AWS Big Data Blog
Stream change data to Amazon Kinesis Data Streams with AWS DMS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more.
In this post, we discuss how to use AWS Database Migration Service (AWS DMS) native change data capture (CDC) capabilities to stream changes into Amazon Kinesis Data Streams.
AWS DMS is a cloud service that makes it easy to migrate relational databases, data warehouses, NoSQL databases, and other types of data stores. You can use AWS DMS to migrate your data into the AWS Cloud or between combinations of cloud and on-premises setups. AWS DMS also helps you replicate ongoing changes to keep sources and targets in sync.
CDC refers to the process of identifying and capturing changes made to data in a database and then delivering those changes in real time to a downstream system. Capturing every change from transactions in a source database and moving them to the target in real time keeps the systems synchronized, and helps with real-time analytics use cases and zero-downtime database migrations.
Kinesis Data Streams is a fully managed streaming data service. You can continuously add various types of data such as clickstreams, application logs, and social media to a Kinesis stream from hundreds of thousands of sources. Within seconds, the data will be available for your Kinesis applications to read and process from the stream.
AWS DMS can do both replication and migration. Kinesis Data Streams is most valuable in the replication use case because it lets you react to replicated data changes in other integrated AWS systems.
This post is an update to the post Use the AWS Database Migration Service to Stream Change Data to Amazon Kinesis Data Streams. This new post includes steps required to configure AWS DMS and Kinesis Data Streams for a CDC use case. With Kinesis Data Streams as a target for AWS DMS, we make it easier for you to stream, analyze, and store CDC data. AWS DMS uses best practices to automatically collect changes from a data store and stream them to Kinesis Data Streams.
With the addition of Kinesis Data Streams as a target, we’re helping customers build data lakes and perform real-time processing on change data from your data stores. You can use AWS DMS in your data integration pipelines to replicate data in near-real time directly into Kinesis Data Streams. With this approach, you can build a decoupled and eventually consistent view of your database without having to build applications on top of a database, which is expensive. You can refer to the AWS whitepaper AWS Cloud Data Ingestion Patterns and Practices for more details on data ingestion patters.
AWS DMS sources for real-time change data
The following diagram illustrates that AWS DMS can use many of the most popular database engines as a source for data replication to a Kinesis Data Streams target. The database source can be a self-managed engine running on an Amazon Elastic Compute Cloud (Amazon EC2) instance or an on-premises database, or it can be on Amazon Relational Database Service (Amazon RDS), Amazon Aurora, or Amazon DocumentDB (with MongoDB availability).
Kinesis Data Streams can collect, process, and store data streams at any scale in real time and write to AWS Glue, which is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, machine learning, and application development. You can use Amazon EMR for big data processing, Amazon Kinesis Data Analytics to process and analyze streaming data , Amazon Kinesis Data Firehose to run ETL (extract, transform, and load) jobs on streaming data, and AWS Lambda as a serverless compute for further processing, transformation, and delivery of data for consumption.
You can store the data in a data warehouse like Amazon Redshift, which is a cloud-scale data warehouse, and in an Amazon Simple Storage Service (Amazon S3) data lake for consumption. You can use Kinesis Data Firehose to capture the data streams and load the data into S3 buckets for further analytics.
Once the data is available in Kinesis Data Streams targets (as shown in the following diagram), you can visualize it using Amazon QuickSight; run ad hoc queries using Amazon Athena; access, process, and analyze it using an Amazon SageMaker notebook instance; and efficiently query and retrieve structured and semi-structured data from files in Amazon S3 without having to load the data into Amazon Redshift tables using Amazon Redshift Spectrum.

