AWS Big Data Blog
Build data lineage for data lakes using AWS Glue, Amazon Neptune, and Spline
Data lineage is one of the most critical components of a data governance strategy for data lakes. Data lineage helps ensure that accurate, complete and trustworthy data is being used to drive business decisions. While a data catalog provides metadata management features and search capabilities, data lineage shows the full context of your data by capturing in greater detail the true relationships between data sources, where the data originated from and how it gets transformed and converged. Different personas in the data lake benefit from data lineage:
- For data scientists, the ability to view and track data flow as it moves from source to destination helps you easily understand the quality and origin of a particular metric or dataset
- Data platform engineers can get more insights into the data pipelines and the interdependencies between datasets
- Changes in data pipelines are easier to apply and validate because engineers can identify a job’s upstream dependencies and downstream usage to properly evaluate service impacts
As the complexity of data landscape grows, customers are facing significant manageability challenges in capturing lineage in a cost-effective and consistent manner. AWS Glue added built-in support for OpenLineage with AWS Glue 5.0. To learn more, see Introducing AWS Glue 5.0 for Apache Spark.
The Capture data lineage from dbt, Apache Airflow, and Apache Spark with Amazon SageMaker blog describes how you can use Amazon Sagemaker or Amazon Datazone’s OpenLineage-compatible API to push data lineage events programmatically from tools supporting the OpenLineage standard like dbt, Apache Airflow, and Apache Spark.
This post provides an approach if you are running a Spark-heavy ETL pipeline where you want automatic lineage for governance and troubleshooting without setting up an OpenLineage backend. We walk you through three steps in building an end-to-end automated data lineage solution for data lakes: lineage capturing, modeling and storage, and finally visualization.
In this solution, we capture both coarse-grained and fine-grained data lineage. Coarse-grained data lineage, which often targets business users, focuses on capturing the high-level business processes and overall data workflows. Typically, it captures and visualizes the relationships between datasets and how they’re propagated across storage tiers, including extract, transform and load (ETL) jobs and operational information. Fine-grained data lineage gives access to column-level lineage and the data transformation steps in the processing and analytical pipelines.
Solution overview
Apache Spark is one of the most popular engines for large-scale data processing in data lakes. Our solution uses the Spline agent to capture runtime lineage information from Spark jobs, powered by AWS Glue. We use Amazon Neptune, a purpose-built graph database optimized for storing and querying highly connected datasets, to model lineage data for analysis and visualization.
For those interested in lineage tracking for workloads combining graph data and machine learning, Amazon Web Services announced Amazon SageMaker ML Lineage Tracking at re:Invent 2021. SageMaker ML Lineage Tracking integrates with SageMaker Pipelines, creates and stores information about the steps of automated ML workflows from data preparation to model deployment. With the tracking information, you can reproduce the workflow steps, track model and graph dataset lineage, and establish model governance and audit standards.
The following diagram illustrates the solution architecture. We use AWS Glue Spark ETL jobs to perform data ingestion, transformation, and load. The Spline agent is configured in each AWS Glue job to capture lineage and run metrics, and sends such data to a lineage REST API. This backend consists of producer and consumer endpoints, powered by Amazon API Gateway and AWS Lambda functions. The producer endpoints process the incoming lineage objects before storing them in the Neptune database. We use consumer endpoints to extract specific lineage graphs for different visualizations in the frontend application. We perform ad hoc interactive analysis on the graph through Neptune notebooks.
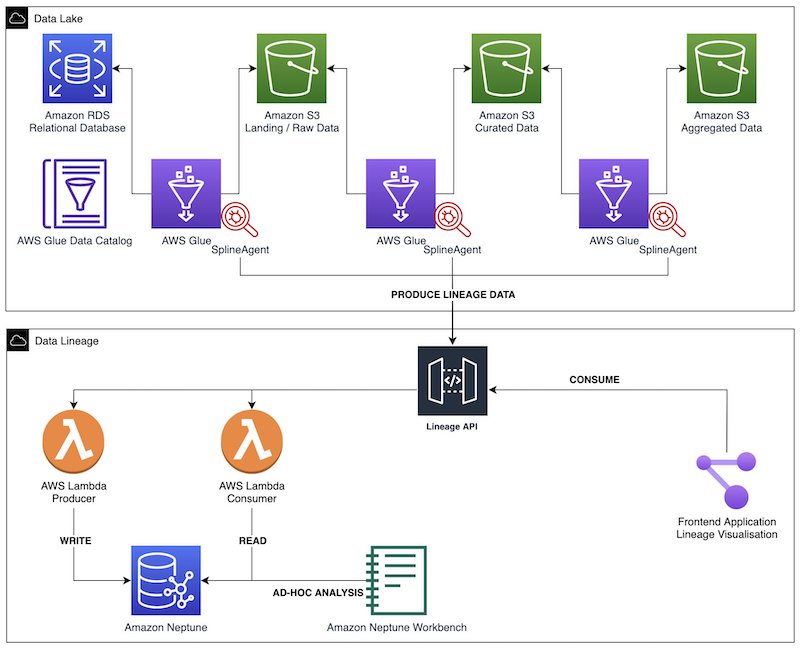
We provide sample code and Terraform deployment scripts on GitHub to quickly deploy this solution to the AWS Cloud.
