AWS Big Data Blog
Category: Database

Extract data from Amazon Aurora MySQL to Amazon S3 Tables in Apache Iceberg format
In this post, you learn how to set up an automated, end-to-end solution that extracts tables from Amazon Aurora MySQL Serverless v2 and writes them to Amazon S3 Tables in Apache Iceberg format using AWS Glue.

How Amplitude implemented natural language-powered analytics using Amazon OpenSearch Service as a vector database
Amplitude is a product and customer journey analytics platform. Our customers wanted to ask deep questions about their product usage. Ask Amplitude is an AI assistant that uses large language models (LLMs). It combines schema search and content search to provide a customized, accurate, low latency, natural language-based visualization experience to end customers. Amplitude’s search architecture evolved to scale, simplify, and cost-optimize for our customers, by implementing semantic search and Retrieval Augmented Generation (RAG) powered by Amazon OpenSearch Service. In this post, we walk you through Amplitude’s iterative architectural journey and explore how we address several critical challenges in building a scalable semantic search and analytics platform.

Modernize your data warehouse by migrating Oracle Database to Amazon Redshift with Oracle GoldenGate
In this post, we show how to migrate an Oracle data warehouse to Amazon Redshift using Oracle GoldenGate and DMS Schema Conversion, a feature of AWS Database Migration Service (AWS DMS). This approach facilitates minimal business disruption through continuous replication.
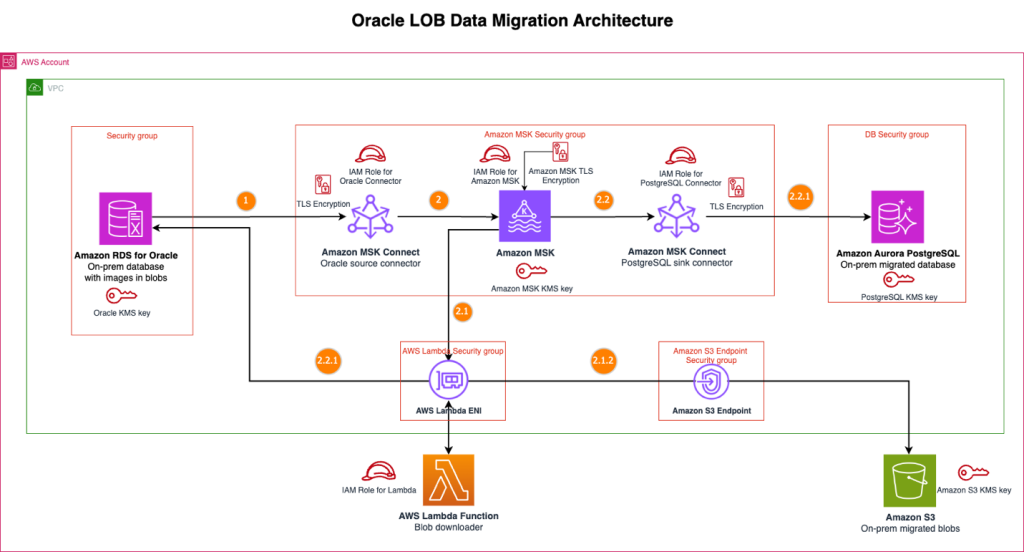
Streamline large binary object migrations: A Kafka-based solution for Oracle to Amazon Aurora PostgreSQL and Amazon S3
In this post, we present a scalable solution that addresses the challenge of migrating your large binary objects (LOBs) from Oracle to AWS by using a streaming architecture that separates LOB storage from structured data. This approach avoids size constraints, reduces Oracle licensing costs, and preserves data integrity throughout extended migration periods.

Integrating Amazon OpenSearch Ingestion with Amazon RDS and Amazon Aurora
We are happy to announce the general availability of the integration of Amazon OpenSearch Service with Amazon Relational Database Service (Amazon RDS) and Amazon Aurora. This new integration eliminates complex data pipelines and enables near real-time data synchronization between Amazon Aurora (including Amazon Aurora MySQL-Compatible Edition and Amazon Aurora PostgreSQL-Compatible Edition) and Amazon RDS databases (including Amazon RDS for MySQL and Amazon RDS for PostgreSQL), and Amazon OpenSearch Service, unlocking advanced search capabilities such as hybrid search, ranked results, and faceted search on transactional databases.

Revenue NSW modernises analytics with AWS, enabling unified and scalable data management, processing, and access
Revenue NSW, Australia’s principal revenue management agency, successfully modernized its analytics infrastructure using AWS services. In this blog post, we show how the organization transformed its on-premises data environment into a unified, scalable cloud-based solution using Amazon Redshift, AWS Database Migration Service, Amazon AppFlow, and AWS Glue.

Harnessing the Power of Nested Materialized Views and exploring Cascading Refresh
In this post, we explore how to maximize Amazon Redshift query performance through nested materialized views and implementing cascading refresh strategies. We demonstrate how to create materialized views based on other materialized views, enabling a hierarchical structure of precomputed results that significantly enhances query performance and data processing efficiency, particularly useful for reusing precomputed joins with different aggregate options.

Cross-account data collaboration with Amazon DataZone and AWS analytical tools
In this post, we will cover how you can use Amazon DataZone to facilitate data collaboration between AWS accounts.

How Open Universities Australia modernized their data platform and significantly reduced their ETL costs with AWS Cloud Development Kit and AWS Step Functions
At Open Universities Australia (OUA), we empower students to explore a vast array of degrees from renowned Australian universities, all delivered through online learning. In this post, we show you how we used AWS services to replace our existing third-party ETL tool, improving the team’s productivity and producing a significant reduction in our ETL operational costs.

Building end-to-end data lineage for one-time and complex queries using Amazon Athena, Amazon Redshift, Amazon Neptune and dbt
In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift. dbt on Athena supports real-time queries, while dbt on Amazon Redshift handles complex queries, unifying the development language and significantly reducing the technical learning curve. Using a single dbt modeling language not only simplifies the development process but also automatically generates consistent data lineage information. This approach offers robust adaptability, easily accommodating changes in data structures.