AWS Big Data Blog
Category: Amazon Machine Learning
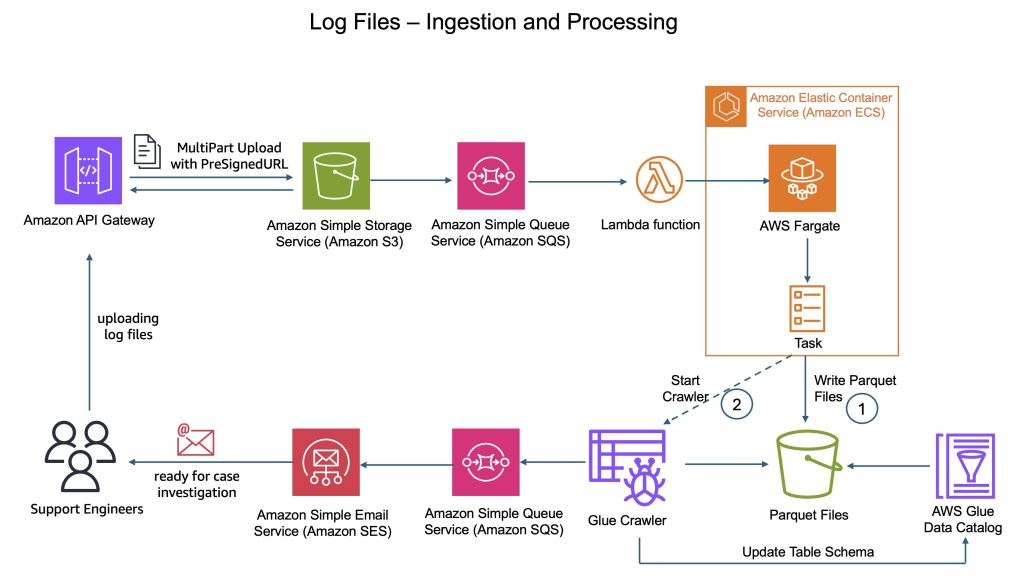
How CyberArk uses Apache Iceberg and Amazon Bedrock to deliver up to 4x support productivity
CyberArk is a global leader in identity security. Centered on intelligent privilege controls, it provides comprehensive security for human, machine, and AI identities across business applications, distributed workforces, and hybrid cloud environments. In this post, we show you how CyberArk redesigned their support operations by combining Iceberg’s intelligent metadata management with AI-powered automation from Amazon Bedrock. You’ll learn how to simplify data processing flows, automate log parsing for diverse formats, and build autonomous investigation workflows that scale automatically.
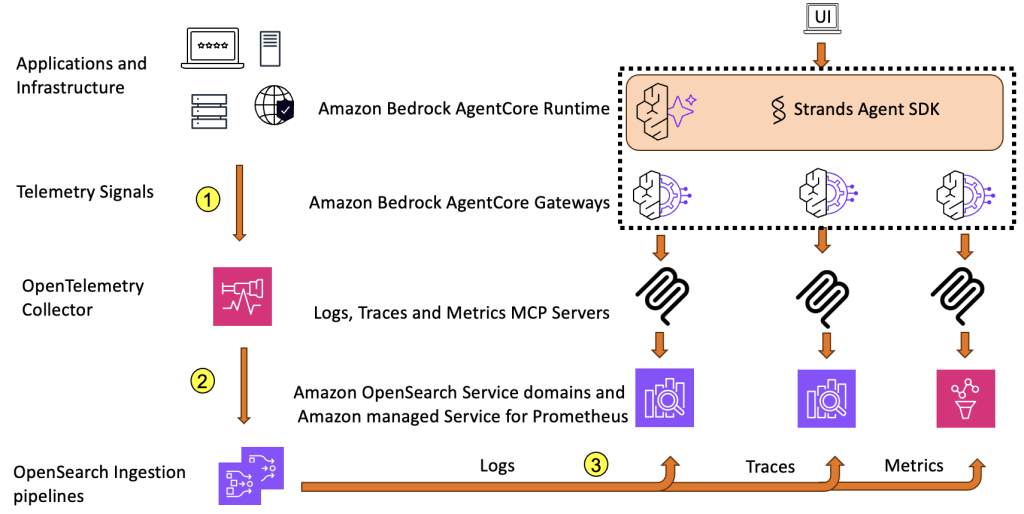
Reduce Mean Time to Resolution with an observability agent
In this post, we present an observability agent using OpenSearch Service and Amazon Bedrock AgentCore that can help surface root cause and get insights faster, handle multiple query-correlation cycles, and ultimately reduce MTTR even further.