Data lineage capturing
The Spline agent is an open-source project that can harvest data lineage automatically from Spark jobs at runtime, without the need to modify the existing ETL code. It listens to Spark’s query run events, extracts lineage objects from the job run plans and sends them to a preconfigured backend (such as HTTP endpoints). The agent also automatically collects job run metrics such as the number of output rows. As of this writing, the Spline agent works only with Spark SQL (DataSet/DataFrame APIs) and not with RDDs/DynamicFrames.
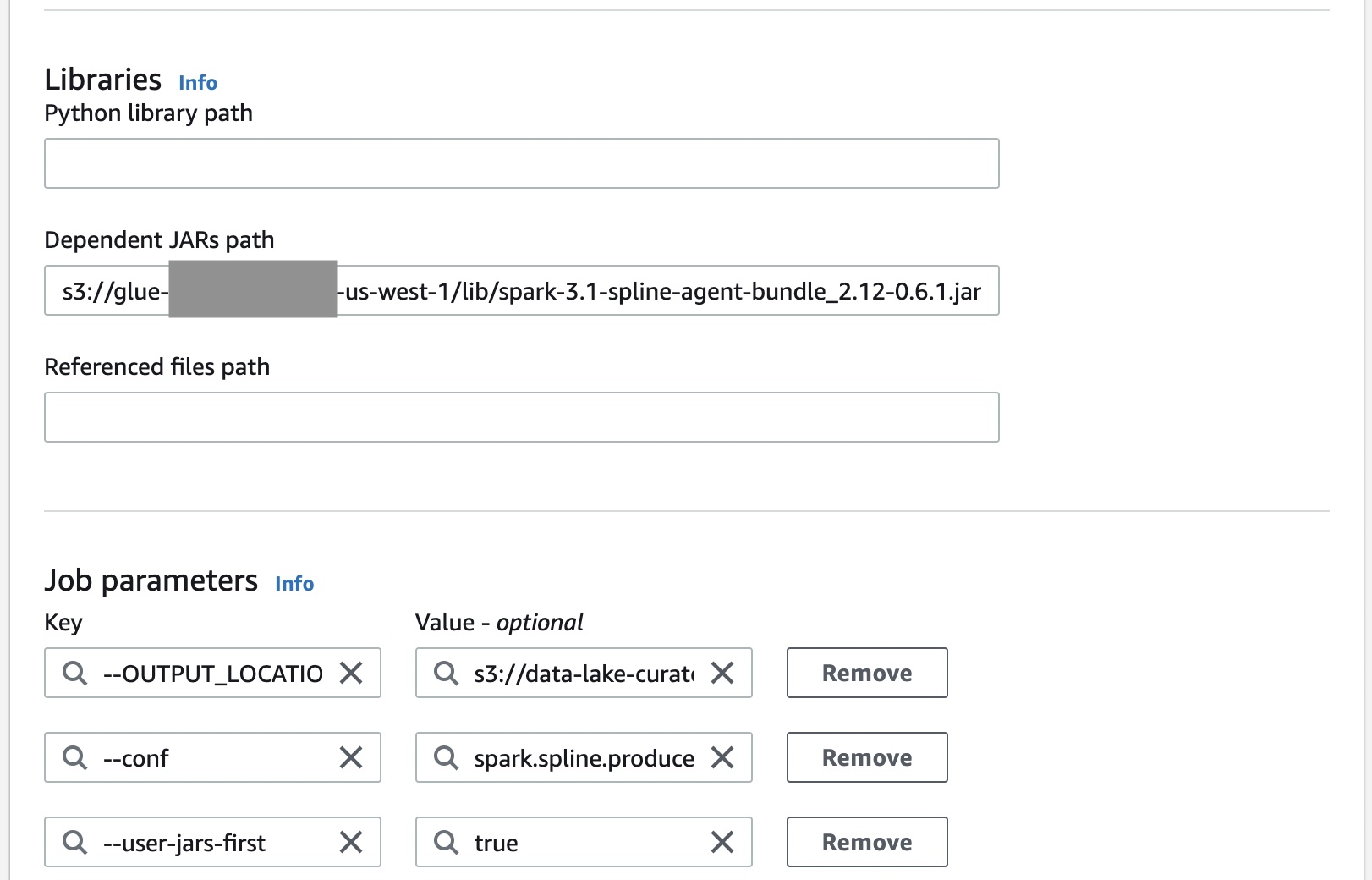
The following screenshot shows how to integrate the Spline agent with AWS Glue Spark jobs. The Spline agent is an uber JAR that needs to be added to the Java classpath. The following configurations are required to set up the Spline agent:
spark.sql.queryExecutionListenersconfiguration is used to register a Spline listener during its initialization.spark.spline.producer.urlspecifies the address of the HTTP server that the Spline agent should send lineage data to.
We build a data lineage API that is compatible with the Spline agent. This API facilitates the insertion of lineage data to Neptune database and graph extraction for visualization. The Spline agent requires three HTTP endpoints:
- /status – For health checks
- /execution-plans – For sending the captured Spark execution plans after the jobs are submitted to run
- /execution-events – For sending the job’s run metrics when the job is complete
We also create additional endpoints to manage various metadata of the data lake, such as the names of the storage layers and dataset classification.
When a Spark SQL statement is run or a DataFrame action is called, Spark’s optimization engine, namely Catalyst, generates different query plans: a logical plan, optimized logical plan and physical plan, which can be inspected using the EXPLAIN statement. In a job run, the Spline agent parses the analyzed logical plan to construct a JSON lineage object. The object consists of the following:
- A unique job run ID
- A reference schema (attribute names and data types)
- A list of operations
- Other system metadata such as Spark version and Spline agent version
A run plan specifies the steps the Spark job performs, from reading data sources, applying different transformations, to finally persisting the job’s output into a storage location.
