AWS Big Data Blog
How Smartsheet built Real-time Dynamic Filtering on Apache Flink reducing $40K/month in messaging costs
Processing hundreds of thousands of events per second while maintaining sub-second latency is a challenge many organizations face when building real-time data-driven applications. When filter policy changes propagate in up to 15 minutes, dynamic event routing becomes impractical, forcing teams to over-consume events and discard over 90% after costly per-event lookups. Smartsheet, a work management solution serving millions of users and processing hundreds of thousands of events per second to power features like live collaboration, workflows, and real-time notifications, faced exactly this problem.
In this post, you learn how Smartsheet built a Real-time Dynamic Filtering (RDF) system on Amazon Managed Service for Apache Flink, cutting messaging costs by over $40,000 per month and improving live collaboration latency by 1.8x.
The challenge: Static filter policies in a dynamic world
The Smartsheet event-driven architecture publishes hundreds of thousands of events per second to an Amazon Simple Notification Service (Amazon SNS) topic. Internal teams subscribe to this topic, typically by creating an Amazon Simple Queue Service (Amazon SQS) queue with an associated SNS filter policy defined through infrastructure as code (IaC). These filter policies are typically static and specify the types of events a consumer wants to receive, such as “sheet row created,” “sheet row updated,” or “sheet row deleted.”
Although SNS supports programmatic changes to filter policies, the SNS documentation notes that changes can take up to 15 minutes to take effect. This eventual consistency window created a significant problem for Smartsheet live collaboration feature.
Live collaboration requires knowing, in real time, which sheets have active collaborators. When a user opens a sheet, the system needs to immediately start receiving events for that sheet. When they close it, the system should stop. With a 15-minute propagation delay on filter policy changes, dynamic per-sheet filtering through SNS was impractical.
The workaround was brute force: subscribe to all events (hundreds of thousands per second), pull them into an SQS queue, and use compute to check each event against Amazon DynamoDB to determine whether the sheet had active collaborators. Over 90% of events were discarded after this lookup.
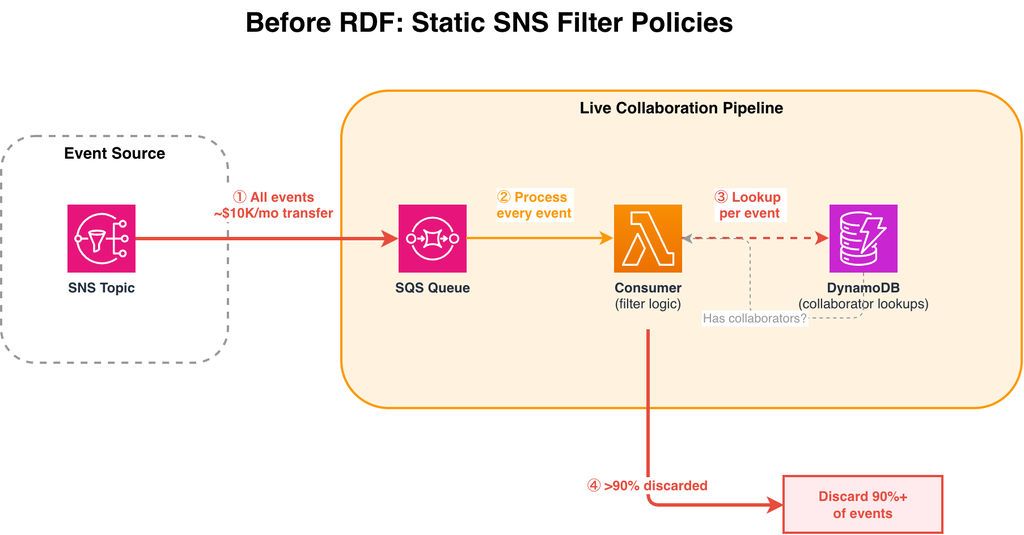
Figure 1: Before RDF — all events flow through SNS to SQS, with per-event DynamoDB lookups to filter. Over 90% of events are discarded after processing.
- Every event published to the SNS topic is delivered to the SQS queue, regardless of whether any consumer needs it.
- The consumer AWS Lambda reads every message from the SQS queue and must evaluate each one individually.
- For each event, the consumer queries DynamoDB to check whether the sheet has active collaborators. This per-event lookup adds latency and DynamoDB read costs on the hot path.
