AWS Big Data Blog
Tag: DynamoDB

How Smartsheet built Real-time Dynamic Filtering on Apache Flink reducing $40K/month in messaging costs
In this post, you learn how Smartsheet built a Real-time Dynamic Filtering (RDF) system on Amazon Managed Service for Apache Flink, cutting messaging costs by over $40,000 per month and improving live collaboration latency by 1.8x.

Improve DynamoDB analytics with AWS Glue zero-ETL schema and partition controls
In this post, you learn how to replicate Amazon DynamoDB data to Apache Iceberg tables in Amazon S3 through a zero-ETL integration. We walk through the challenges that the DynamoDB nested, schema-flexible data model introduces for analytics workloads, and show you how to configure schema unnesting and data partitioning for a sample product catalog table. We also cover how to query the replicated data in Amazon Athena using standard SQL.

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]
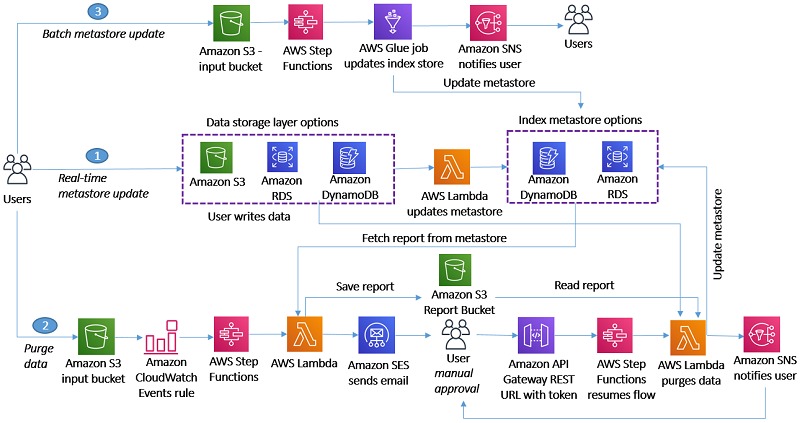
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]

Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Toyota Motor Corporation (TMC), a global automotive manufacturer, has made “connected cars” a core priority as part of its broader transformation from an auto company to a mobility company. In recent years, […]

How Siemens built a fully managed scheduling mechanism for updates on Amazon S3 data lakes
Siemens is a global technology leader with more than 370,000 employees and 170 years of experience. To protect Siemens from cybercrime, the Siemens Cyber Defense Center (CDC) continuously monitors Siemens’ networks and assets. To handle the resulting enormous data load, the CDC built a next-generation threat detection and analysis platform called ARGOS. ARGOS is a […]
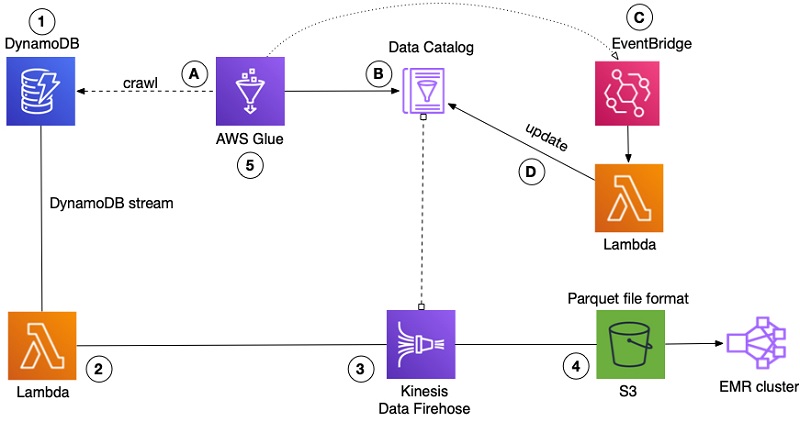
How FactSet automated exporting data from Amazon DynamoDB to Amazon S3 Parquet to build a data analytics platform
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest post by Arvind Godbole, Lead Software Engineer with FactSet and Tarik Makota, AWS Principal Solutions Architect. In their own words “FactSet creates flexible, open data and software solutions […]
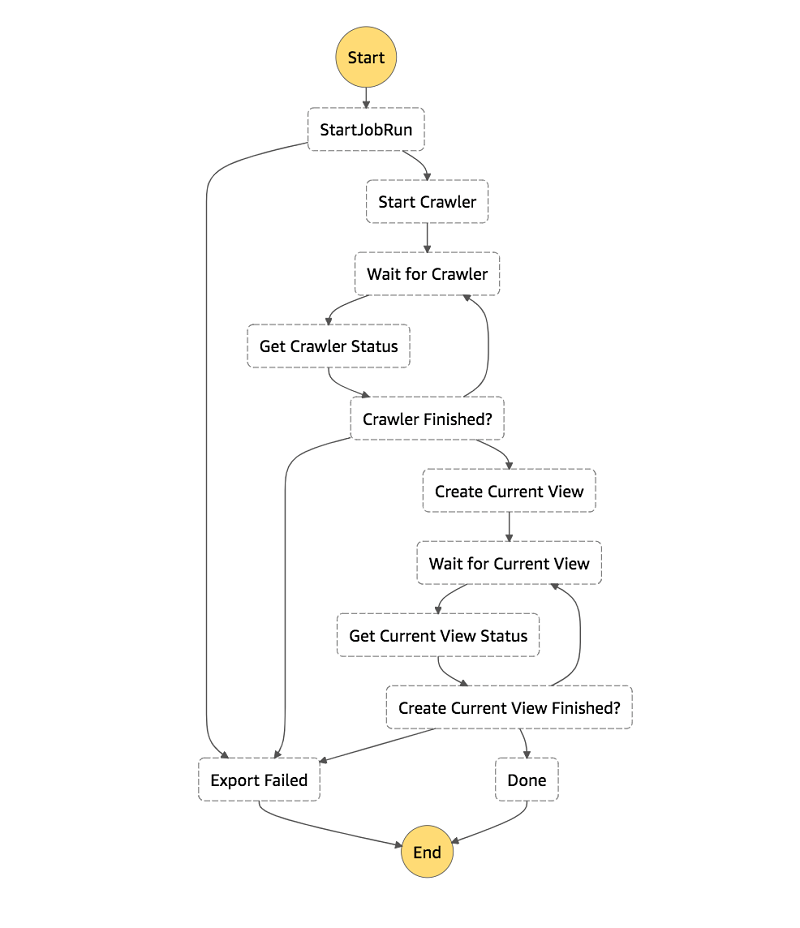
How to export an Amazon DynamoDB table to Amazon S3 using AWS Step Functions and AWS Glue
In this post, I show you how to use AWS Glue’s DynamoDB integration and AWS Step Functions to create a workflow to export your DynamoDB tables to S3 in Parquet. I also show how to create an Athena view for each table’s latest snapshot, giving you a consistent view of your DynamoDB table exports.
Best Practices for Running Apache Cassandra on Amazon EC2
In this post, we outline three Cassandra deployment options, as well as provide guidance about determining the best practices for your use case.

Analysis of Top-N DynamoDB Objects using Amazon Athena and Amazon QuickSight
If you run an operation that continuously generates a large amount of data, you may want to know what kind of data is being inserted by your application. The ability to analyze data intake quickly can be very valuable for business units, such as operations and marketing. For many operations, it’s important to see what […]