Solution overview
In this post, we describe how to use AWS DMS to load data from a database to Kinesis Data Streams in real time. We use a SQL Server database as example, but other databases like Oracle, Microsoft Azure SQL, PostgreSQL, MySQL, SAP ASE, MongoDB, Amazon DocumentDB, and IBM DB2 also support this configuration.
You can use AWS DMS to capture data changes on the database and then send this data to Kinesis Data Streams. After the streams are ingested in Kinesis Data Streams, they can be consumed by different services like Lambda, Kinesis Data Analytics, Kinesis Data Firehose, and custom consumers using the Kinesis Client Library (KCL) or the AWS SDK.
The following are some use cases that can use AWS DMS and Kinesis Data Streams:
- Triggering real-time event-driven applications – This use case integrates Lambda and Amazon Simple Notification Service (Amazon SNS).
- Simplifying and decoupling applications – For example, moving from monolith to microservices. This solution integrates Lambda and Amazon API Gateway.
- Cache invalidation, and updating or rebuilding indexes – Integrates Amazon OpenSearch Service and Amazon DynamoDB.
- Data integration across multiple heterogeneous systems – This solution sends data to DynamoDB or another data store.
- Aggregating data and pushing it to downstream system – This solution uses Kinesis Data Analytics to analyze and integrate different sources and load the results in another data store.
To facilitate the understanding of the integration between AWS DMS, Kinesis Data Streams, and Kinesis Data Firehose, we have defined a business case that you can solve. In this use case, you are the data engineer of an energy company. This company uses Amazon Relational Database Service (Amazon RDS) to store their end customer information, billing information, and also electric meter and gas usage data. Amazon RDS is their core transaction data store.
You run a batch job weekly to collect all the transactional data and send it to the data lake for reporting, forecasting, and even sending billing information to customers. You also have a trigger-based system to send emails and SMS periodically to the customer about their electricity usage and monthly billing information.
Because the company has millions of customers, processing massive amounts of data every day and sending emails or SMS was slowing down the core transactional system. Additionally, running weekly batch jobs for analytics wasn’t giving accurate and latest results for the forecasting you want to do on customer gas and electricity usage. Initially, your team was considering rebuilding the entire platform and avoiding all those issues, but the core application is complex in design, and running in production for many years and rebuilding the entire platform will take years and cost millions.
So, you took a new approach. Instead of running batch jobs on the core transactional database, you started capturing data changes with AWS DMS and sending that data to Kinesis Data Streams. Then you use Lambda to listen to a particular data stream and generate emails or SMS using Amazon SNS to send to the customer (for example, sending monthly billing information or notifying when their electricity or gas usage is higher than normal). You also use Kinesis Data Firehose to send all transaction data to the data lake, so your company can run forecasting immediately and accurately.
The following diagram illustrates the architecture.

In the following steps, you configure your database to replicate changes to Kinesis Data Streams, using AWS DMS. Additionally, you configure Kinesis Data Firehose to load data from Kinesis Data Streams to Amazon S3.
It’s simple to set up Kinesis Data Streams as a change data target in AWS DMS and start streaming data. For more information, see Using Amazon Kinesis Data Streams as a target for AWS Database Migration Service.
To get started, you first create a Kinesis data stream in Kinesis Data Streams, then an AWS Identity and Access Management (IAM) role with minimal access as described in Prerequisites for using a Kinesis data stream as a target for AWS Database Migration Service. After you define your IAM policy and role, you set up your source and target endpoints and replication instance in AWS DMS. Your source is the database that you want to move data from, and the target is the database that you’re moving data to. In our case, the source database is a SQL Server database on Amazon RDS, and the target is the Kinesis data stream. The replication instance processes the migration tasks and requires access to the source and target endpoints inside your VPC.
A Kinesis delivery stream (created in Kinesis Data Firehose) is used to load the records from the database to the data lake hosted on Amazon S3. Kinesis Data Firehose can load data also to Amazon Redshift, Amazon OpenSearch Service, an HTTP endpoint, Datadog, Dynatrace, LogicMonitor, MongoDB Cloud, New Relic, Splunk, and Sumo Logic.
Configure the source database
For testing purposes, we use the database democustomer, which is hosted on a SQL Server on Amazon RDS. Use the following command and script to create the database and table, and insert 10 records:
To capture the new records added to the table, enable MS-CDC (Microsoft Change Data Capture) using the following commands at the database level (replace SchemaName and TableName). This is required if ongoing replication is configured on the task migration in AWS DMS.
You can use ongoing replication (CDC) for a self-managed SQL Server database on premises or on Amazon Elastic Compute Cloud (Amazon EC2), or a cloud database such as Amazon RDS or an Azure SQL managed instance. SQL Server must be configured for full backups, and you must perform a backup before beginning to replicate data.
For more information, see Using a Microsoft SQL Server database as a source for AWS DMS.
Configure the Kinesis data stream
Next, we configure our Kinesis data stream. For full instructions, see Creating a Stream via the AWS Management Console. Complete the following steps:
- On the Kinesis Data Streams console, choose Create data stream.
- For Data stream name¸ enter a name.
- For Capacity mode, select On-demand.When you choose on-demand capacity mode, Kinesis Data Streams instantly accommodates your workloads as they ramp up or down. For more information, refer to Choosing the Data Stream Capacity Mode.

- Choose Create data stream.
- When the data stream is active, copy the ARN.

