AWS Big Data Blog
Category: AWS Database Migration Service

Real-time CDC from Aurora PostgreSQL to Amazon S3 Tables using Debezium and Firehose
In this post, we show you how to build a CDC pipeline that delivers query-ready Iceberg tables directly. The pipeline captures inserts, updates, and deletes from Aurora PostgreSQL and applies them as row-level operations in Amazon S3 Tables, a capability of Amazon Simple Storage Service (Amazon S3).

Modernize your data warehouse by migrating Oracle Database to Amazon Redshift with Oracle GoldenGate
In this post, we show how to migrate an Oracle data warehouse to Amazon Redshift using Oracle GoldenGate and DMS Schema Conversion, a feature of AWS Database Migration Service (AWS DMS). This approach facilitates minimal business disruption through continuous replication.

Revenue NSW modernises analytics with AWS, enabling unified and scalable data management, processing, and access
Revenue NSW, Australia’s principal revenue management agency, successfully modernized its analytics infrastructure using AWS services. In this blog post, we show how the organization transformed its on-premises data environment into a unified, scalable cloud-based solution using Amazon Redshift, AWS Database Migration Service, Amazon AppFlow, and AWS Glue.

Create an Apache Hudi-based near-real-time transactional data lake using AWS DMS, Amazon Kinesis, AWS Glue streaming ETL, and data visualization using Amazon QuickSight
We recently announced support for streaming extract, transform, and load (ETL) jobs in AWS Glue version 4.0, a new version of AWS Glue that accelerates data integration workloads in AWS. AWS Glue streaming ETL jobs continuously consume data from streaming sources, clean and transform the data in-flight, and make it available for analysis in seconds. AWS also offers a broad selection of services to support your needs. A database replication service such as AWS Database Migration Service (AWS DMS) can replicate the data from your source systems to Amazon Simple Storage Service (Amazon S3), which commonly hosts the storage layer of the data lake. This post demonstrates how to apply CDC changes from Amazon Relational Database Service (Amazon RDS) or other relational databases to an S3 data lake, with flexibility to denormalize, transform, and enrich the data in near-real time.

Migrate your existing SQL-based ETL workload to an AWS serverless ETL infrastructure using AWS Glue
Data has become an integral part of most companies, and the complexity of data processing is increasing rapidly with the exponential growth in the amount and variety of data. Data engineering teams are faced with the following challenges: Manipulating data to make it consumable by business users Building and improving extract, transform, and load (ETL) […]

Convert Oracle XML BLOB data using Amazon EMR and load to Amazon Redshift
In legacy relational database management systems, data is stored in several complex data types, such XML, JSON, BLOB, or CLOB. This data might contain valuable information that is often difficult to transform into insights, so you might be looking for ways to load and use this data in a modern cloud data warehouse such as […]

Stream change data to Amazon Kinesis Data Streams with AWS DMS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. In this post, we discuss how to use AWS Database Migration Service (AWS DMS) native change data capture (CDC) capabilities to stream changes into Amazon Kinesis Data […]

How the Georgia Data Analytics Center built a cloud analytics solution from scratch with the AWS Data Lab
This is a guest post by Kanti Chalasani, Division Director at Georgia Data Analytics Center (GDAC). GDAC is housed within the Georgia Office of Planning and Budget to facilitate governed data sharing between various state agencies and departments. The Office of Planning and Budget (OPB) established the Georgia Data Analytics Center (GDAC) with the intent […]
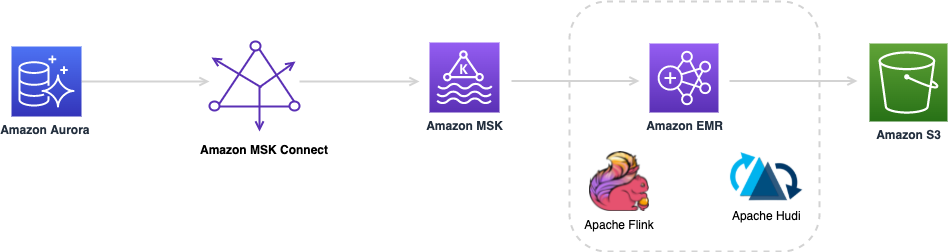
Create a low-latency source-to-data lake pipeline using Amazon MSK Connect, Apache Flink, and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. During the recent years, there has been a shift from monolithic to the microservices architecture. The microservices architecture makes applications easier to scale and quicker to develop, […]

Apply record level changes from relational databases to Amazon S3 data lake using Apache Hudi on Amazon EMR and AWS Database Migration Service
Data lakes give organizations the ability to harness data from multiple sources in less time. Users across different roles are now empowered to collaborate and analyze data in different ways, leading to better, faster decision-making. Amazon Simple Storage Service (Amazon S3) is the highly performant object storage service for structured and unstructured data and the […]