To sum up, the Spline agent captures not only the metadata of the job (such as job name and run date and time), the input and output tables (such as data format, physical location and schema) but also detailed information about the business logic (SQL-like operations that the job performs, such as join, filter, project and aggregate).
Data modeling and storage
Data modeling starts with the business requirements and use cases and maps those needs into a structure for storing and organizing our data. In data lineage for data lakes, the relationships between data assets (jobs, tables and columns) are as important as the metadata of those. As a result, graph databases are suitable to model such highly connected entities, making it efficient to understand the complex and deep network of relationships within the data.
Neptune is a fast, reliable, fully managed graph database service that makes it easy to build and run applications with highly connected datasets. You can use Neptune to create sophisticated, interactive graph applications that can query billions of relationships in milliseconds. Neptune supports three popular graph query languages: Apache TinkerPop Gremlin and openCypher for property graphs and SPARQL for W3C’s RDF data model. In this solution, we use the property graph’s primitives (including vertices, edges, labels and properties) to model the objects and use the gremlinpython library to interact with the graphs.
The objective of our data model is to provide an abstraction for data assets and their relationships within the data lake. In the producer Lambda functions, we first parse the JSON lineage objects to form logical entities such as jobs, tables and operations before constructing the final graph in Neptune.

The following diagram shows a sample data model used in this solution.

This data model allows us to easily traverse the graph to extract coarse-grained and fine-grained data lineage, as mentioned earlier.
Data lineage visualization
You can extract specific views of the lineage graph from Neptune using the consumer endpoints backed by Lambda functions. Hierarchical views of lineage at different levels make it easy for the end-user to analyze the information.
The following screenshot shows a data lineage view across all jobs and tables.