Configure the IAM policy and role
Next, you configure your IAM policy and role.
- On the IAM console, choose Policies in the navigation pane.
- Choose Create policy.
- Select JSON and use the following policy as a template, replacing the data stream ARN:
- In the navigation pane, choose Roles.
- Choose Create role.
- Select AWS DMS, then choose Next: Permissions.
- Select the policy you created.
- Assign a role name and then choose Create role.
Configure the Kinesis delivery stream
We use a Kinesis delivery stream to load the information from the Kinesis data stream to Amazon S3. To configure the delivery stream, complete the following steps:
- On the Kinesis console, choose Delivery streams.
- Choose Create delivery stream.
- For Source, choose Amazon Kinesis Data Streams.
- For Destination, choose Amazon S3.
- For Kinesis data stream, enter the ARN of the data stream.
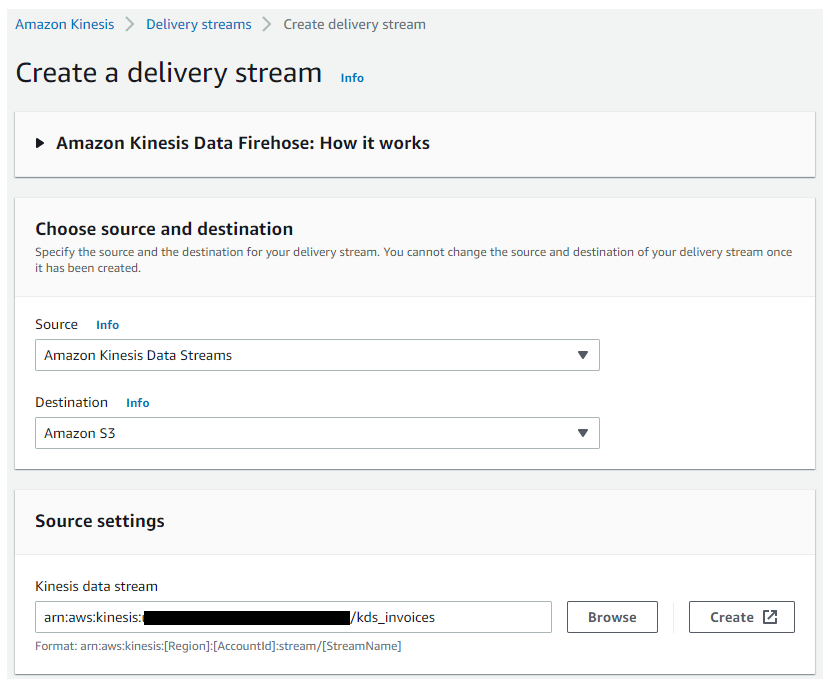
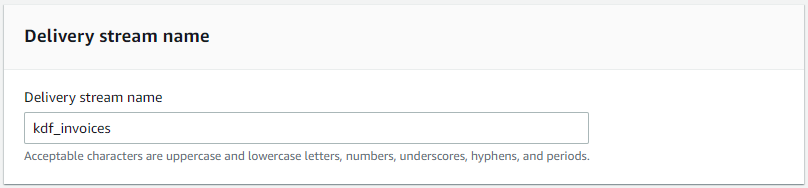
- For Delivery stream name, enter a name.
- Leave the transform and convert options at their defaults.

- Provide the destination bucket and specify the bucket prefixes for the events and errors.

- Under Buffer hints, compression and encryption, change the buffer size to 1 MB and buffer interval to 60 seconds.

- Leave the other configurations at their defaults.
Configure AWS DMS
We use an AWS DMS instance to connect to the SQL Server database and then replicate the table and future transactions to a Kinesis data stream. In this section, we create a replication instance, source endpoint, target endpoint, and migration task. For more information about endpoints, refer to Creating source and target endpoints.
- Create a replication instance in a VPC with connectivity to the SQL Server database and associate a security group with enough permissions to access to the database.
- On the AWS DMS console, choose Endpoints in the navigation pane.
- Choose Create endpoint.
- Select Source endpoint.

- For Endpoint identifier, enter a label for the endpoint.
- For Source engine, choose Microsoft SQL Server.
- For Access to endpoint database, select Provide access information manually.
- Enter the endpoint database information.

- Test the connectivity to the source endpoint.
Now we create the target endpoint. - On the AWS DMS console, choose Endpoints in the navigation pane.
- Choose Create endpoint.
- Select Target endpoint.

- For Endpoint identifier, enter a label for the endpoint.
- For Target engine, choose Amazon Kinesis.
- Provide the AWS DMS service role ARN and the data stream ARN.

- Test the connectivity to the target endpoint.

The final step is to create a database migration task. This task replicates the existing data from the SQL Server table to the data stream and replicates the ongoing changes. For more information, see Creating a task. - On the AWS DMS console, choose Database migration tasks.
- Choose Create task.
- For Task identifier, enter a name for your task.
- For Replication instance, choose your instance.
- Choose the source and target database endpoints you created.
- For Migration type, choose Migrate existing data and replicate ongoing changes.

- In Task settings, use the default settings.
- In Table mappings, add a new selection rule and specify the schema and table name of the SQL Server database. In this case, our schema name is
dboand the table name isinvoices. - For Action, choose Include.