- After the DynamoDB lookup, over 90% of events are found to have no active collaborators and are discarded.
This approach had three compounding cost and performance problems:
- SNS-to-SQS data transfer costs: approximately $10,000 per month to deliver all events to the queue
- SQS costs: approximately $30,000 per month to receive, process, and delete the full event volume
- DynamoDB costs and latency: per-event lookups to check collaborator status added load to DynamoDB and increased end-to-end data delivery latency
The solution: Real-time Dynamic Filtering with Apache Flink
To solve this, Smartsheet built a system called Real-time Dynamic Filtering (RDF) on Amazon Managed Service for Apache Flink. The core insight was to move the filtering logic into the stream processing layer itself, using Flink’s KeyedCoProcessFunction, a feature that joins and processes multiple streams by a shared key, to maintain dynamic filter policies in Flink state (RocksDB).
How it works
The RDF Flink application reads from two streams:
- Filter policy stream, sourced from Amazon DynamoDB Streams. When a team calls the RDF client to change their filter policy (for example, “start receiving events for sheet X”), the change is written to a DynamoDB table and propagated through DynamoDB Streams to the Flink application.
- Data stream, the stream of sheet events (creates, updates, deletes) that were previously delivered through SNS.
One challenge remained: some consumers need every event, regardless of sheet. When a consumer subscribes to all events, the system needs every parallel Flink task to know about it. The team solved this using Flink’s broadcast state, which replicates a small set of “subscribe to everything” policies across all tasks. Because only a handful of consumers use this mode, the memory overhead stays negligible.
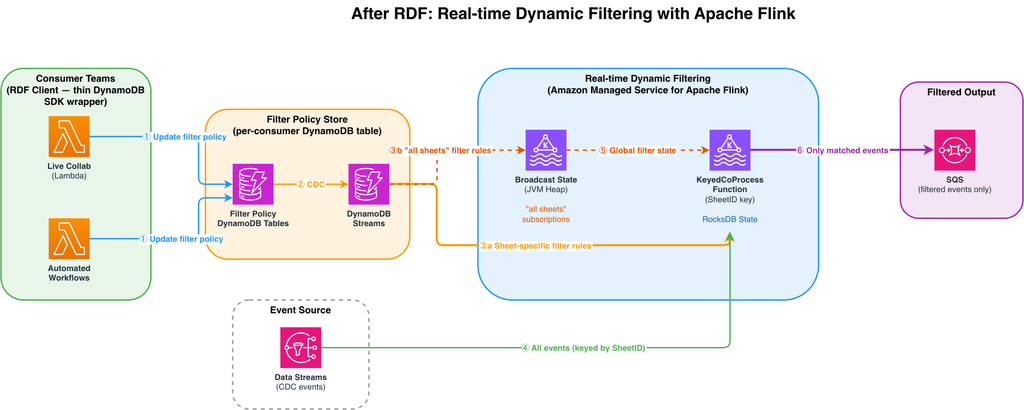
Figure 2: After RDF — consumer teams update filter policies via client libraries. DynamoDB Streams propagates changes to the Flink application, which filters the data stream in real time using keyed state (RocksDB) for specific sheet subscriptions and broadcast state for “all sheets” subscriptions.
- When a consumer team wants to start or stop receiving events for a specific sheet, it calls the RDF client, a thin wrapper over the DynamoDB SDK. The filter policy change is written to that consumer’s dedicated DynamoDB table. Each consumer has its own table, providing isolated permissions and preventing noisy neighbor issues.
- DynamoDB Streams captures every filter policy change as a change data capture (CDC) record and streams it to the Flink application in real time.
- Filter policy records
- Filter policy records for specific sheets are routed to the
KeyedCoProcessFunction, keyed bySheetID. This makes sure that filter state and event data for the same sheet are co-located in the same Flink parallel task. State is stored in the RocksDB backend, which uses memory when available and spills to disk when necessary, so the system to scale without JVM heap constraints. - Filter policy records where a consumer has called
listenToAllEvents()are broadcast to all parallel Flink tasks via Flink’s broadcast state. Because broadcast state lives in JVM heap, it is used exclusively for these “all sheets” records (of which there are very few), keeping the heap footprint small.
