AWS Big Data Blog
Category: Amazon Neptune

Building end-to-end data lineage for one-time and complex queries using Amazon Athena, Amazon Redshift, Amazon Neptune and dbt
In this post, we use dbt for data modeling on both Amazon Athena and Amazon Redshift. dbt on Athena supports real-time queries, while dbt on Amazon Redshift handles complex queries, unifying the development language and significantly reducing the technical learning curve. Using a single dbt modeling language not only simplifies the development process but also automatically generates consistent data lineage information. This approach offers robust adaptability, easily accommodating changes in data structures.

How ZS built a clinical knowledge repository for semantic search using Amazon OpenSearch Service and Amazon Neptune
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. This platform is an advanced information retrieval system engineered to assist healthcare professionals and researchers in navigating vast repositories of medical documents, medical literature, research articles, clinical guidelines, protocol documents, […]

Harmonize data using AWS Glue and AWS Lake Formation FindMatches ML to build a customer 360 view
In today’s digital world, data is generated by a large number of disparate sources and growing at an exponential rate. Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their data lake to derive […]

Automate discovery of data relationships using ML and Amazon Neptune graph technology
Data mesh is a new approach to data management. Companies across industries are using a data mesh to decentralize data management to improve data agility and get value from data. However, when a data producer shares data products on a data mesh self-serve web portal, it’s neither intuitive nor easy for a data consumer to […]
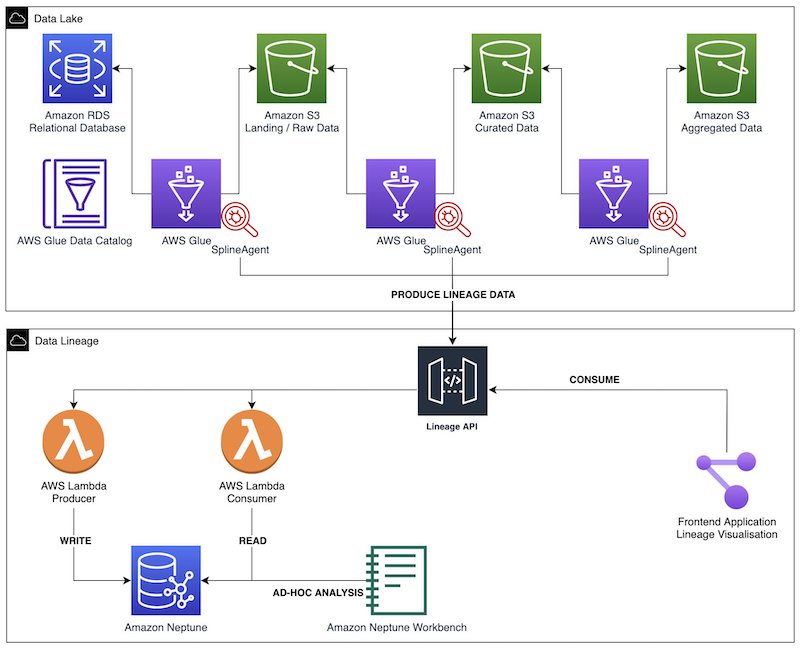
Build data lineage for data lakes using AWS Glue, Amazon Neptune, and Spline
Data lineage is one of the most critical components of a data governance strategy for data lakes. Data lineage helps ensure that accurate, complete and trustworthy data is being used to drive business decisions. While a data catalog provides metadata management features and search capabilities, data lineage shows the full context of your data by […]

Bringing machine learning to more builders through databases and analytics services
Machine learning (ML) is becoming more mainstream, but even with the increasing adoption, it’s still in its infancy. For ML to have the broad impact that we think it can have, it has to get easier to do and easier to apply. We launched Amazon SageMaker in 2017 to remove the challenges from each stage […]