When the task is ready, the migration starts.

After the data has been loaded, the table statistics are updated and you can see the 10 records created initially.

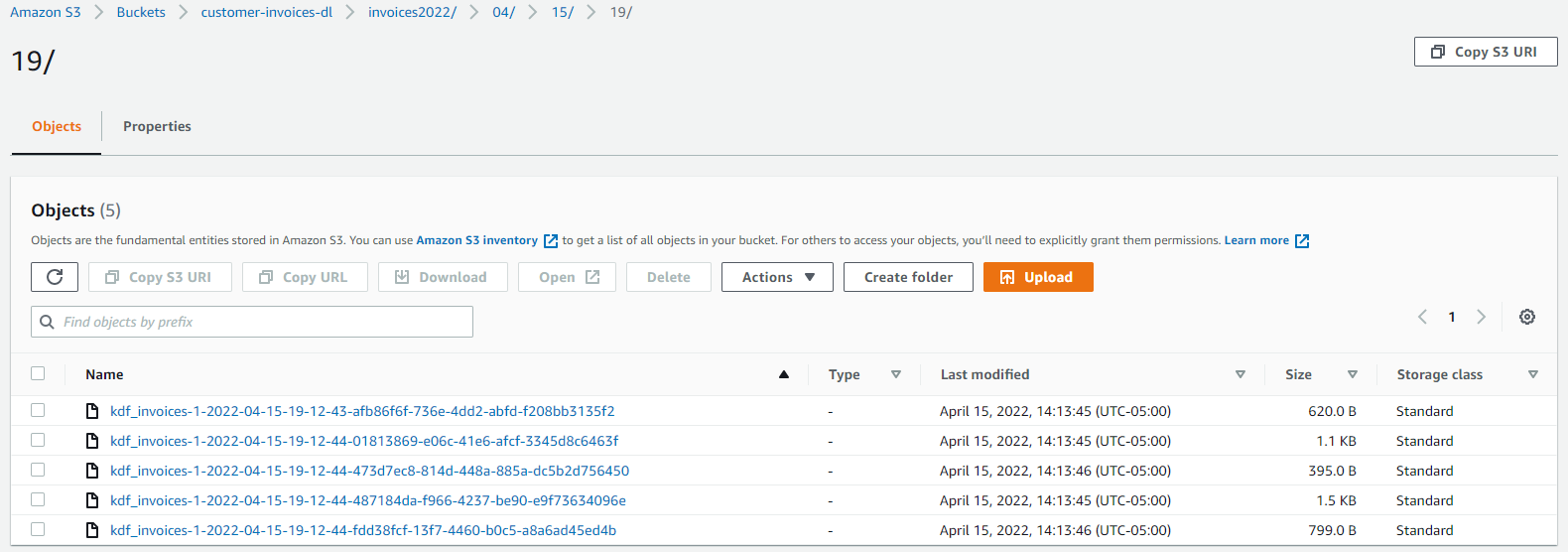
As the Kinesis delivery stream reads the data from Kinesis Data Streams and loads it in Amazon S3, the records are available in the bucket you defined previously.
To check that AWS DMS ongoing replication and CDC are working, use this script to add 1,000 records to the table.
You can see 1,000 inserts on the Table statistics tab for the database migration task.

After about 1 minute, you can see the records in the S3 bucket.

At this point the replication has been activated, and a Lambda function can start consuming the data streams to send emails SMS to the customers through Amazon SNS. More information, refer to Using AWS Lambda with Amazon Kinesis.
Conclusion
With Kinesis Data Streams as an AWS DMS target, you now have a powerful way to stream change data from a database directly into a Kinesis data stream. You can use this method to stream change data from any sources supported by AWS DMS to perform real-time data processing. Happy streaming!
If you have any questions or suggestions, please leave a comment.
About the Authors
 Luis Eduardo Torres is a Solutions Architect at AWS based in Bogotá, Colombia. He helps companies to build their business using the AWS cloud platform. He has a great interest in Analytics and has been leading the Analytics track of AWS Podcast in Spanish.
Luis Eduardo Torres is a Solutions Architect at AWS based in Bogotá, Colombia. He helps companies to build their business using the AWS cloud platform. He has a great interest in Analytics and has been leading the Analytics track of AWS Podcast in Spanish.
 Sukhomoy Basak is a Solutions Architect at Amazon Web Services, with a passion for Data and Analytics solutions. Sukhomoy works with enterprise customers to help them architect, build, and scale applications to achieve their business outcomes.
Sukhomoy Basak is a Solutions Architect at Amazon Web Services, with a passion for Data and Analytics solutions. Sukhomoy works with enterprise customers to help them architect, build, and scale applications to achieve their business outcomes.