into is the relevancy of search results for our clients. Given the wide variety of client use cases and the large number of searches per day, we needed a platform to store anonymized usage data and allow us to analyze that data to boost results using our custom scoring algorithm. Amazon EMR was the obvious choice to host the calculations, but the question arose on how to get our anonymized data into a form that Amazon EMR could use. We worked with AWS and chose to use Amazon DynamoDB to prepare the data for usage in Amazon EMR.
This post walks you through how FactSet takes data from a DynamoDB table and converts that data into Apache Parquet. We store the Parquet files in Amazon S3 to enable near real-time analysis with Amazon EMR. Along the way, we encountered challenges related to data type conversion, which we will explain and show how we were able to overcome these.
Workflow overview
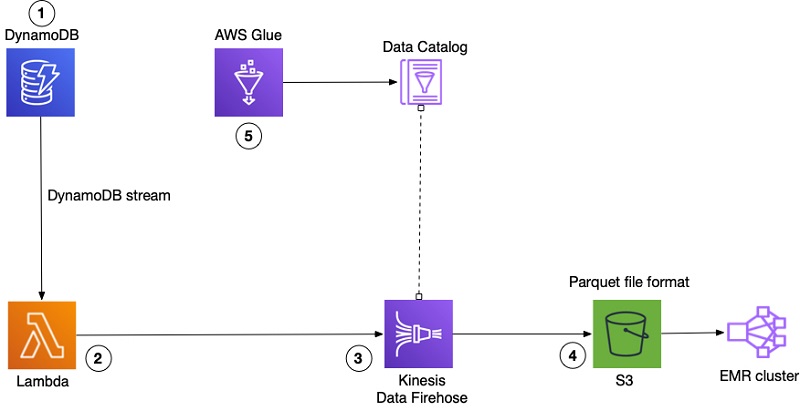
Our workflow contained the following steps:
- Anonymized log data is stored into DynamoDB tables. These entries have different fields, depending on how the logs were generated. Whenever we create items in the tables, we use DynamoDB Streams to write out a record. The stream records contain information from a single item in a DynamoDB table.
- An AWS Lambda function is hooked into the DynamoDB stream to capture the new items stored in a DynamoDB table. We built our Lambda function off of the lambda-streams-to-firehose project on GitHub to convert the DynamoDB stream image to JSON, which we stringify and push to Amazon Kinesis Data Firehose.
- Kinesis Data Firehose transforms the JSON data into Parquet using data contained within an AWS Glue Data Catalog table.
- Kinesis Data Firehose stores the Parquet files in S3.
- An AWS Glue crawler discovers the schema of DynamoDB items and stores the associated metadata into the Data Catalog.
The following diagram illustrates this workflow.
AWS Glue provides tools to help with data preparation and analysis. A crawler can run on a DynamoDB table to take inventory of the table data and store that information in a Data Catalog. Other services can use the Data Catalog as an index to the location, schema, and types of the table data. There are other ways to add metadata into a Data Catalog, but the key idea is that you can update and modify the metadata easily. For more information, see Populating the AWS Glue Data Catalog.
Problem: Data type disparities
Using a variety of technologies to build a solution often requires mapping and converting data types between these technologies. The cloud is no exception. In our case, log items stored in DynamoDB contained attributes of type String Set. String Set values caused data conversion exceptions when Kinesis tried to transform the data to Parquet. After investigating the problem, we found the following:
- As the crawler indexes the DynamoDB table, Set data types (
StringSet,NumberSet) are stored in the Glue metadata catalog asset<string>andset<bigint>. - Kinesis Data Firehose uses that same catalog when it performs the conversion to Apache Parquet. The conversion requires valid Hive data types.
set<string>andset<bigint>are not valid Hive data types, so the conversion fails, and an exception is generated. The exception looks similar to the following code:
Solution: Construct data mapping
While working with the AWS team, we confirmed that the Kinesis Data Firehose converter needs valid Hive data types in the Data Catalog to succeed. When it comes to complex data types, Hive doesn’t support set<data_type>, but it does support the following:
ARRAY<data_type>MAP<primitive_type, data_typeSTRUCT<col_name : data_type [COMMENT col_comment], ...>UNIONTYPE<data_type, data_type, ...>
In our case, this meant that we must convert set<string> and set<bigint> into array<string> and array<bigint>. Our first step was to manually change the types directly in the Data Catalog. After we updated the Data Catalog to change all occurrences of set<data_type> to array<data_type>, the Kinesis transformation to Parquet completed successfully.