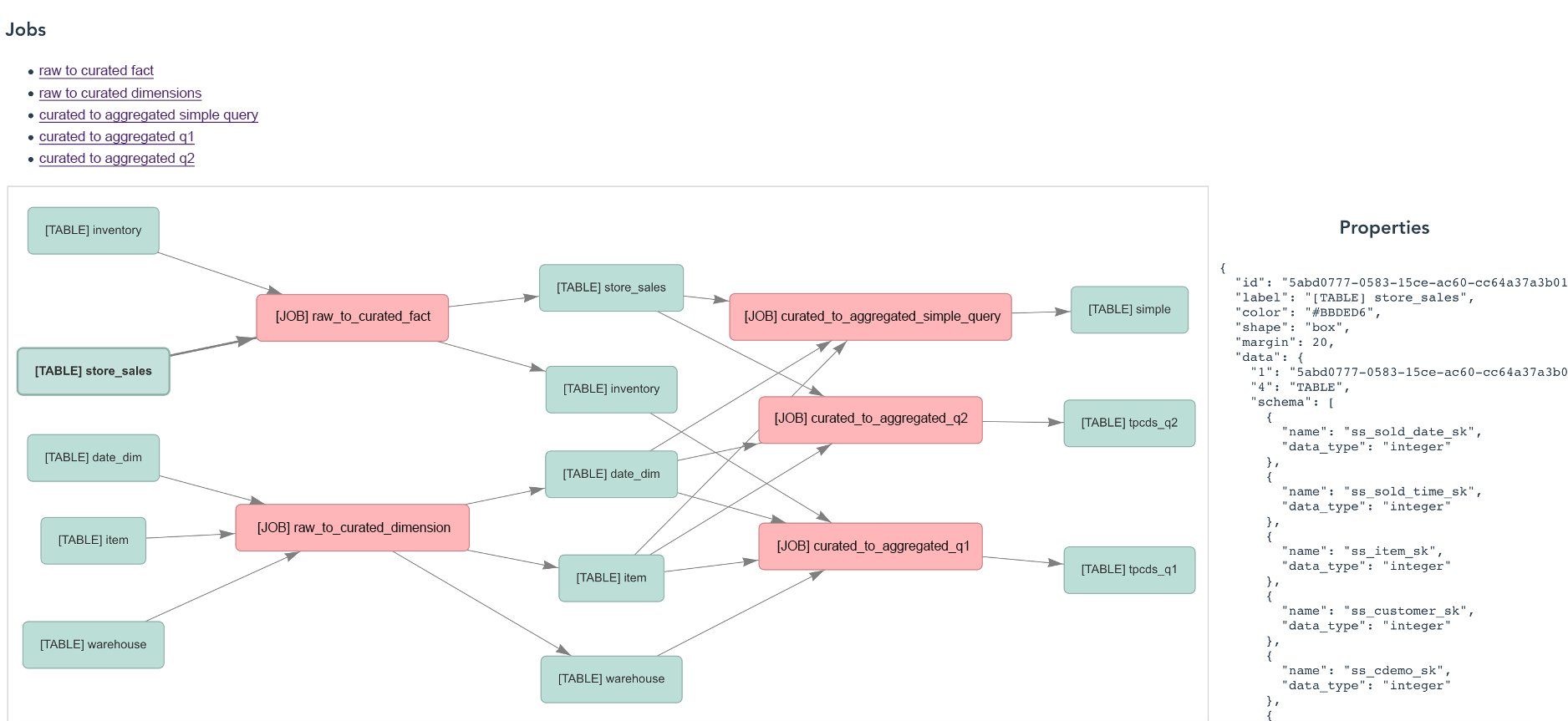
The following screenshot shows a view of a specific job plan.

The following screenshot shows a detailed look into the operations taken by the job.
