AWS Big Data Blog
Category: Artificial Intelligence

Securing client confidentiality at scale: Automated data discovery and governed analytics for legal workloads
In this post, we show you a reference architecture that automates sensitive data discovery across legal document repositories on Amazon Web Services (AWS), demonstrate how to capture structured findings as a compliance dataset, and guide you through building a governed analytics workspace that maintains your security boundaries. You walk away with a practical model for building security and analytics into the same lifecycle, without moving documents outside their system of record.

Detect and resolve HBase inconsistencies faster with AI on Amazon EMR
In this post, we show you how to build an AI-powered troubleshooting solution using Amazon OpenSearch Service vector search and intelligent analysis. This solution reduces HBase inconsistency resolution from hours to minutes and root cause identification from days to hours through natural language queries over operational data. This democratizes HBase troubleshooting capabilities across teams and reducing dependency on specialized expertise.

Introducing Amazon MSK Express Broker power for Kiro
In this post, we’ll show you how to use Kiro powers, a new capability that equips Kiro with contextual knowledge and tooling. You can simplify your MSK cluster management, from initial setup to diagnosing common issues, all through natural language conversations.

Modernize business intelligence workloads using Amazon Quick
In this post, we provide implementation guidance for building integrated analytics solutions that combine the generative BI features of Amazon Quick with Amazon Redshift and Amazon Athena SQL analytics capabilities.

Agentic AI for observability and troubleshooting with Amazon OpenSearch Service
Now, Amazon OpenSearch Service brings three new agentic AI features to OpenSearch UI. In this post, we show how these capabilities work together to help engineers go from alert to root cause in minutes. We also walk through a sample scenario where the Investigation Agent automatically correlates data across multiple indices to surface a root cause hypothesis.

Improve the discoverability of your unstructured data in Amazon SageMaker Catalog using generative AI
This is a two-part series post. In the first part, we walk you through how to set up the automated processing for unstructured documents, extract and enrich metadata using AI, and make your data discoverable through SageMaker Catalog. The second part is currently in the works and will show you how to discover and access the enriched unstructured data assets as a data consumer. By the end of this post, you will understand how to combine Amazon Textract and Anthropic Claude through Amazon Bedrock to extract key business terms and enrich metadata using Amazon SageMaker Catalog to transform unstructured data into a governed, discoverable asset.
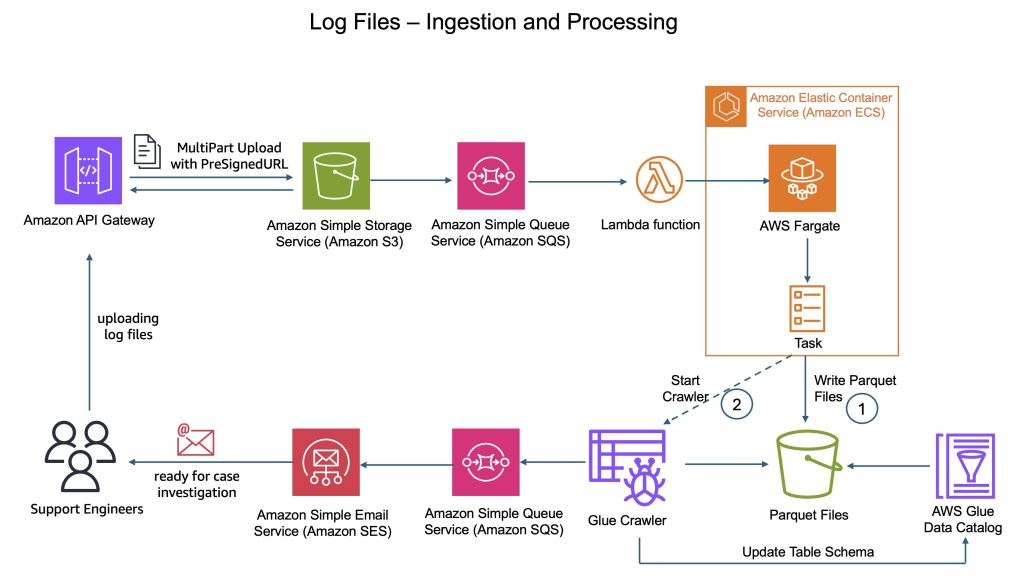
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.
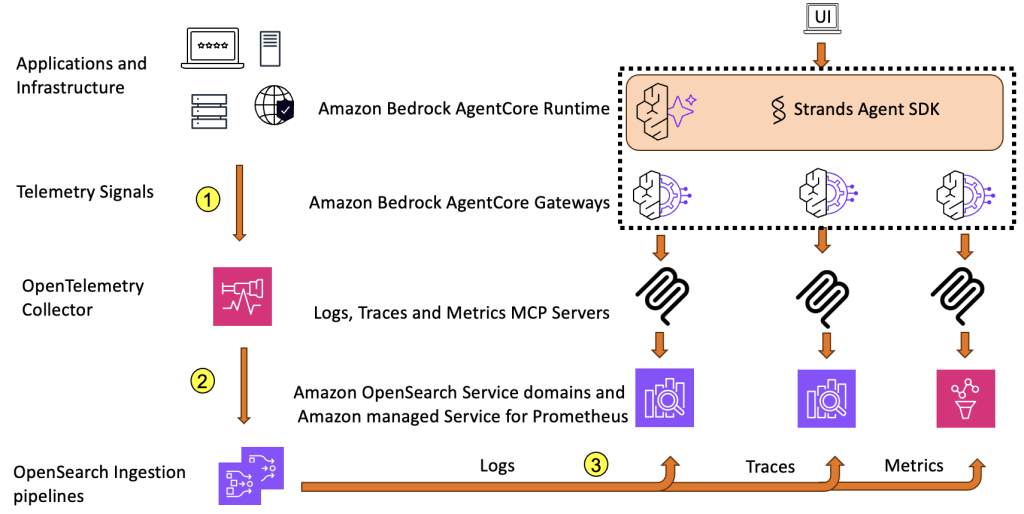
Reduce Mean Time to Resolution with an observability agent
In this post, we present an observability agent using OpenSearch Service and Amazon Bedrock AgentCore that can help surface root cause and get insights faster, handle multiple query-correlation cycles, and ultimately reduce MTTR even further.

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.

Get started faster with one-click onboarding, serverless notebooks, and AI agents in Amazon SageMaker Unified Studio
Using Amazon SageMaker Unified Studio serverless notebooks, AI-assisted development, and unified governance, you can speed up your data and AI workflows across data team functions while maintaining security and compliance. In this post, we walk you through how these new capabilities in SageMaker Unified Studio can help you consolidate your fragmented data tools, reduce time to insight, and collaborate across your data teams.