Our business case calls for a data store that can store items with different attributes in the same table and the addition of new attributes on-the-fly. We took advantage of DynamoDB’s schema-less nature and ability to scale up and down on-demand so we could focus on our functionality and not the management of the underlying infrastructure. For more information, see Should Your DynamoDB Table Be Normalized or Denormalized?
If our data had a static schema, a manual change would be good enough. Given our business case, a manual solution wasn’t going to scale. Every time we introduced new attributes to the DynamoDB table, we needed to run the crawler, which re-created the metadata and overwrote the change.
Serverless event architecture
To automate the data type updates to the Data Catalog, we used Amazon EventBridge and Lambda to implement the modifications to the data type mapping. EventBridge is a serverless event bus that connects applications using events. An event is a signal that a system’s state has changed, such as the status of a Data Catalog table.
The following diagram shows the previous workflow with the new architecture.
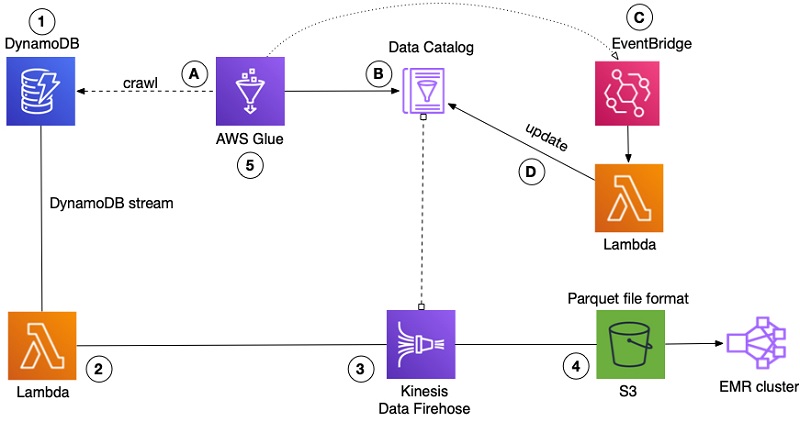
- The crawler stays as-is and crawls the DynamoDB table to obtain the metadata.
- The metadata obtained by the crawler is stored in the Data Catalog. Previous metadata is updated or removed, and changes (manual or automated) are overwritten.
- The event
GlueTableChangedin EventBridge listens to any changes to the Data Catalog tables. After we receive the event that there was a change to the table, we trigger the Lambda function. - The Lambda function uses AWS SDK to update the Glue Catalog table using the
glue.update_table()API to replace occurrences ofset<data_type>witharray<data_type>.
To set up EventBridge, we set Event pattern to be “Pre-defined pattern by service”. For service provider, we selected AWS and Glue as service. Event Type we selected “Glue Data Catalog Table State Change”. The following screenshot shows the EventBridge configuration that sends events to the Lambda function that updates the Data Catalog.

The following is the baseline Lambda code:
The Lambda function is straightforward; this post provides a basic skeleton. You can use this as a template to implement your own functionality for your specific data.
Conclusion
Simple things such as data type conversion and mapping can create unexpected outcomes and challenges when data crosses service boundaries. One of the advantages of AWS is the wide variety of tools with which you can create robust and scalable solutions tailored to your needs. Using event-driven architecture, we solved our data type conversion errors and automated the process to eliminate the issue as we move forward.
About the Authors
 Arvind Godbole is a Lead Software Engineer at FactSet Research Systems. He has experience in building high-performance, high-availability client facing products and services, ranging from real-time financial applications to search infrastructure. He is currently building an analytics platform to gain insights into client workflows. He holds a B.S. in Computer Engineering from the University of California, San Diego
Arvind Godbole is a Lead Software Engineer at FactSet Research Systems. He has experience in building high-performance, high-availability client facing products and services, ranging from real-time financial applications to search infrastructure. He is currently building an analytics platform to gain insights into client workflows. He holds a B.S. in Computer Engineering from the University of California, San Diego
 Tarik Makota is a Principal Solutions Architect with the Amazon Web Services. He provides technical guidance, design advice and thought leadership to AWS’ customers across US Northeast. He holds an M.S. in Software Development and Management from Rochester Institute of Technology.
Tarik Makota is a Principal Solutions Architect with the Amazon Web Services. He provides technical guidance, design advice and thought leadership to AWS’ customers across US Northeast. He holds an M.S. in Software Development and Management from Rochester Institute of Technology.