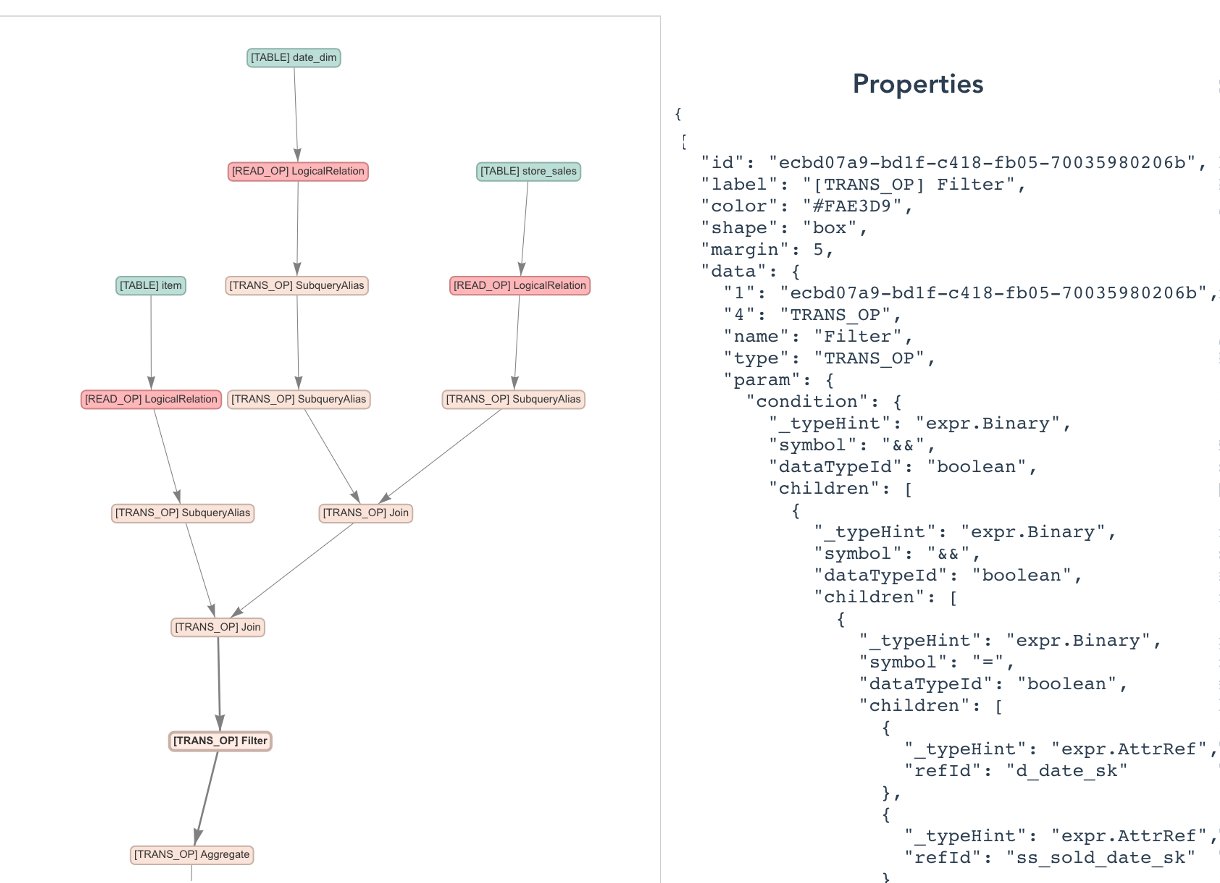
The graphs are visualized using the vis.js network open-source project. You can interact with the graph elements to learn more about the entity’s properties, such as data schema.
Conclusion
In this post, we showed you architectural design options to automatically collect end-to-end data lineage for AWS Glue Spark ETL jobs across a data lake in a multi-account AWS environment using Neptune and the Spline agent. This approach enables searchable metadata, helps to draw insights and achieve an improved organization-wide data lineage posture. The proposed solution uses AWS managed and serverless services, which are scalable and configurable for high availability and performance.
For more information about this solution, see Github. You may modify the code to extend the data model and APIs.
About the Authors
 Khoa Nguyen is a Senior Big Data Architect at Amazon Web Services. He works with large enterprise customers and AWS partners to accelerate customers’ business outcomes by providing expertise in Big Data and AWS services.
Khoa Nguyen is a Senior Big Data Architect at Amazon Web Services. He works with large enterprise customers and AWS partners to accelerate customers’ business outcomes by providing expertise in Big Data and AWS services.
 Krithivasan Balasubramaniyan is a Principal Consultant at Amazon Web Services. He enables global enterprise customers in their digital transformation journey and helps architect cloud native solutions.
Krithivasan Balasubramaniyan is a Principal Consultant at Amazon Web Services. He enables global enterprise customers in their digital transformation journey and helps architect cloud native solutions.
 Rahul Shaurya is a Senior Big Data Architect at Amazon Web Services. He helps and works closely with customers building data platforms and analytical applications on AWS.
Rahul Shaurya is a Senior Big Data Architect at Amazon Web Services. He helps and works closely with customers building data platforms and analytical applications on AWS.