Modernize game intelligence with generative AI on Amazon Redshift
In this post, we discuss how you can use Amazon Redshift as a knowledge base to provide additional context to your LLM. We share best practices and explain how you can improve the accuracy of responses from the knowledge base by following these best practices.
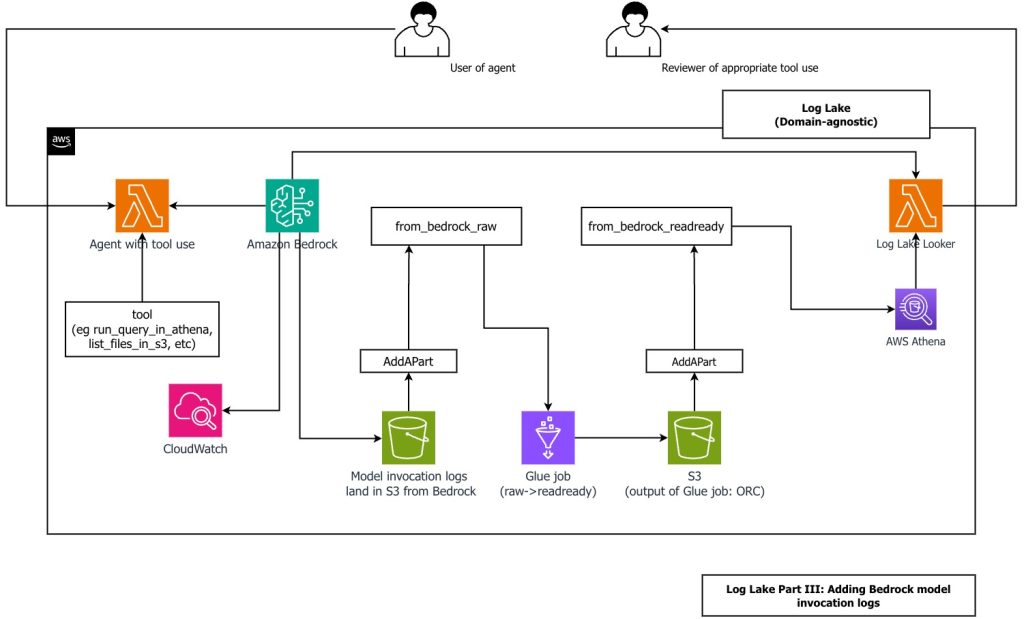
Create a customizable cross-company log lake, Part II: Build and add Amazon Bedrock
In this post, you learn how to build Log Lake, a customizable cross-company data lake for compliance-related use cases that combines AWS CloudTrail and Amazon CloudWatch logs. You’ll discover how to set up separate tables for writing and reading, implement event-driven partition management using AWS Lambda, and transform raw JSON files into read-optimized Apache ORC format using AWS Glue jobs. Additionally, you’ll see how to extend Log Lake by adding Amazon Bedrock model invocation logs to enable human review of agent actions with elevated permissions, and how to use an AI agent to query your log data without writing SQL.

How Slack achieved operational excellence for Spark on Amazon EMR using generative AI
In this post, we show how Slack built a monitoring framework for Apache Spark on Amazon EMR that captures over 40 metrics, processes them through Kafka and Apache Iceberg, and uses Amazon Bedrock to deliver AI-powered tuning recommendations—achieving 30–50% cost reductions and 40–60% faster job completion times.

Enhance Amazon EMR observability with automated incident mitigation using Amazon Bedrock and Amazon Managed Grafana
In this post, we demonstrate how to integrate real-time monitoring with AI-powered remediation suggestions, combining Amazon Managed Grafana for visualization, Amazon Bedrock for intelligent response recommendations, and AWS Systems Manager for automated remediation actions on Amazon Web Services (AWS).

Empower financial analytics by creating structured knowledge bases using Amazon Bedrock and Amazon Redshift
In this post, we showcase how financial planners, advisors, or bankers can now ask questions in natural language. These prompts will receive precise data from the customer databases for accounts, investments, loans, and transactions. Amazon Bedrock Knowledge Bases automatically translates these natural language queries into optimized SQL statements, thereby accelerating time to insight, enabling faster discoveries and efficient decision-making.

Improve search results for AI using Amazon OpenSearch Service as a vector database with Amazon Bedrock
In this post, you’ll learn how to use OpenSearch Service and Amazon Bedrock to build AI-powered search and generative AI applications. You’ll learn about how AI-powered search systems employ foundation models (FMs) to capture and search context and meaning across text, images, audio, and video, delivering more accurate results to users. You’ll learn how generative AI systems use these search results to create original responses to questions, supporting interactive conversations between humans and machines.

Enhancing Search Relevancy with Cohere Rerank 3.5 and Amazon OpenSearch Service
In this blog post, we’ll dive into the various scenarios for how Cohere Rerank 3.5 improves search results for best matching 25 (BM25), a keyword-based algorithm that performs lexical search, in addition to semantic search. We will also cover how businesses can significantly improve user experience, increase engagement, and ultimately drive better search outcomes by implementing a reranking pipeline.

Enrich your AWS Glue Data Catalog with generative AI metadata using Amazon Bedrock
By harnessing the capabilities of generative AI, you can automate the generation of comprehensive metadata descriptions for your data assets based on their documentation, enhancing discoverability, understanding, and the overall data governance within your AWS Cloud environment. This post shows you how to enrich your AWS Glue Data Catalog with dynamic metadata using foundation models (FMs) on Amazon Bedrock and your data documentation.