- Filter policy records for specific sheets are routed to the
- The full stream of CDC events flows into the
KeyedCoProcessFunction, partitioned by SheetID. Each parallel task receives only the events for the sheets it is responsible for and applies the corresponding filter state to decide whether to forward or drop each event. - The broadcast state (containing “all sheets” subscriptions) is made available to all parallel instances of the
KeyedCoProcessFunction, so that consumers subscribed to all events are never filtered out regardless of which task processes their events. - Only events that match an active filter policy are forwarded to the consumer’s SQS queue. The result: sub-second filter policy propagation (p95 ≤1s), elimination of per-event DynamoDB lookups, and over $40,000/month in cost savings.
Critically, because the filter policy state is persisted in Flink’s RocksDB state backend, the application does not need to perform a DynamoDB lookup for every event. Within 1 second of a filter policy change, the Flink application reads the change from the DynamoDB Streams source, updates its internal state, and begins filtering the data stream accordingly.
Results
The impact of RDF was immediate and measurable across multiple dimensions:
Cost reduction
| Cost category | Before RDF | After RDF | Monthly savings |
|---|---|---|---|
| SNS → SQS Data Transfer | ~$10K/month | Eliminated | ~$10K |
| SQS Event Ingestion | ~$30K/month | ~$2K | ~$28K |
| DynamoDB Collaborator Lookups | Significant load | Eliminated (state in Flink) | Included in total |
| AWS Lambda | ~$12K/month | ~$5K/month | ~$7K |
| Total | ~$45K/month |
Latency improvement
- 1.8x improvement in live collaboration data delivery latency. Users see changes from collaborators faster than before.
- Filter policy propagation reduced from up to 15 minutes to a p95 of under 1 second
If your architecture follows a similar fan-out pattern where consumers discard a large percentage of events after per-event lookups, you could achieve comparable cost reductions by moving filtering into the stream processing layer. The savings scale with your event volume and the percentage of events currently discarded.
Key design decisions
Several architectural choices were critical to the success of this solution:
- Keyed state with selective broadcast: Specific sheet subscriptions are stored in keyed state using the RocksDB state backend. The system scales to a large number of filter policies without JVM heap constraints. Flink’s broadcast state is used only for the small number of “all sheets” subscriptions, where every parallel task needs visibility. Because broadcast state is stored in JVM heap, limiting its use to these few records keeps the heap footprint manageable.
- DynamoDB Streams as the filter policy source: Rather than building a custom control plane, the team used DynamoDB Streams to propagate filter policy changes. DynamoDB Streams gave the team durability, ordering guarantees, and a native Flink source connector integration.
- RocksDB state backend: Persisting filter state in RocksDB eliminated the need for external lookups on the hot path, keeping per-event processing latency low even as the number of active filter policies grows.
- Client library abstraction: Publishing internal Golang and Java clients lowered the adoption barrier. The client is a thin abstraction on top of the DynamoDB SDK. Each consumer has its own dedicated DynamoDB table and corresponding filter stream, which provides two benefits: it allows fine-grained AWS Identity and Access Management (AWS IAM) permissions per client, and it mitigates the noisy neighbor problem by isolating each consumer’s filter policy traffic. Teams don’t need to understand Flink internals. They interact with a simple API to manage their subscriptions.
Next steps
The live collaboration team was the first adopter of RDF, but the architecture was designed as a shared platform. Smartsheet is now expanding RDF to additional internal teams, including workflow automation and notification routing, where similar fan-out patterns exist. The team is also exploring automatic scaling policies to optimize Flink cluster costs during off-peak hours.
Conclusion
Smartsheet Real-time Dynamic Filtering system demonstrates how Amazon Managed Service for Apache Flink can solve problems that go beyond stream processing. By combining Flink’s broadcast state pattern with CoProcessFunction, Smartsheet replaced a costly and latency-bound SNS/SQS fan-out architecture with a sub-second dynamic filtering platform. The result: over $40,000 per month in savings, 1.8x improvement in live collaboration latency, and a reusable platform that multiple teams are now adopting.
If you process high-volume event streams and need to dynamically control which events reach specific consumers, this pattern can help you reduce costs and latency, whether for live collaboration, workflow automation, notification routing, or multi-tenant event delivery.
To learn more about the services used in this post, visit:
- Amazon Managed Service for Apache Flink
- Apache Flink Broadcast State Pattern
- Amazon DynamoDB Streams
- Amazon SNS Message Filtering